skearn-learn 是一个机器学习的库, 可以省略很多自己写的步骤
一:导入包和数据集
import matplotlib.pyplot as plt #导入画图包
import numpy as np #数据包
from sklearn import linear_model #导入sklearn 机器学习线性回归包
from sklearn.metrics import mean_squared_error, r2_score #机器学习检测包
展示元数据集
def loadDataSet(fileName): numFeat = len(open(fileName).readline().split(' ')) - 1 xArr = []; yArr = [] # print(numFeat) fr = open(fileName) # print(fr) for line in fr.readlines(): # print(line) lineArr =[] curLine = line.strip().split(' ') for i in range(numFeat): lineArr.append(float(curLine[i])) xArr.append(lineArr) yArr.append(float(curLine[-1])) return xArr, yArr xArr, yArr = loadDataSet('ex0.txt')
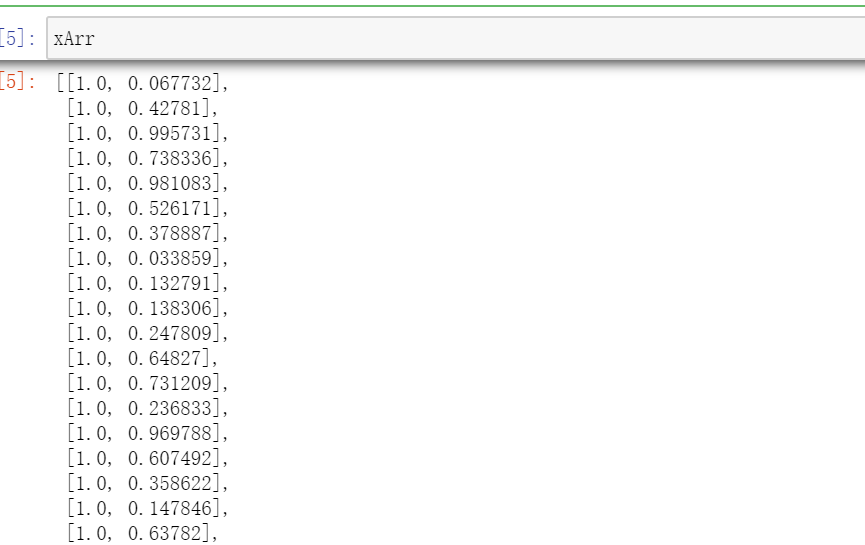
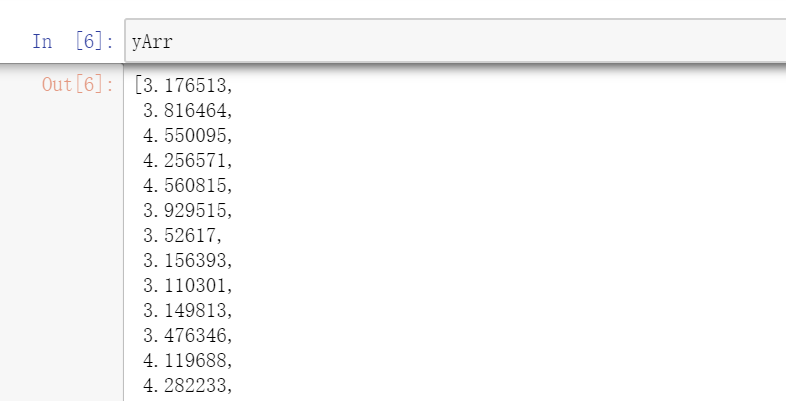
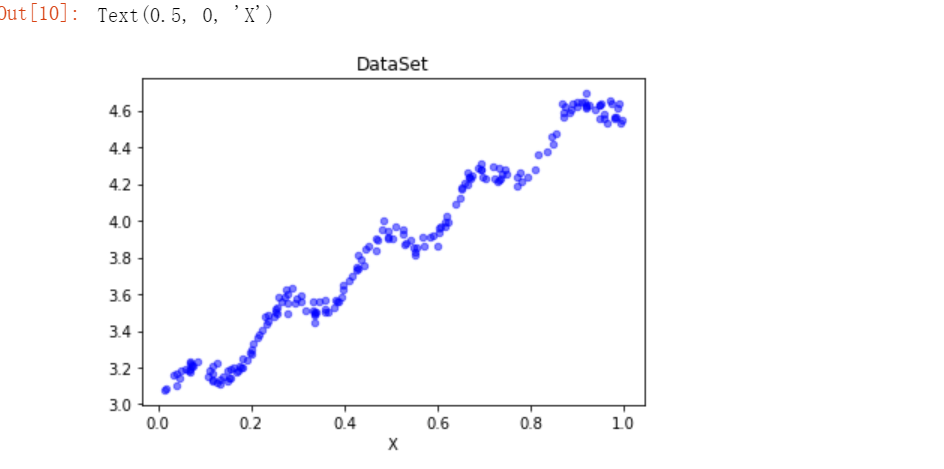
打印元数据集坐标图
n = len(xArr) #数据个数 xcord = []; ycord = [] #样本点 for i in range(n): xcord.append(xArr[i][1]); ycord.append(yArr[i]) #样本点 fig = plt.figure() ax = fig.add_subplot(111) #添加subplot ax.scatter(xcord, ycord, s = 20, c = 'blue',alpha = .5) #绘制样本点 plt.title('DataSet') #绘制title plt.xlabel('X')
利用机器学习包进行模型训练
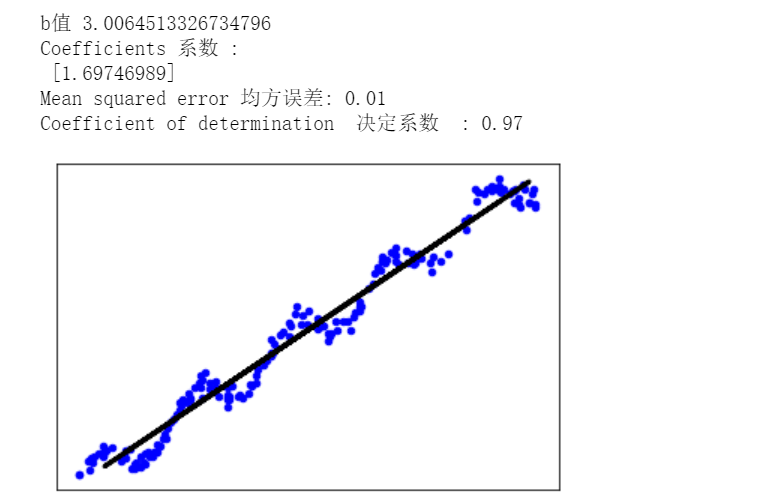
