数据分析的基础知识内容
什么是监督学习
在监督学习中,计算机通过示例学习。它从过去的数据中学习,并将学习的结果应用到当前的数据中,以预测未来的事件。在这种情况下,输入和期望的输出数据都有助于预测未来事件
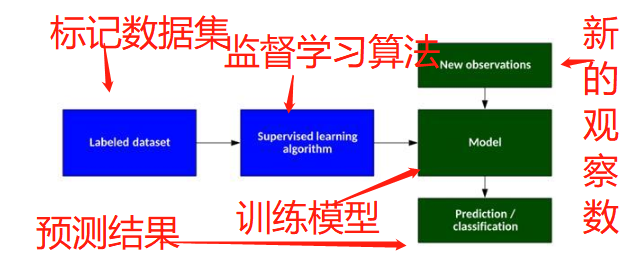
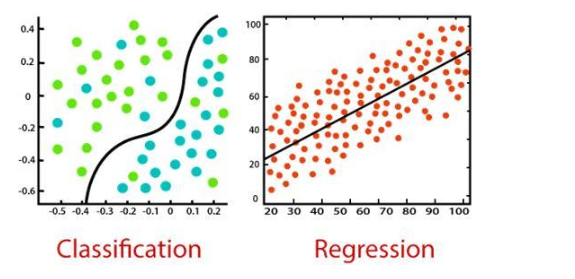
二:所有监督学习算法本质上都是复杂算法,分为分类或回归模型。
1.回归模型—回归模型用于输出变量为实际值的问题,
例如单一的数字、美元、薪水、体重或压力。它最常用于根据先前的观测数据来预测数值。
一些比较常见的回归算法包括线性回归、逻辑回归、多项式回归和脊回归。
2.分类模型—分类模型用于可以对输出变量进行分类,
例如“是”或“否”、“通过”或“失败”。分类模型用于预测数据的类别。
现实生活中的例子包括垃圾邮件检测、情绪分析、考试记分卡预测等。
什么是无监督学习?
无监督学习是训练机器使用既未分类也未标记的数据的方法。
这意味着无法提供训练数据,机器只能自行学习。机器必须能够对数据进行分类,而无需事先提供任何有关数据的信息。
其理念是先让计算机与大量变化的数据接触,并允许它从这些数据中学习,以提供以前未知的见解,
并识别隐藏的模式。
因此,无监督学习算法不一定有明确的结果。相反,它确定了与给定数据集不同或有趣之处。
计算机需要编程才能自学。计算机需要从结构化和非结构化数据中理解和提供见解。
无监督学习的准确说明
无监督机器学习分类
1.聚类是最常见的无监督学习方法之一。聚类的方法包括将未标记的数据组织成类似的组,称为聚类。因此,聚类是相似数据项的集合。此处的主要目标是发现数据点中的相似性,并将相似的数据点分组到一个聚类中。
2.异常检测是识别与大多数数据显著不同的特殊项、事件或观测值的方法。通常在数据中寻找异常或异常值的原因在于它们是可疑的。异常检测常用于银行欺诈和医疗差错检测。
简单一句话就是
监督(supervised)=标签(label),是否有监督,就是输入数据(input)是否有标签,有标签 则为有监督学习,没标签则为无监督学习。至于半监督学习,就是一半(一点点)数据有标签,一 半(极其巨大)数据没标签。
例如学数学,小学老师会先给大量训练,让人学会解题方法。之后面对考试的时候出现的绝对不同 的题目,也能回答。
a) 监督学习是最常见的一种机器学。
它的训练数据是有标签的,训练目标是能够给新数据(测试 数据)以正确的标签。 例如,想让AI知道什么是猫什么是狗,一开始我们先将一些猫的图片和狗的图片(带标签)一起进 行训练,学习模型不断捕捉这些图片与标签间的联系进行自我调整和完善,然后我们给一些不带标 签的新图片,让该AI来猜猜这些图片是猫还是狗。 经典的算法:支持向量机、线性判别、决策树、朴素贝叶斯
b) 无监督学习常常被用于数据挖掘。
用于在大量无标签数据中发现些什么。它的训练数据是无标签 的,训练目标是能对观察值进行分类或者区分等。相对于监督学习,无监督学习使用的是没有标签 的数据。机器会主动学习数据的特征,并将它们分为若干类别,相当于形成「未知的标签」。 非监督性学习是只给特征,没有给标签,就是高考前的一些模拟试卷,是没有标准答案的,也就是 没有参照是对还是错,但是我们还是可以根据这些问题之间的联系将语文、数学、英语分开。
--参考知乎https://www.zhihu.com/question/27138263/answer/635004780
--参考西瓜书机器学习
--参考csdn 部分资料