【模板】动态dp
题目描述
给定一棵(n)个点的树,点带点权。
有(m)次操作,每次操作给定(x,y),表示修改点(x)的权值为(y)。
你需要在每次操作之后求出这棵树的最大权独立集的权值大小。
输入输出格式
输入格式:
第一行,(n,m),分别代表点数和操作数。
第二行,(V_1,V_2,...,V_n),代表(n)个点的权值。
接下来(n-1)行,(x,y),描述这棵树的(n-1)条边。
接下来(m)行,(x,y),修改点(x)的权值为(y)。
输出格式:
对于每个操作输出一行一个整数,代表这次操作后的树上最大权独立集。
保证答案在int范围内
输入输出样例
输入样例#1:
10 10
-11 80 -99 -76 56 38 92 -51 -34 47
2 1
3 1
4 3
5 2
6 2
7 1
8 2
9 4
10 7
9 -44
2 -17
2 98
7 -58
8 48
3 99
8 -61
9 76
9 14
10 93
输出样例#1:
186
186
190
145
189
288
244
320
258
304
说明
对于30%的数据,(1le n,mle 10)
对于60%的数据,(1le n,mle 1000)
对于100%的数据,(1le n,mle 10^5)
胡小兔的题解
猫锟在WC2018讲的黑科技——动态DP,就是一个画风正常的DP问题再加上一个动态修改操作,就像这道题一样。(这道题也是PPT中的例题)
动态DP的一个套路是把DP转移方程写成矩阵乘法,然后用线段树(树上的话就是树剖)维护矩阵,这样就可以做到修改了。
注意这个“矩阵乘法”不一定是我们常见的那种乘法和加法组成的矩阵乘法。设(A∗B=C),常见的那种矩阵乘法是这样的:
而这道题中的矩阵乘法是这样的:
这就相当于常见矩阵乘法中的加法变成了max,乘法变成了加法。类似于乘法和加法的五种运算律,这两种变化也满足“加法交换律”、“加法结合律”、“max交换律”、“max结合律”和“加法分配律“。那么这种矩阵乘法显然也满足矩阵乘法结合律,就像正常的矩阵乘法一样,可以用线段树维护。
接下来我们来构造矩阵。首先研究DP方程。
就像“没有上司的舞会”一样,(f[i][0])表示子树(i)中不选(i)的最大权独立集大小,(f[i][1])表示子树(i)中选(i)的最大权独立集大小。
但这是动态DP,我们需要加入动态维护的东西以支持修改操作。考虑树链剖分。假设我们已经完成了树链剖分,剖出来的某条重链看起来就像这样,右边的是在树上深度较大的点:
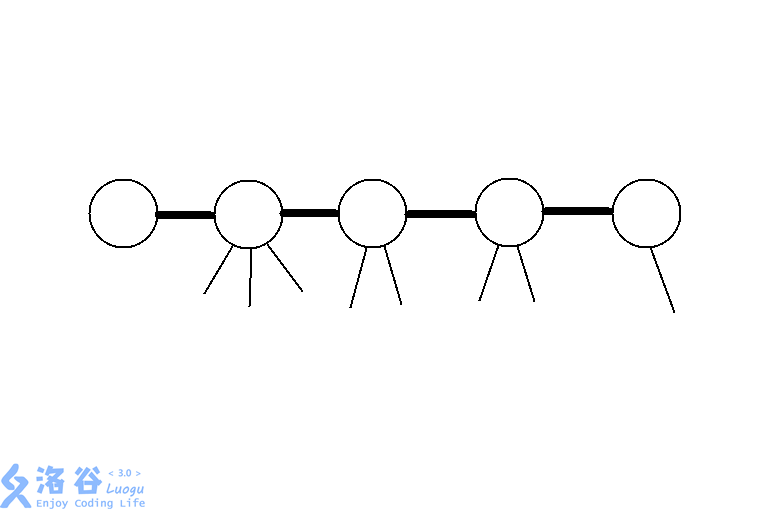
此时,比这条重链的top深度大且不在这条重链上的点的DP值都是已经求出来的(这可以做到)。我们把它们的贡献,都统一于它们在这条重链上对应的那个祖先上。
具体来说,设(g[i][0])表示不选i时,(i)不在链上的子孙的最大权独立集大小,(g[i][1])表示选(i)时,(i)不在链上的子孙再加上(i)自己的最大权独立集大小。与一般的DP状态的意义相比,除去了重儿子的贡献,这是为了利用树剖从任意节点到根最多(lceil log_2 n ceil)条重链的性质,便于维护以后的修改操作。
假如(i)右面的点是(i+1), 那么可以得出:
矩阵也就可以构造出来了:
读者可以动笔验证一下。(注意我们在这里用的“新矩阵乘法”的规则:原来的乘变成加,加变成取max。)
那么基本思路就很清楚了:树剖,维护区间矩阵乘积,单个矩阵代表(g),一条重链的矩阵乘积代表(f)。修改的时候,对于被修改节点到根节点路径上的每个重链(由下到上),先单点修改(g[i][1]),然后求出这条重链的(top)在修改之后的(f)值,然后更新(fa[top])的(g)值,一直进行下去。
每次答案就是节点1的(f)值。
时间复杂度(O(8n+8mlog^2 n))
代码
用bfs实现了dfs1之后,直接用拓扑序实现了dfs2,非常巧妙,常数小。
程序实现的时候把那个(-infty)设成0也没有任何问题……大概是数据弱的缘故。据说权值为正的时候写0没有问题,权值有负的时候写-INF更保险。
co int N=1e5+5;
int n,m,a[N];
int ecnt,adj[N],nxt[2*N],go[2*N];
int fa[N],son[N],sze[N],top[N],idx[N],pos[N],tot,ed[N];
ll f[N][2];
struct matrix{
ll g[2][2];
matrix(){
memset(g,0,sizeof g);
}
matrix operator*(co matrix&b)co{
matrix c;
for(int i=0;i<2;++i)
for(int j=0;j<2;++j)
for(int k=0;k<2;++k)
c.g[i][j]=max(c.g[i][j],g[i][k]+b.g[k][j]);
return c;
}
}val[N],data[4*N];
