从临床文本中提取COVID-19诊断和症状:一个新的标注语料库和神经事件提取框架
Abstract
We introduce a span-based event extraction model that jointly extracts all annotated phenomena, achieving high performance in identifying COVID-19 and symptom events with associated assertion values (0.83-0.97 F1 for events and 0.73-0.79 F1 for assertions). Our span-based event extraction model outperforms an extractor built on MetaMapLite for the identification of symptoms with assertion values. In a secondary use application, we predicted COVID-19 test results using structured patient data (e.g. vital signs and laboratory results) and automatically extracted symptom information, to explore the clinical presentation of COVID-19. Automatically extracted symptoms improve COVID-19 prediction performance, beyond structured data alone.
我们引入了一个基于跨领域的事件提取模型,该模型联合提取所有标注的现象,在使用相关的断言值(事件为0.83-0.97 F1,断言为0.73-0.79 F1)识别COVID-19和症状事件方面实现了高性能。我们基于跨事件提取模型在使用断言值识别症状方面优于基于MetaMapLite构建的提取器。在二次使用应用中,我们使用结构化的患者数据(如生命体征和实验室结果)预测COVID-19检测结果,并自动提取症状信息,以探索COVID-19的临床表现。自动提取的症状改善了COVID-19预测性能,不仅仅是结构化数据。
MateMapLite
MetaMap is a widely used named entity recognition tool that identifies concepts from the Unified Medical Language System Metathesaurus in text. This study presents MetaMap Lite, an implementation of some of the basic MetaMap functions in Java. On several collections of biomedical literature and clinical text, MetaMap Lite demonstrated real-time speed and precision, recall, and F1 scores comparable to or exceeding those of MetaMap and other popular biomedical text processing tools, clinical Text Analysis and Knowledge Extraction System (cTAKES) and DNorm.
MateMapLite是一种广泛使用的命名实体识别工具,用于以文本形式识别来自统一医学语言系统元同义词典的概念。本研究介绍了MetaMap Lite,它是用Java实现的一些基本MetaMap功能。
在一些生物医学文献和临床文本的收集中,MetaMap Lite显示了实时的速度和精度、召回率和F1分数,与MetaMap和其他流行的生物医学文本处理工具、临床文本分析和知识提取系统(cTAKES)和DNorm相当或超过。
Instruction
Two major aims
1) to describe the presence,character, and changes in symptoms associated with clinical conditions, where delays or misdiagnoses occur in clinical practice and impact patient outcomes (e.g. infectious diseases, cancer) , and
2) to provide a more efficient and cost-effective mechanism to validate clinical prediction rules previously derived from large prospective cohort studies .
1)描述与临床条件相关的症状的存在、特征和变化,在临床实践中发生延误或误诊并影响患者结局(如感染性疾病、癌症)
2)提供一种更有效、更经济的机制来验证以前从大型前瞻性队列研究中得出的临床预测规则。
Annotated Corpora-注释全集
CACT( COVID-19 Annotated Clinical Text)
This work presents a new corpus of clinical text annotated for COVID-19, referred to as the COVID-19 Annotated Clinical Text (CACT) Corpus. CACT consists of 1,472 notes from the University of Washington (UW) clinical repository with detailed event-based annotations for COVID-19 diagnosis, testing, and symptoms.
We used these structured fields to assign aCOVID-19 Testlabel describing COVID-19 polymerase chain reaction (PCR) testing to each note based on patient test status within the UW system (no data external to UW was used):
• none: patient testing information is not available
• positive: patient will have at least one future positive test
• negative: patient will only have future negative tests
在疫情早期,华盛顿大学电子卫生报告不包括COVID-19的具体结构数据;但是,随着检测的扩展,添加了指示COVID-19检测类型和结果的结构化字段。
论文使用这些结构化字段,根据患者在UW系统中的检测状态,给每个记录分配注释:
• none:无法获得患者的检测信息
• positive:病人将来至少会有一次检测呈阳性
• negative:病人以后的检测结果只有阴性
Annotation Scheme
Each event includes a trigger that identifies and anchors the event and arguments that characterize the event. The annotation scheme includes two types of arguments:labeled argumentsand span-only arguments.Labeled arguments(e.g.Assertion) include an argument span, type, and subtype (e.g. present). The subtype label normalizes the span information to a fixed set of classes and allows the extracted information to be directly used in secondary use applications.Span-only arguments(e.g.Characteristics) include an argument span and type but do not include a subtype label, because the argument information is not easily mapped to a fixed set of classes.
