单例模式:
单例模式是一种常用的软件设计模式。在它的核心结构中只包含一个被称为单例类的特殊类。通过单例模式可以保证系统中一个类只有一个实例而且该实例易于外界访问,从而方便对实例个数的控制并节约系统资源。如果希望在系统中某个类的对象只能存在一个,单例模式是最好的解决方案。
__new__()在__init__()之前被调用,用于生成实例对象。利用这个方法和类的属性的特点可以实现设计模式的单例模式。单例模式是指创建唯一对象,单例模式设计的类只能实例 这个绝对常考啊.绝对要记住1~2个方法,当时面试官是让手写的.
class Borg(object):
_static ={}
def __new__(cls,*args,**kwargs):
ob =super(Borg,cls).__new__(cls,*args,kwargs)
ob.__dict__ =cls._static
return =ob
几种常见的单例模式


1 使用__new__方法 class Singleton(object): def __new__(cls, *args, **kw): if not hasattr(cls, '_instance'): orig = super(Singleton, cls) cls._instance = orig.__new__(cls, *args, **kw) return cls._instance class MyClass(Singleton): a = 1 2 共享属性 创建实例时把所有实例的__dict__指向同一个字典,这样它们具有相同的属性和方法. class Borg(object): _state = {} def __new__(cls, *args, **kw): ob = super(Borg, cls).__new__(cls, *args, **kw) ob.__dict__ = cls._state return ob class MyClass2(Borg): a = 1 3 装饰器版本 def singleton(cls): instances = {} def getinstance(*args, **kw): if cls not in instances: instances[cls] = cls(*args, **kw) return instances[cls] return getinstance @singleton class MyClass: ... 4 import方法 作为python的模块是天然的单例模式 # mysingleton.py class My_Singleton(object): def foo(self): pass my_singleton = My_Singleton() # to use from mysingleton import my_singleton my_singleton.foo()
闭包:
def func1(m):
def inner(m):
print(m)
return inner
语法糖装饰器
def warpper(func)
def inner(*args,**kwargs):
re = func(*args,**kwargs)
return re
return inner
调用
@warpper
def 函数(参数)
二分法:
def func(list,num): min =0 # 起始索引 max =len(list)-1 #最大索引 if num in list: while True: center =int((min+max)/2 )# 获取中间的值 # print(center) if list[center]>num: max=center-1 # elif list[center]<num: min =center+1 elif list[center]==num: print("位置在",center) return list[center] list =[1, 6, 9, 15, 26, 38, 49, 57, 63, 77, 81, 93] func(list,15)
简述代码跑出以下异常的原因是什么
IndexError 序列中没有此索引(index)
AttributeError 对象没有这个属性
AssertionError 断言语句失败
NotImplementedError 尚未实现的方法
StopIteration 迭代器没有更多的值
TypeError 对类型无效的操作
IndentationError 缩进错误
简述你对GIL的理解