void add(int u,int v){
go[++ecnt]=v,nxt[ecnt]=adj[u],adj[u]=ecnt;
}
void init(){
static int que[N];
que[1]=1;
for(int ql=1,qr=1;ql<=qr;++ql)
for(int u=que[ql],e=adj[u],v;e;e=nxt[e])
if((v=go[e])!=fa[u])
fa[v]=u,que[++qr]=v;
for(int qr=n,u;qr;--qr){
sze[u=que[qr]]++;
sze[fa[u]]+=sze[u];
if(sze[u]>sze[son[fa[u]]]) son[fa[u]]=u;
}
for(int ql=1,u;ql<=n;++ql)
if(!top[u=que[ql]]){
for(int v=u;v;v=son[v])
top[v]=u,idx[pos[v]=++tot]=v;
ed[u]=tot;
}
for(int qr=n,u;qr;--qr){
u=que[qr];
f[u][1]=max(0,a[u]);
for(int e=adj[u],v;e;e=nxt[e])
if(v=go[e],v!=fa[u]){
f[u][0]+=max(f[v][0],f[v][1]);
f[u][1]+=f[v][0];
}
}
}
void build(int k,int l,int r){
if(l==r){
ll g0=0,g1=a[idx[l]];
for(int u=idx[l],e=adj[u],v;e;e=nxt[e])
if((v=go[e])!=fa[u]&&v!=son[u])
g0+=max(f[v][0],f[v][1]),g1+=f[v][0];
data[k].g[0][0]=data[k].g[0][1]=g0;
data[k].g[1][0]=g1;
val[l]=data[k];
return;
}
int mid=l+r>>1;
build(k<<1,l,mid);
build(k<<1|1,mid+1,r);
data[k]=data[k<<1]*data[k<<1|1];
}
void change(int k,int l,int r,int p){
if(l==r){
data[k]=val[l];
return;
}
int mid=l+r>>1;
if(p<=mid) change(k<<1,l,mid,p);
else change(k<<1|1,mid+1,r,p);
data[k]=data[k<<1]*data[k<<1|1];
}
matrix query(int k,int l,int r,int ql,int qr){
if(ql<=l&&r<=qr) return data[k];
int mid=l+r>>1;
if(qr<=mid) return query(k<<1,l,mid,ql,qr);
if(ql>mid) return query(k<<1|1,mid+1,r,ql,qr);
return query(k<<1,l,mid,ql,qr)*query(k<<1|1,mid+1,r,ql,qr);
}
matrix ask(int u){
return query(1,1,n,pos[top[u]],ed[top[u]]);
}
void path_change(int u,int x){
val[pos[u]].g[1][0]+=x-a[u];
a[u]=x;
matrix od,nw;
while(u){
od=ask(top[u]);
change(1,1,n,pos[u]);
nw=ask(top[u]);
u=fa[top[u]];
val[pos[u]].g[0][0]+=max(nw.g[0][0],nw.g[1][0])-max(od.g[0][0],od.g[1][0]);
val[pos[u]].g[0][1]=val[pos[u]].g[0][0];
val[pos[u]].g[1][0]+=nw.g[0][0]-od.g[0][0];
}
}
int main(){
// freopen(".in","r",stdin);
// freopen(".out","w",stdout);
read(n),read(m);
for(int i=1;i<=n;++i) read(a[i]);
for(int i=1,u,v;i<n;++i)
read(u),read(v),add(u,v),add(v,u);
init();
build(1,1,n);
int u,x;
matrix t;
while(m--){
read(u),read(x);
path_change(u,x);
t=ask(1);
printf("%lld
",max(t.g[0][0],t.g[1][0]));
}
return 0;
}
Frame的题解
他写得要有条理一些。