每个事件都包括一个触发器,用于标识和定位事件,以及描述事件的参数。
注释模式包括两种类型的参数:标记参数和仅跨参数。
标记参数(例如断言)包括参数跨度、类型和子类型(例如present)。子类型标签将跨度信息规范化为一组固定的类,并允许提取的信息直接用于辅助使用应用。
仅跨参数(例如特征)包括参数span和类型,但不包括子类型标签,因为参数信息不容易映射到固定的类集。
Annotation Scoring and Evaluation
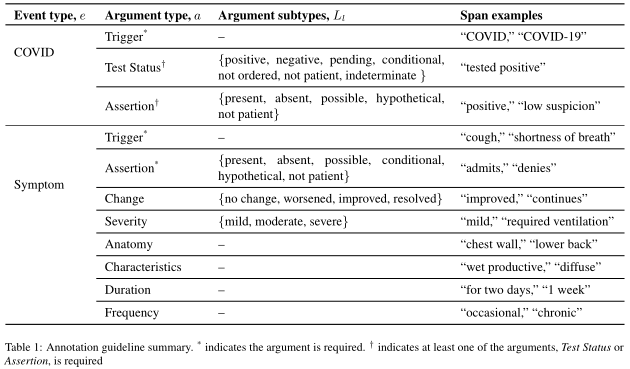
Trigger:Triggers,Ti, are represented by a pair (event type,ei; token indices,xi). Trigger equivalence is defined as
Arguments:Events are aligned based on trigger equivalence. The arguments of events with equivalent triggers are compared using different criteria for labeled arguments and span-only arguments.Labeled arguments,Li, are represented as a triple (argument type,ai; token indices,xi; subtype,li). For labeled arguments capture the salient information and equivalence is defined as
Span-only arguments with equivalent triggers and argument types, are compared at the token-level (rather than the span-level) to allow partial matches.
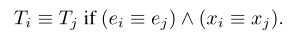

注释评分与评价
触发器:要求事件等价并且标记下标等价
参数:标记参数:获取详细信息,要求在触发器等价基础上参数类型和下级参数也要等价
仅跨参数:获取部分匹配信息,要求触发器等价基础上参数类型等价
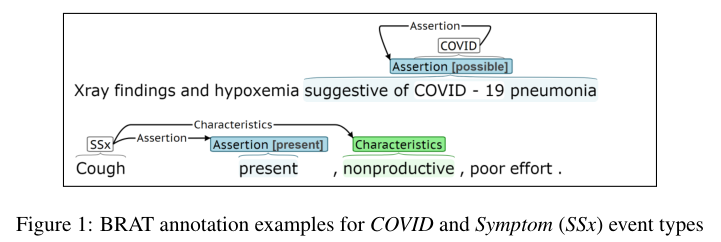
For Symptom events, the trigger identifies the specific symptom, for example “wheezing” or “fever,” which is characterized through Assertion,Change, Severity,Anatomy,Characteristics,Duration, and Frequency arguments. Symptoms were annotated for all conditions/diseases, not just COVID-19. Notes were annotated using the BRA T annotation tool. Figure 1 presents BRA T annotation examples.
对于症状事件,触发器识别特定的症状,例如“哮喘”或“发烧”,通过断言、变化、严重程度、解剖、特征、持续时间和频率参数来描述。不只是COVID-19,所有疾病的症状都有注释。使用BRAT注释工具对文本进行注释。图1给出了BRAT注释示例。
BRAT 是一个基于 web 的文本标注工具, 主要用于对文本的结构化标注, 用 BRAT 生成的标注结果能够把无结构化的原始文本结构化, 供计算机处理。利用该工具可以方便的获得各项 NLP 任务需要的标注语料。提供【实体】【关系】【事件】【属性】四种类型的自定义文本标注, 可以在单词、句子或任何粒度的文本上进行标注, 满足大多数有监督 NLP 任务需要 。
改进: 大多数先前的医疗问题提取工作(包括症状提取)都侧重于确定具体问题、对提取的现象进行规范化和预测断言值(例如,存在还是不存在)。这种方法忽略了许多临床医生记录的症状细节,这些细节构成了许多临床笔记的核心。症状细节描述变化(如改善、恶化、缺乏变化)、严重程度(如强度和对日常活动的影响)、特殊特征(如生产性、干性或因咳嗽而吠叫)和位置。我们假设这种症状粒度对于许多临床情况是需要的,以提高及时诊断和验证诊断预测规则。
Annotation Statistics
CACT includes 1,472 notes with a 70%/30% train/test split and 29.9K annotated events (5.4K COVID and 24.4K Symptom).