GIL的全称是Global Interpreter Lock(全局解释器锁),来源是python设计之初的考虑,为了数据安全所做的决定。 每个CPU在同一时间只能执行一个线程 在单核CPU下的多线程其实都只是并发,不是并行,并发和并行从宏观上来讲都是同时处理多路请求的概念。 但并发和并行又有区别,并行是指两个或者多个事件在同一时刻发生;而并发是指两个或多个事件在同一时间间隔内发生。 在Python多线程下,每个线程的执行方式: 1、获取GIL 2、执行代码直到sleep或者是python虚拟机将其挂起。 3、释放GIL 可见,某个线程想要执行,必须先拿到GIL,我们可以把GIL看作是“通行证”,并且在一个python进程中,GIL只有一个。 拿不到通行证的线程,就不允许进入CPU执行。 在Python2.x里,GIL的释放逻辑是当前线程遇见IO操作或者ticks计数达到100(ticks可以看作是Python自身的一个计数器, 专门做用于GIL,每次释放后归零,这个计数可以通过 sys.setcheckinterval 来调整),进行释放。 而每次释放GIL锁,线程进行锁竞争、切换线程,会消耗资源。并且由于GIL锁存在, python里一个进程永远只能同时执行一个线程(拿到GIL的线程才能执行)。 IO密集型代码(文件处理、网络爬虫等),多线程能够有效提升效率(单线程下有IO操作会进行IO等待, 造成不必要的时间浪费,而开启多线程能在线程A等待时,自动切换到线程B, 可以不浪费CPU的资源,从而能提升程序执行效率),所以多线程对IO密集型代码比较友好。 更多参考资料: http://cenalulu.github.io/python/gil-in-python
copy和deepcopy的区别是什么
—–我们寻常意义的复制就是深复制,即将被复制对象完全再复制一遍作为独立的新个体单独存在。所以改变原有被复制对象不会对已经复制出来的新对象产生影响。 —–而浅复制并不会产生一个独立的对象单独存在,他只是将原有的数据块打上一个新标签,所以当其中一个标签被改变的时候,数据块就会发生变化,另一个标签也会随之改变。这就和我们寻常意义上的复制有所不同了。 对于简单的 object,用 shallow copy 和 deep copy 没区别 复杂的 object, 如 list 中套着 list 的情况,shallow copy 中的 子list,并未从原 object 真的「独立」出来。也就是说,如果你改变原 object 的子 list 中的一个元素,你的 copy 就会跟着一起变。这跟我们直觉上对「复制」的理解不同。 代码解释

简述多线程、多进程、协程之间的区别与联系
概念:
进程:
进程是具有一定独立功能的程序关于某个数据集合上的一次运行活动,
进程是系统进行资源分配和调度的一个独立单位。每个进程都有自己的独立内存空间,
不同进程通过进程间通信来通信。由于进程比较重量,占据独立的内存,
所以上下文进程间的切换开销(栈、寄存器、虚拟内存、文件句柄等)比较大,但相对比较稳定安全。
线程:
线程是进程的一个实体,是CPU调度和分派的基本单位,
它是比进程更小的能独立运行的基本单位.
线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计数器,一组寄存器和栈),
但是它可与同属一个进程的其他的线程共享进程所拥有的全部资源。
线程间通信主要通过共享内存,上下文切换很快,资源开销较少,但相比进程不够稳定容易丢失数据。
协程:
协程是一种用户态的轻量级线程,协程的调度完全由用户控制。
协程拥有自己的寄存器上下文和栈。
协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,
直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快。
区别:
进程与线程比较:
线程是指进程内的一个执行单元,也是进程内的可调度实体。线程与进程的区别:
1) 地址空间:线程是进程内的一个执行单元,进程内至少有一个线程,它们共享进程的地址空间,
而进程有自己独立的地址空间
2) 资源拥有:进程是资源分配和拥有的单位,同一个进程内的线程共享进程的资源
3) 线程是处理器调度的基本单位,但进程不是
4) 二者均可并发执行
5) 每个独立的线程有一个程序运行的入口、顺序执行序列和程序的出口,
但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制
协程与线程进行比较:
1) 一个线程可以多个协程,一个进程也可以单独拥有多个协程,这样python中则能使用多核CPU。
2) 线程进程都是同步机制,而协程则是异步
3) 协程能保留上一次调用时的状态,每次过程重入时,就相当于进入上一次调用的状态
代码中经常遇到的*args, **kwargs含义及用法。
在函数定义中使用args和*kwargs传递可变长参数
*args用来将参数打包成tuple给函数体调用
**kwargs 打包关键字参数成dict给函数体调用
列举一些你知道的HTTP Header 及其功能。
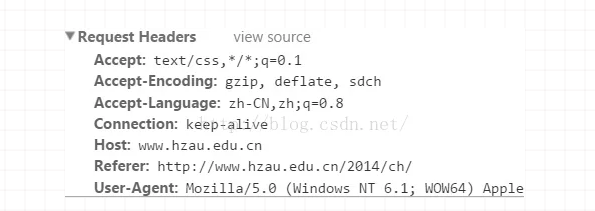
Accept
作用: 浏览器端可以接受的媒体类型,