独立集 : 无向图中互不相邻的点组成的集合
最大权独立集 : 无向图中权值和最大的独立集
暴力
先看看问题的弱化版 : 没有修改操作 , (1 leq n leq 10^5)
考虑树形dp
用 (f[i][0]) 表示以 (i) 为根的子树中(包括 (i) ) , 不选择 (i) 能得到的最大权值和
用 (f[i][1]) 表示以 (i) 为根的子树中(包括 (i) ) , 选择 (i) 能得到的最大权值和
显然
时间复杂度是 (O(n)) 的
但如果每次修改后都对整棵树dp一次就变成(O(nm)) 肯定会T
一个简单的优化
我们发现每次更改一个点的权值后 , 其实只有从这个点到根节点的路径上的dp值需要变化
那么我们就只需要改这条链上的dp值就行了 , 那么复杂度就是 (O(displaystylesum Len))
当数据是一条链时 , 就和上一个暴力一样了
再考虑另一个子问题 : 有一个序列 (a_1 , a_2 ... a_n), 要求选出若干个数
在保证选出的数两两不相邻的情况下 , 数字和最大
有 (m) 次修改权值 , (1 leq n,m leq 10^5)
这就要用到动态dp了
朴素的方法:
(f[i][0]) 表示从头到$ i$ 且 $i (不选得到的最大权值和 )f[i][1]$ 表示从头到$ i$ 且 $i $选得到的最大权值和
接着我们把转移写成矩阵乘法的形式
广义矩阵乘法 : (A*B=C)
(C_{i,j}=max(a_{i,k}+b_{k,j} ))
可以证明这种矩阵乘法仍具有结合律
接着尝试把转移写成乘法
然后我们发现每个序列中的数都对应了一个矩阵
当我们要查询 ([l,r])的答案时 , 将$[l,r] $中的所有矩阵乘起来就好了
于是想到了线段树
修改也很简单 , 在线段树上一路走下去 , 到叶子节点时候 , 直接改就行了 , 回溯时pushup
时间复杂度 (O(m log n))
这题把问题出到了树上 , 那再套个 LCT 或树剖就好了
可以用(g[i][0/1])表示 在以 (i) 为根的子树中 , 轻儿子及其子树的dp值
那么
然后把转移改写成矩阵乘法的形式
这样就可以用 LCT 去维护了
我们在 access 时维护 (g) 数组 , 在 pushup 时维护 (f) 数组
修改时先 access 再splay , 这时修改 , 对其他节点没有影响 , 直接改上去就好了
询问时把1号节点 splay 到根 , 输出 (max(f[x][0],f[x][1])) 就好了
还有一个小技巧 , 初始化时先把所有儿子当做轻儿子 , 用dp值初始化 (f) 和 (g) 就好了
时间复杂度(O(8n+8mlog n)),这题LCT跑得竟然比树剖快……
再代码
co int N=1e5+1,INF=0x3f3f3f3f;
struct matrix{
int a[2][2];
void init(int g[2]){
a[0][0]=a[0][1]=g[0],a[1][0]=g[1],a[1][1]=-INF;
}
int*operator[](int i){return a[i];}
co int*operator[](int i)co{return a[i];}
matrix operator*(co matrix&b)co{
matrix c;
for(int i=0;i<2;++i)
for(int j=0;j<2;++j)
c[i][j]=max(a[i][0]+b[0][j],a[i][1]+b[1][j]);
return c;
}
};
namespace T{
int fa[N],ch[N][2],g[N][2];
matrix prod[N];
#define lc ch[x][0]
#define rc ch[x][1]
bool nroot(int x){return ch[fa[x]][0]==x||ch[fa[x]][1]==x;}
void pushup(int x){
prod[x].init(g[x]);
if(lc) prod[x]=prod[lc]*prod[x];
if(rc) prod[x]=prod[x]*prod[rc];
}
void rotate(int x){
int y=fa[x],z=fa[y],l=ch[y][1]==x,r=l^1;
if(nroot(y)) ch[z][y==ch[z][1]]=x;fa[x]=z;
ch[y][l]=ch[x][r],fa[ch[x][r]]=y;
ch[x][r]=y,fa[y]=x;
pushup(y);
}
void splay(int x){
for(int y,z;nroot(x);rotate(x)){
y=fa[x],z=fa[y];
if(nroot(y)) rotate(y==ch[z][1]^x==ch[y][1]?x:y);
}
pushup(x);
}
void access(int x){
for(int y=0;x;x=fa[y=x]){
splay(x);