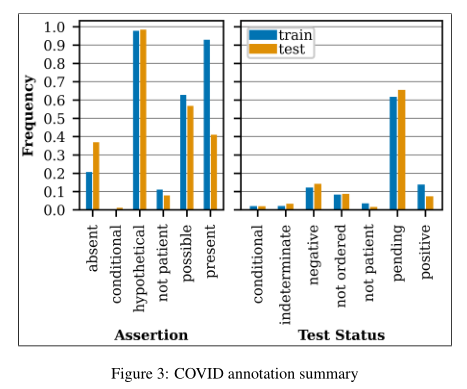
The hypothetical subtype applies to sentences like, “She is mildly concerned about the coronavirus” and “She cancelled nexplanon replacement due to COVID-19.”
The possible subtype applies to sentences like, “risk of Covid exposure” and “Concern for respiratory illness (including COVID-19 and influenza).”
可以看出猜想和可能两个断言子类频率较高,其中
猜想应用于像这种“她对冠状病毒有点担心”和“因为新冠肺炎,她取消了换药”句子;
可能应用于像这种“感染新冠的风险”和“关注呼吸道疾病(包括COVID-19和流感)”句子。
在测试状态中暂定频率也很高。
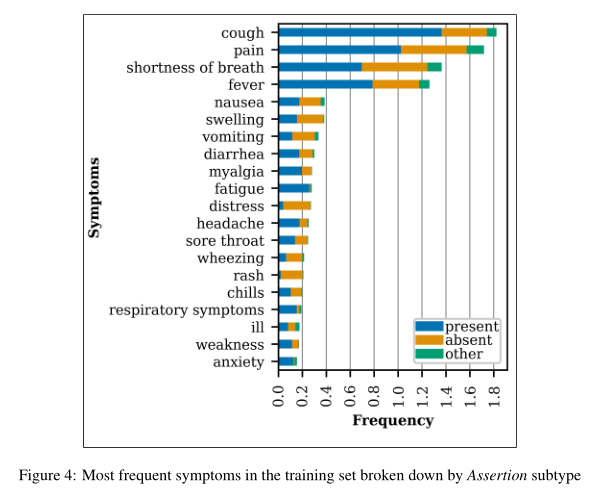
The extracted symptoms in Figure 4 were manually normalized to aggregate different extracted spans with similar meanings (e.g. “sob” and “short of breath”→“shortness of breath”; “febrile” and “fevers”→“fever”).
进行归一化操作,将相似症状进行聚会,同时重点关注出现过10次以上症状

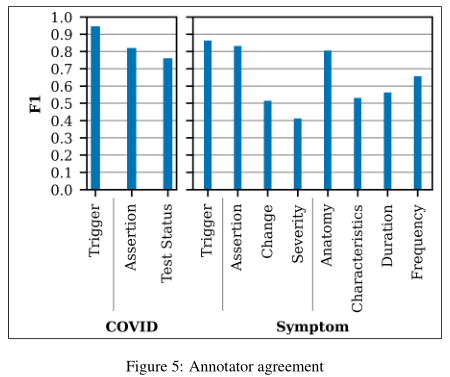
Annotator Agreement
所有注释都是由四名华盛顿大学医学院大四学生完成的,并进行了严格审查和注释更新。对于有标记的参数,F1分数是各个子类型的微平均(micro-average)。
Event Extraction
1. Methods
Event extraction tasks typically require prediction of the following event phenomena:
• trigger span identification
• trigger type (event type) classification
• argument span identification
• argument type/role classificationThe CACT annotation scheme differs from this configuration in that labeled arguments require the argument type (e.g.Assertion) and the subtype (e.g.present,absent, etc.) to be predicted.
事件提取任务需要:触发器跨度识别,触发器类型分类,参数跨度识别,参数类型分类,(CACT)标记参数类型和子类识别分类
We implement a span-based, end-to-end, multi-layer event extraction model that jointly predicts all event phenomena, including the trigger span, event type, and argument spans, types, and subtypes.
