一些了解机器学习有用的建议
翻译自 A Few Useful Things to Know about Machine Learning 有删改。
逛 Quora 偶然看到的一篇文章(准确的说是一篇论文),感觉颇有收获,于是打算写篇笔记(翻译)。水平十分有限,如有不当之处,恳请指出。
摘要
机器学习算法可以从实例中总结出如何执行重要任务。这通常要比手工编写的程序更加的可行和高效。随着可以被使用的数据越来越多,机器学习将能被解决更家复杂的问题。结果就是,机器学习被广泛的使用在计算机科学和其他领域。然而,开发成功的机器学习应用程序需要大量的“黑魔法”,这在教科书中是很难找到的。本文总结了机器学习研究人员和实践者所吸取的12个关键经验教训。这些包括要避免的陷阱,需要关注的重要问题,和一些常见问题的答案。
1. 介绍
机器学习系统自动从数据中学习程序。这是一个非常有吸引力的方案来替代人工建造,在过去的十年中,机器学习的应用已迅速蔓延到整个计算机科学领域。机器学习被用于网络搜索、垃圾邮件过滤、推荐系统、广告投放、信用评分、欺诈检测、股票交易、药物设计以及许多其他应用中。
分类器
从分类器讲起。
一个分类器(classifier)是一个系统,能够通过输入一个离散的或者连续的特征值(feature value)构成的向量(vector)并输出单一离散的值,即 “类别”(class)。举个例子,一个垃圾邮件过滤器将邮件消息分为“垃圾邮件”或“非垃圾邮件”,他的输入可能是一个二元向量 (X = (x1,...,x_j,...,x_d)),如果当邮件中第 (j) 个词在字典(dictionary)中出现,那么 (x_j = 1),否则 (x_j = 0)。一个学习器(learner)输入样例的一个训练集合 ((x_i,y_i)) ,(X_i = (x_i,...,x_d)) 是一个被观察的输入并且 (y_i) 是相应的输出,而学习器最终输出结果是一个分类器。对学习器的测试是这个分类器是否能对未来的例子 (x_t) 产生正确的输出 (y_t) 。(即这个分类器是否能将之前未见过的邮件正确的分为“垃圾邮件” 或 ”非垃圾邮件“)
2、学习器 = 表示 + 评估 + 优化
学习器 = 表示(representation) + 评估(evaluation) + 优化(optimization)
如果你有一个应用程序,并且想将机器学习应用其中,首先面对的问题就是,如何从如此多种多样的算法中找到自己想要的那个。从字面上来看,有上千种算法可供选择,并且每年仍会有上百篇被发表。不在如此大的范围中迷失的关键就是意识到,机器学习算法只由三部分组件组成,他们是:
表示(representation)
分类器必须用计算机能够处理的某种形式语言表示。相反,为学习器选择一种表示法就等于选择了它可能学到的一组分类器。这个集合被称为学习器的假设空间(hypothesis space)。如果一个分类器不在假设空间内,它就不能被学习。
评估(evaluation)
为了区分好的分类器和不好的分类器,需要一个评估函数(也称为目标函数(objective function)或评分函数(scoring function))。算法内部使用的评估功能可能与我们希望分类器进行优化的外部评估功能不同,比如优化(见下文)。
优化(optimization)
最后,我们需要一种方法在该语言中的分类器中搜索最高得分的那个。优化技术的选择是决定学习器效率的关键,也有助于判断评价函数是否具有多个最优性。对于初学者来说,开始使用现成的优化器是很常见的,这些优化器被定制的优化器所取代。
下面的表格显示了这三个组件中每个组件的常见示例。
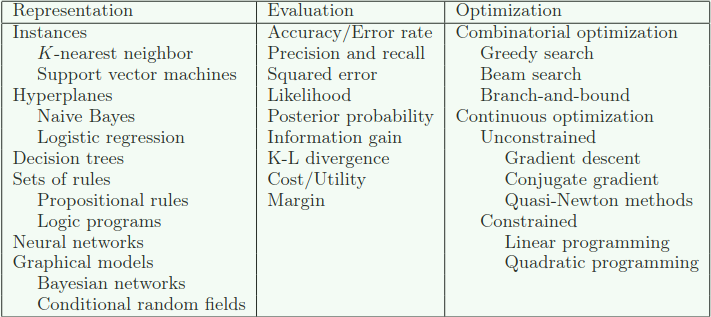
大多数的教材是按机器学习的 “表示(representation)” 来组织的,并且我们很容易忽略其他的部分也是一样重要的事实。这里没有一种简单的方法来选择每个组件,但是下面的部分会讨论这个问题的关键部分。
4. 重要的是 泛化/归纳
机器学习的基本目标是实现超出训练集的归纳/泛化(generalize)能力。因为不管我们有多少的数据,我们都几乎不可能在测试的时候再次精准的遇到那些样例数据。在训练集上表现的好很容易(只要记住样例就行了)。在机器学习新手中最常见的错误就是去测试训练集的数据并获得了一种成功的假像。如果选择的分类器被用于新的数据的测试,他通常不会比随机的猜测结果要好。所以一旦你自己要实现一个分类器,那么你要在最开始时保留一部分数据,然后只用这些数据在你的分类器在整个数据上学习的在最后阶段去测试它。这可以避免上述的问题。
测试数据可能以潜在的方式污染你的分类器,比如,你使用测试数据来调优参数并进行大量的调优(机器学习算法有很多的旋钮(knobs),成功往往来自于大量的扭动他们,这的确是一个方面)。当然,像之前提到的保存数据的做法,会减少可用于训练的数量。不过这可以通过交叉验证来缓解:将你的训练数据随机分成十个子集,在使用其余的数据进行训练时每次拿出一个数据集,在每个通过样例学习过的分类器上测试他没有见过的数据,然后平均得到的结果去观察特定的参数设置表现如何。
在机器学习的早期,训练数据和测试数据分离的需求并没有被广泛的意识到。这是一定程度上是因为,如果学习器表达形式十分有限(比如:超平面),那么测试数据和训练数据之间的差别可能很小。但是随着十分灵活的分类器(比如:决策树),或者有大量特征的现行分类器的出现,严格的分离将是强制性的。
其实以归纳、泛化为目标的机器学习产生了一个有趣的结果。不像大多数其他的优化问题,我们不能访问我们想要优化的函数。我们不得不使用训练集的错误来代替测试集的错误,即便充满了风险。怎么处理这个问题在下一部分讨论。从乐观的角度来看,因为目标函数(objective function)只是一个真正目标的代表,我们也许并不需要完全的去优化它;事实上简单贪婪搜索返回的局部最优可能优于全局最优解。
作者:Skipper
出处:http://www.cnblogs.com/backwords/p/9744714.html
本博客中未标明转载的文章归作者 Skipper 和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。