if(rc){
g[x][0]+=max(prod[rc][0][0],prod[rc][1][0]);
g[x][1]+=prod[rc][0][0];
}
if(y){
g[x][0]-=max(prod[y][0][0],prod[y][1][0]);
g[x][1]-=prod[y][0][0];
}
rc=y,pushup(x);
}
}
}
using namespace T;
int n,m,val[N];
vector<int> e[N];
void dfs(int x,int fa){
g[x][1]=val[x],T::fa[x]=fa;
for(unsigned i=0;i<e[x].size();++i){
int y=e[x][i];
if(y==fa) continue;
dfs(y,x);
g[x][0]+=max(g[y][0],g[y][1]),g[x][1]+=g[y][0];
}
prod[x].init(g[x]);
}
int main(){
// freopen(".in","r",stdin);
// freopen(".out","w",stdout);
read(n),read(m);
for(int i=1;i<=n;++i) read(val[i]);
for(int i=1,x,y;i<n;++i){
read(x),read(y);
e[x].push_back(y),e[y].push_back(x);
}
dfs(1,0);
for(int x,y;m--;){
read(x),read(y);
access(x),splay(x);
g[x][1]+=y-val[x],val[x]=y;
pushup(x);
splay(1);
printf("%d
",max(prod[1][0][0],prod[1][1][0]));
}
return 0;
}
【加强版】
树剖常数小!跑不满!shadowice1984为了向你证明他能卡树剖并且会卡树剖从而出了这道毒瘤题.
保证答案均在int范围内.
然后就被离线算法针对了……因此这道题变成了强制在线.
shadowice1984的题解
上古科技:“全局平衡二叉树":可以去翻07年的论文”QTREE 解法的一些研究",(“全局平衡二叉树"这个中二的名字是论文里说的)
众所周知把刚才的树剖换成lct就可以做到一个log了,但是我们发现lct实在是常数太!大!了!绝对是跑不过实现的优秀的一点的树剖的
但是我们对于lct的复杂度证明却很感兴趣,为啥同样是操作了logn个数据结构,把线段树换成常数更大的splay复杂度反而少了一个log呢?(刚才这句话严格来讲是病句,常数和复杂度没有任何关联)
具体证明需要用到势能分析,但是感性理解一下就是如果我们把lct上的虚边也看成splay的边的话,我们发现整棵lct变成了一棵大splay,只是有些点度数不是2了
但是这些点度不是2的点并未破坏splay的势能分析换句话说势能分析对整颗大splay仍然生效,所以你的log次splay在整个大splay上只是一次splay而已
复杂度自然是均摊(O(log n))了
但是,我们发现这是颗静态树,使用splay实在是大(常)材(数)小(过)用(大)了
于是我们考虑将lct强行静态化,换句话说,建一个像splay一样的全局平衡的树
观察到线段树只是局部平衡的,在碰到专业卡链剖的数据--链式堆(根号n个长度为根号n的链连成完全二叉树的形状)的时候会导致算上虚边之后的整颗树左倾或者右倾
此时我们发现如果在建线段树的时候做点手脚,我们把线段树换成二叉查找树bst,并且这个bst不是严格平衡的话,我们可以做到更加优秀的复杂度,使得算上虚边之后的树树高达到(O(log n))级别
我们还是在树上dfs,但是对于重链建bst的时候我们并不建一个完美的bst,而是将每一个节点附上一个权值,权值为它所有轻儿子的siz之和+1(+1是为了好写,lsiz[x]=siz[x]-siz[son[x]]),然后我们每次找这个链的带权重心,把他作为这一级的父亲,然后递归两边进行建bst
当然我们发现最坏情况下我们可以建出一个严重左倾或者右倾的bst
但是,我们考虑算上虚边的整颗树我们会发现一个神奇的性质,无论是经过一条重的二叉树边还是虚边,所在子树的siz至少翻一倍,而这个性质在原来的线段树上是没有的
所以这个大bst的高度是(O(log n))的
当然,这个bst既不能旋转也不能splay,所以维护区间信息会比较吃力,但是,我们为什么要维护区间信息呢?这是动态dp啊,我们只需要维护这整个重链的矩阵连乘积就行了……,所以维护整个重链的连乘积还是可以做到的
时间复杂度(O(nlog n+m log n))
代码
这份代码跑LG4719的时候没有LCT快……大概除了AC这道题目就没有用了。算是学了一种构造吧。
co int N=1e6+1,INF=0x3f3f3f3f;
int n,m,val[N],fa[N],siz[N],son[N];