实现了一个基于跨度、端到端、多层事件提取模型,该模型联合预测所有事件现象,包括触发器跨度、事件类型和参数跨度、类型和子类型。与之前的相关工作不同的是,多个span分类器用于容纳参数子类型。
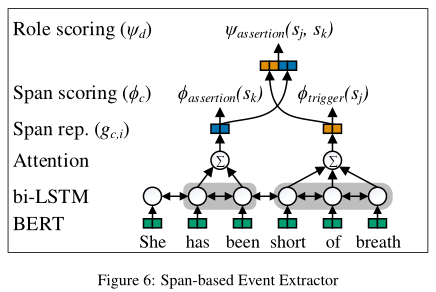
每个输入的句子由若干个标记组成,,n 是标记的数量。
每个句子的所有可能的span集合是枚举的 ,m 是标记长度小于等于 M 个标记的跨度数量。
对于每个在 S 中的 span, 这个模型都会生成触发器和参数预测,并且从每个span预测中会预测每对触发器和参数来生成事件。
Input encoding:使用 Bio+Clinical BERT 对每个句子映射到上下文词嵌入,然后将其交付给 bi-LSTM , bi-LSTM 有个隐藏大小 vh, 向前和向后的状态分别标记为 和
和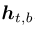
, 然后连接成向量
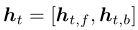 ,t 代表标记位置。
,t 代表标记位置。
Span representation:每个 span 都用 bi-LSTM 隐藏状态的注意力权值之和表示。对于不同的注意力机制 c ,用触发器,每个标记参数和实现,对于单个的注意力机制还要有所有的span-only参数实现。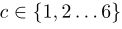
,1 代表触发器, 4 代表标记数据, 1代表 span-only参数。
使用LSTM模型可以更好的捕捉到较长距离的依赖关系,但是利用LSTM对句子进行建模还存在一个问题:无法编码从后到前的信息。在更细粒度的分类时,通过Bi-LSTM可以更好的捕捉双向的语义依赖。
https://blog.csdn.net/Smile_mingm/article/details/105202022
这里论文想要获取新冠肺炎的发病特征参数,所以要使用双向的LSTM。
对于在标记位置 t 处的 span representation C 的注意力得分计算方式为: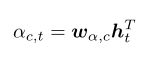
,
是经过学习得到的向量。
对于 span representation C, span i , and token position t , 标准化的注意力权重计算方法是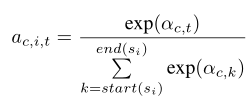
,其中
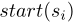 和
和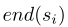
是 span i 起始标记下标和结束标记下标。
对于每个 span i 的 span representation C 被 bi-LSTM 隐藏状态的注意力权重和计算 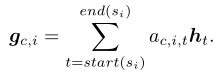
。
Span prediction: 和 Span representation 类似,不同的 span 分类器 c 会用触发器和每个标记参数实现,单个 span 分类器预测所有的 span-only 参数, ,1 代表触发器, 4 代表标记数据, 1代表 span-only参数。
对于 span i 和 classifier c 的标记得分计算为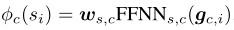

,
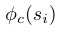 函数会产出一个标记得分向量,
函数会产出一个标记得分向量,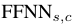 是一个非线性投影。
是一个非线性投影。