例如: Accept: text/html 代表浏览器可以接受服务器回发的类型为 text/html 也就是我们常说的html文档,
如果服务器无法返回text/html类型的数据,服务器应该返回一个406错误(non acceptable)
通配符 * 代表任意类型
例如 Accept: / 代表浏览器可以处理所有类型,(一般浏览器发给服务器都是发这个)
Accept-Encoding:
作用: 浏览器申明自己接收的编码方法,通常指定压缩方法,是否支持压缩,支持什么压缩方法(gzip,deflate),(注意:这不是只字符编码);
例如: Accept-Encoding: zh-CN,zh;q=0.8
Accept-Language
作用: 浏览器申明自己接收的语言。
语言跟字符集的区别:中文是语言,中文有多种字符集,比如big5,gb2312,gbk等等;
例如: Accept-Language: en-us
Connection
例如: Connection: keep-alive 当一个网页打开完成后,客户端和服务器之间用于传输HTTP数据的TCP连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接
例如: Connection: close 代表一个Request完成后,客户端和服务器之间用于传输HTTP数据的TCP连接会关闭, 当客户端再次发送Request,需要重新建立TCP连接。
Host(发送请求时,该报头域是必需的)
作用: 请求报头域主要用于指定被请求资源的Internet主机和端口号,它通常从HTTP URL中提取出来的
例如: 我们在浏览器中输入:http://www.hzau.edu.cn
浏览器发送的请求消息中,就会包含Host请求报头域,如下:
Host:www.hzau.edu.cn
此处使用缺省端口号80,若指定了端口号,则变成:Host:指定端口号
Referer
当浏览器向web服务器发送请求的时候,一般会带上Referer,告诉服务器我是从哪个页面链接过来的,服务器籍此可以获得一些信息用于处理。比如从我主页上链接到一个朋友那里,他的服务器就能够从HTTP Referer中统计出每天有多少用户点击我主页上的链接访问他的网站。可用于防盗链
User-Agent
作用:告诉HTTP服务器, 客户端使用的操作系统和浏览器的名称和版本.
我们上网登陆论坛的时候,往往会看到一些欢迎信息,其中列出了你的操作系统的名称和版本,你所使用的浏览器的名称和版本,这往往让很多人感到很神奇,实际上,服务器应用程序就是从User-Agent这个请求报头域中获取到这些信息User-Agent请求报头域允许客户端将它的操作系统、浏览器和其它属性告诉服务器。
例如: User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; CIBA; .NET CLR 2.0.50727; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; .NET4.0C; InfoPath.2; .NET4.0E)
更多参考资料:https://blog.csdn.net/u014175572/article/details/54861813
简述Cookie和Session的区别与联系。
cookie数据存放在客户的浏览器上,session数据放在服务器上
cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗考虑到安全应当使用session。
session会在一定时间内保存在服务器上。当访问增多,会比较占用服务器的性能考虑到减轻服务器性能方面,应当使用COOKIE。
单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。
建议:
将登陆信息等重要信息存放为SESSION
其他信息如果需要保留,可以放在COOKIE中
简述什么是浏览器的同源策略。
同源策略是浏览器上为安全性考虑实施的非常重要的安全策略。
何谓同源:
URL由协议、域名、端口和路径组成,如果两个URL的协议、域名和端口相同,则表示他们同源。
同源策略:
浏览器的同源策略,限制了来自不同源的"document"或脚本,对当前"document"读取或设置某些属性。
从一个域上加载的脚本不允许访问另外一个域的文档属性。
举个例子:
比如一个恶意网站的页面通过iframe嵌入了银行的登录页面(二者不同源),如果没有同源限制,恶意网页上的javascript脚本就可以在用户登录银行的时候获取用户名和密码。
在浏览器中<script>、<img>、<iframe>、<link>等标签都可以加载跨域资源,
而不受同源限制,但浏览器限制了JavaScript的权限使其不能读、写加载的内容。
另外同源策略只对网页的HTML文档做了限制,对加载的其他静态资源如javascript、css、图片等仍然认为属于同源。