reg = linear_model.LinearRegression() #创建线性回归对象 xArr_x_train =xArr[:-20] #取 x后20为训练集 xArr_x_text =xArr[-20:] #取 x前20为测试集 yArr_y_train =yArr[:-20] #同理 yArr_y_text =yArr[-20:]#同理 xMat = np.mat(xArr_x_train) #创建xMat矩阵, regr.fit(xMat[:,1], yArr_y_train) #线性回归训练, 取x的1列特征内容 xmattext =np.mat(xArr_x_text) #创建xmattext 矩阵 yArr_y_pred = regr.predict(xmattext[:,1]) #验证训练结果 获取训练y_pred print('b值',regr.intercept_) print('Coefficients 系数 : ', regr.coef_) print('Mean squared error 均方误差: %.2f' % mean_squared_error(yArr_y_text, yArr_y_pred)) print('Coefficient of determination 决定系数 : %.2f' % r2_score(yArr_y_text, yArr_y_pred)) plt.scatter(xMat[:,1].flatten().A[0], yMat.flatten().A[0] , s = 20 ,color='blue') #打印撒点图 plt.plot(xmattext[:,1].flatten().A[0], ymattext.flatten().A[0] , color='black', linewidth=3) #打印线性图 plt.xticks(()) plt.yticks(()) plt.show()
用到的知识点
参数:
fit_intercept:一个布尔值,指定是否需要计算b值。如果为False,那么不计算b值。
normalize: 一个布尔值。如果为True,那么训练样本在回归之前会被归一化。
copy_x: 一个布尔值。如果为True,则会复制X。
n_jobs: 一个正数。任务并行时指定的CPU数量。如果为-1,则使用所有可用的CPU。
coef_: 权重向量。
intercept_: b值。
fit(X, y[ ,sample_weight]): 训练模型。
predict(X): 用模型进行预测,返回预测值。