vector<int> e[N];
void dfs(int x,int fa){
::fa[x]=fa,siz[x]=1;
for(unsigned i=0;i<e[x].size();++i){
int y=e[x][i];
if(y==fa) continue;
dfs(y,x),siz[x]+=siz[y];
if(siz[y]>siz[son[x]]) son[x]=y;
}
}
struct matrix{
int a[2][2];
void init(int g[2]){
a[0][0]=a[0][1]=g[0],a[1][0]=g[1],a[1][1]=-INF;
}
int*operator[](int i){return a[i];}
co int*operator[](int i)co{return a[i];}
matrix operator*(co matrix&b)co{
matrix c;
for(int i=0;i<2;++i)
for(int j=0;j<2;++j)
c[i][j]=max(a[i][0]+b[0][j],a[i][1]+b[1][j]);
return c;
}
};
namespace T{
int root,st[N],top,lsiz[N];
int ch[N][2],fa[N],g[N][2];
matrix prod[N];
void pushup(int x){
prod[x].init(g[x]);
if(ch[x][0]) prod[x]=prod[ch[x][0]]*prod[x];
if(ch[x][1]) prod[x]=prod[x]*prod[ch[x][1]];
}
int sbuild(int l,int r){
if(l>r) return 0;
int tot=0;
for(int i=l;i<=r;++i) tot+=lsiz[st[i]];
for(int i=l,ns=lsiz[st[i]];i<=r;++i,ns+=lsiz[st[i]]) if(2*ns>=tot){
int ls=sbuild(l,i-1),rs=sbuild(i+1,r); // matrix decides the order
ch[st[i]][0]=ls,ch[st[i]][1]=rs;
fa[ls]=st[i],fa[rs]=st[i];
pushup(st[i]);
return st[i];
}
}
int build(int x){
for(int y=x;y;y=son[y])
for(unsigned i=0;i<e[y].size();++i){
int z=e[y][i];
if(::fa[y]==z||son[y]==z) continue;
int t=build(z);
fa[t]=y;
g[y][0]+=max(prod[t][0][0],prod[t][1][0]);
g[y][1]+=prod[t][0][0];
}
top=0;
for(int y=x;y;y=son[y]) st[++top]=y,lsiz[y]=siz[y]-siz[son[y]];
return sbuild(1,top);
}
bool isroot(int x){
return ch[fa[x]][0]!=x&&ch[fa[x]][1]!=x;
}
void modify(int x,int v){
g[x][1]+=v-val[x],val[x]=v;
for(int y=x;y;y=fa[y])
if(isroot(y)&&fa[y]){
g[fa[y]][0]-=max(prod[y][0][0],prod[y][1][0]);
g[fa[y]][1]-=prod[y][0][0];
pushup(y);
g[fa[y]][0]+=max(prod[y][0][0],prod[y][1][0]);
g[fa[y]][1]+=prod[y][0][0];
}else pushup(y);
}
}
using namespace T;
int main(){
// freopen("LG4719.in","r",stdin);
// freopen("LG4719.out","w",stdout);
read(n),read(m);
for(int i=1;i<=n;++i) g[i][1]=read(val[i]);
for(int i=1,x,y;i<n;++i){
read(x),read(y);
e[x].push_back(y),e[y].push_back(x);
}
dfs(1,0);
root=build(1);
int lastans=0;
for(int x,y;m--;){
read(x),x^=lastans,read(y);
modify(x,y);
printf("%d
",lastans=max(prod[root][0][0],prod[root][1][0]));
}
return 0;
}