前馈神经网络(FF或FFNN),通常通过反向传播算法来训练FFNNs,给网络一对数据集(输入数据集+期望的输出数据集),这叫做监督学习,而不是只给它输入,让网络来填补空白的非监督学习假设网络有足够多的隐藏神经元,理论上它总是可以模拟输入和输出之间的关系。实际上,它们的使用非常有限,但是它们通常与其他网络结合在一起形成新的网络。
触发器预测标签集  , 不同的分类器用于每个标记参数 (Assertion,Change,Severity, and Test Status) 的标记集合
, 不同的分类器用于每个标记参数 (Assertion,Change,Severity, and Test Status) 的标记集合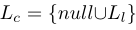 , 例如,
, 例如,![]() 对于单个分类器预测所有的 span-only 参数的标记集
对于单个分类器预测所有的 span-only 参数的标记集 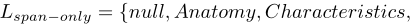
 。
。
Argument role prediction: 参数角色层使用单独的二进制分类器 d 来预测,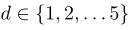 将参数分配给触发器,
将参数分配给触发器, 4 代表标记参数,1 代表span-only参数。
对于触发器 j 和 参数 k 的参数角色得分使用参数角色分类器 d 来计算
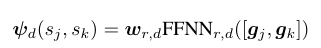
,该函数会产出一个大小为2的向量。
Span pruning: 为了控制成对发生的参数角色预测的时间和空间复杂度,在此期间每个span分类器只考虑顶端 K 个 span,同时 span得分计算为最大的标记分数,除了 null 标记分数。
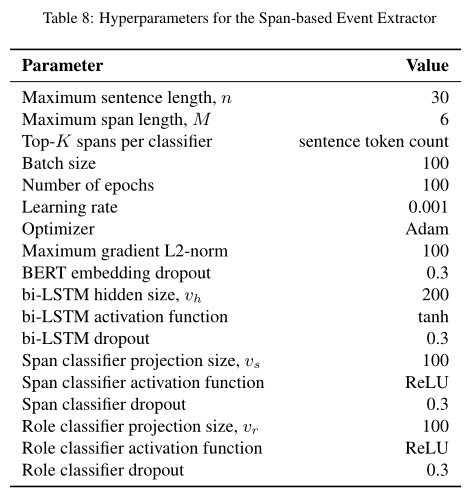
2.Model Configuration
训练集上采用三倍交叉验证 3-fold cross validation (CV) ,训练损失通过对所有span和参数角色分类器的交叉熵进行求和来计算。模型是使用Python PyTorch模块实现的。
在训练过程中,经常会出现过拟合问题,模型在验证数据中的评估常用的是交叉验证,又称循环验证,它将原始数据分成K组(K-Fold),将每个子集数据分别做一次验证集,其余的K-1组子集数据作为训练集,这样会得到K个模型。这K个模型分别在验证集中评估结果,最后的误差MSE(Mean Squared Error)加和平均就得到交叉验证误差。交叉验证有效利用了有限的数据,并且评估结果能够尽可能接近模型在测试集上的表现,可以做为模型优化的指标使用。
3.result
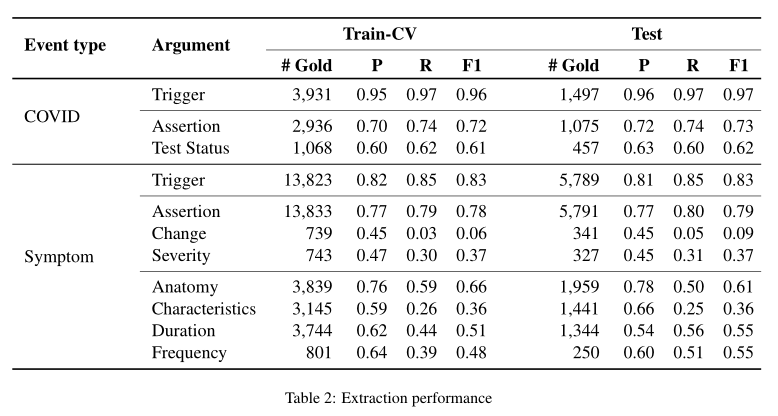
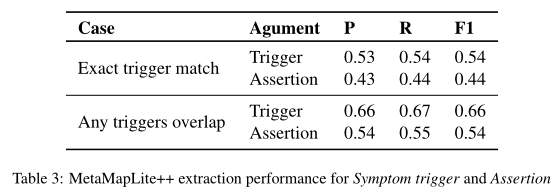

可以看出验证集和测试集得出的结果相似,相比较于MetaMapLite++ 来说黄金断言标签#Gold,精确度P,召回率R,F1(micro-average)都提高不少。但在 change, Severity, Characteristics, Duration,and Frequency这些子类上相对于assert表现较差。
Conclusions
论文提出了一种新的语料库CACT,实现了基于span的事件提取器,它能够联合所有的注释现象,包括参数和子类型,较MetaMapLite++有较好的性能表现。缺点是需要人工标记语料库,无法自动化提取非结构的病历信息,其中病症特征提取容易忽略一些症状特征(例如嗅觉,听觉之类的其他生理功能)。但这种医疗事件提取器但在未来仍有广阔的应用前景,可以快速准确地分辨新冠肺炎和其他呼吸道感染/流感,更进一步可用于医疗事理图谱构建来推测疾病之间的逻辑联系。