前情提要:
补充知识点:
ua请求头库的使用
安装: pip install fake-useragent 使用: from fake_useragent import UserAgent ua = UserAgent() 调用指定ua: ua.ie Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US) 随机ua: ua.random
scrapy 的中间件使用
一:
下载中间件的使用
-:作用:批量拦截请求头和响应
-:拦截请求:
1:串改请求头信息(User-Agent)
2:设置相关请求对象的代理ip(process_exception)
二:
爬虫中间件的使用
一:下载中间件的使用
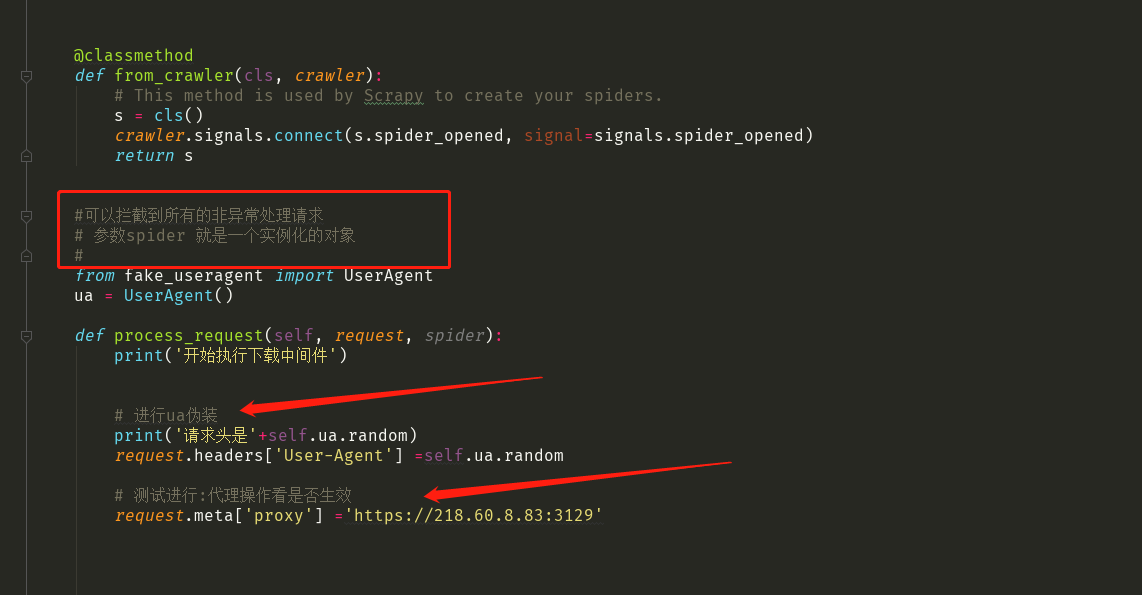
1 : 中间件代码
class MiddleproDownloaderMiddleware(object): # Not all methods need to be defined. If a method is not defined, # scrapy acts as if the downloader middleware does not modify the # passed objects. @classmethod def from_crawler(cls, crawler): # This method is used by Scrapy to create your spiders. s = cls() crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) return s #可以拦截到所有的非异常处理请求 # 参数spider 就是一个实例化的对象 # from fake_useragent import UserAgent ua = UserAgent() def process_request(self, request, spider): print('开始执行下载中间件') # 进行ua伪装 print('请求头是'+self.ua.random) request.headers['User-Agent'] =self.ua.random # 测试进行:代理操作看是否生效 request.meta['proxy'] ='https://218.60.8.83:3129' # Called for each request that goes through the downloader # middleware. # Must either: # - return None: continue processing this request # - or return a Response object # - or return a Request object # - or raise IgnoreRequest: process_exception() methods of # installed downloader middleware will be called return None # 拦截所有的响应 def process_response(self, request, response, spider): # Called with the response returned from the downloader. # Must either; # - return a Response object # - return a Request object # - or raise IgnoreRequest return response # 拦截所有的异常请求对象 def process_exception(self, request, exception, spider): # Called when a download handler or a process_request() # (from other downloader middleware) raises an exception. # Must either: # - return None: continue processing this exception # - return a Response object: stops process_exception() chain # - return a Request object: stops process_exception() chain
#更改内容后重新参与调度
return request
#写日志 def spider_opened(self, spider): spider.logger.info('Spider opened: %s' % spider.name)
2:解析
2->1 :拦截正常的请求
2-2>拦截异常请求

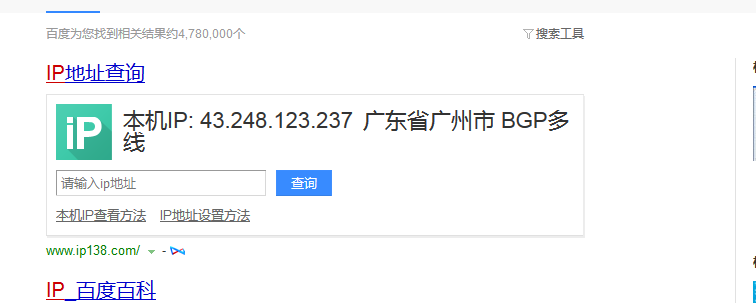
3测试结果
ip已经被替换成代理ip
且请求头已经替换成随机请求头

整理:
- 在scrapy 中如和给所有的请求对象尽可能多的设置不一样的请求载体进行身份标识
- UA池,process_request(request)
- 在scrapy中如何给发生异常的请求设置代理ip
- ip池 ,process_exception(request,response,spider):request.meta['proxy']='https/http新的ip'
-将异常的请求拦截到后,通过代理ip相关的操作 ,就可以将异常的请求变成非异常的请求,
对改请求进行重新的请求发送: return requset
- 阐述下载中间件的作用以及其最重要的方法,
- process_request:拦截所有的非异常的作用
- process_respose: 拦截所有响应对象
- process_execption: 拦截发生异常的响应对象,并对其进行处理,让其变成正常的请求对象
- 简述 scrapy 中什么时候需要使用selenim 及其scrapy应用selenium 的编码流程
- 实例化浏览器对象: spider 的init 方法
- 编写需要浏览器自动化的操作(中间件,process_resonse)
- 关闭浏览器(spider的closed方法,进行关闭操作)