简介
原来scrapy的Scheduler维护的是本机的任务队列(存放Request对象及其回调函数等信息)+本机的去重队列(存放访问过的url地址)
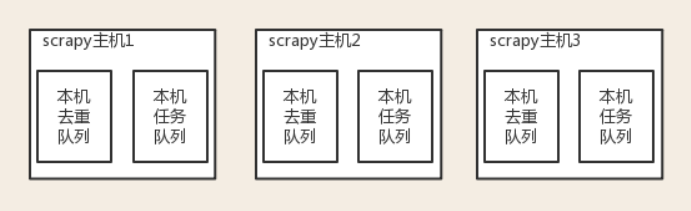
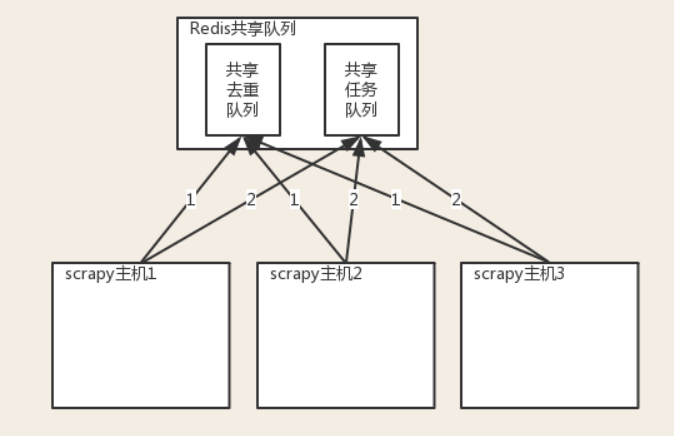
分布式爬取的关键:
1、共享队列
2、重写Scheduler,让其无论是去重还是任务都去访问共享队列
3、为Scheduler定制去重规则(利用redis的集合类型)
一、在settings.py中配置链接Redis
REDIS_HOST = 'localhost' # 主机名
REDIS_PORT = 6379 # 端口
REDIS_URL = 'redis://user:pass@hostname:9001' # 连接URL(优先于以上配置)
REDIS_PARAMS = {} # Redis连接参数
REDIS_PARAMS['redis_cls'] = 'myproject.RedisClient' # 指定连接Redis的Python模块
REDIS_ENCODING = "utf-8" # redis编码类型
二、让scrapy使用共享的去重队列
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
#使用scrapy-redis提供的去重功能,查看源码会发现是基于Redis的集合实现的
三、需要指定Redis中集合的key名
key=存放不重复Request字符串的集合
DUPEFILTER_KEY = 'dupefilter:%(timestamp)s'
四、settings.py配置
# Enables scheduling storing requests queue in redis.
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 调度器将不重复的任务用pickle序列化后放入共享任务队列,默认使用优先级队列(默认),其他:PriorityQueue(有序集合),FifoQueue(列表)、LifoQueue(列表)
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue'
# 对保存到redis中的request对象进行序列化,默认使用pickle
SCHEDULER_SERIALIZER = "scrapy_redis.picklecompat"
# 调度器中请求任务序列化后存放在redis中的key
SCHEDULER_QUEUE_KEY = '%(spider)s:requests'
# 是否在关闭时候保留原来的调度器和去重记录,True=保留,False=清空
SCHEDULER_PERSIST = True
# 是否在开始之前清空 调度器和去重记录,True=清空,False=不清空
SCHEDULER_FLUSH_ON_START = False
# 去调度器中获取数据时,如果为空,最多等待时间(最后没数据,未获取到)。如果没有则立刻返回会造成空循环次数过多,cpu占用率飙升
SCHEDULER_IDLE_BEFORE_CLOSE = 10
# 去重规则,在redis中保存时对应的key
SCHEDULER_DUPEFILTER_KEY = '%(spider)s:dupefilter'
# 去重规则对应处理的类,将任务request_fingerprint(request)得到的字符串放入去重队列
SCHEDULER_DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter'
小结
# 1 pip3 install scrapy-redis
# 2 原来继承Spider,现在继承RedisSpider
# 3 不能写start_urls = ['https:/www.cnblogs.com/']
# 4 需要写redis_key = 'myspider:start_urls'
# 5 setting中配置:
# redis的连接
REDIS_HOST = 'localhost' # 主机名
REDIS_PORT = 6379 # 端口
# 使用scrapy-redis的去重
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 使用scrapy-redis的Scheduler
# 分布式爬虫的配置
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 持久化的可以配置,也可以不配置
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 299
}
# 6 现在要让爬虫运行起来,需要去redis中以myspider:start_urls为key,插入一个起始地址lpush myspider:start_urls https://www.cnblogs.com/