前情提要:
首先膜拜loco大佬
肯定有人像我一样.不会异步,发一下.
一:性能比对
多进程,多线程,(这里不建议使用,太消耗性能)
进程池和线程池 (可以适当的使用)
单线程+异步协程 (推荐使用)
二:案例演示
1->1: 普通的啥也不用的
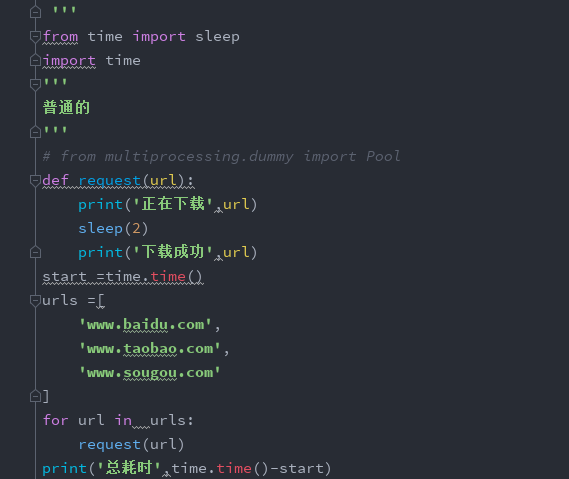
1->2:
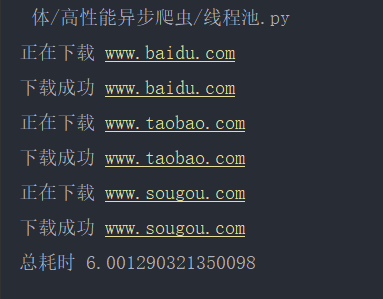
2->1:
使用线程池
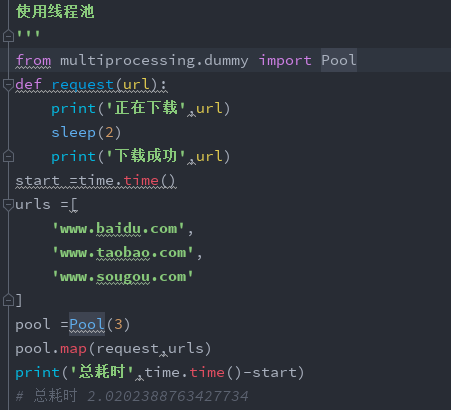
2->2:结果

三:异步协程
1: 协程的参数设定

2:协程的简单使用


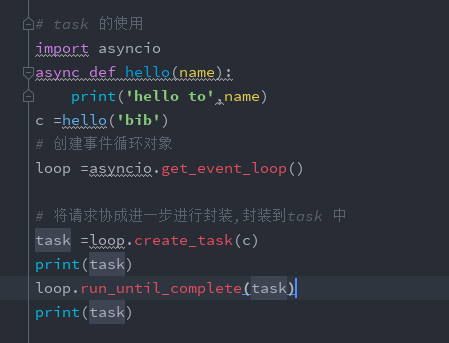
3:task的使用

4:future 的使用
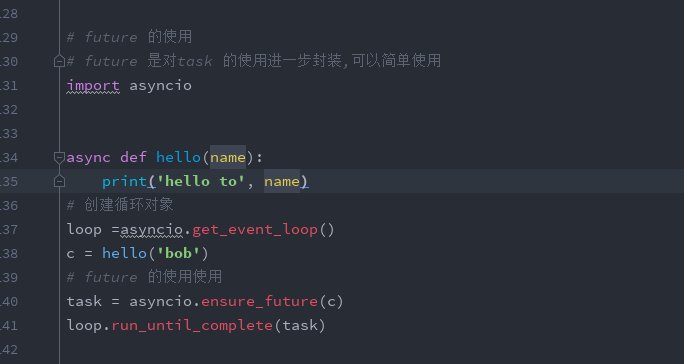
5:
回调函数的使用

四:支持异步请求网络的模块: aiohttp
import aiohttp
import asyncio
async def get_page(url):
async with aiohttp.ClientSession() as session: #with 前面都要加async
async with await session.get(url=url) as response: # 有io阻塞的都要加await
挂起
page_text = await response.text() #read() json()
print(page_text)
start = time.time()
urls = [
'http://127.0.0.1:5000/bobo',
'http://127.0.0.1:5000/jay',
'http://127.0.0.1:5000/tom',
'http://127.0.0.1:5000/bobo',
'http://127.0.0.1:5000/jay',
'http://127.0.0.1:5000/tom',
'http://127.0.0.1:5000/bobo',
'http://127.0.0.1:5000/jay',
'http://127.0.0.1:5000/tom'
]
tasks = []
loop = asyncio.get_event_loop()
for url in urls:
c = get_page(url)
task = asyncio.ensure_future(c)
tasks.append(task)
loop.run_until_complete(asyncio.wait(tasks))
print('总耗时:',time.time()-start)