Elasticsearch-基础介绍及索引原理分析
最近在参与一个基于Elasticsearch作为底层数据框架提供大数据量(亿级)的实时统计查询的方案设计工作,花了些时间学习Elasticsearch的基础理论知识,整理了一下,希望能对Elasticsearch感兴趣/想了解的同学有所帮助。 同时也希望有发现内容不正确或者有疑问的地方,望指明,一起探讨,学习,进步。
介绍
Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene(TM) 基础上的搜索引擎.当然 Elasticsearch 并不仅仅是 Lucene 那么简单,它不仅包括了全文搜索功能,还可以进行以下工作:
- 分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
- 实时分析的分布式搜索引擎。
- 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
基本概念
先说Elasticsearch的文件存储,Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档,用JSON作为文档序列化的格式,比如下面这条用户数据:
{
"name" : "John",
"sex" : "Male",
"age" : 25,
"birthDate": "1990/05/01",
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
用Mysql这样的数据库存储就会容易想到建立一张User表,有balabala的字段等,在Elasticsearch里这就是一个文档,当然这个文档会属于一个User的类型,各种各样的类型存在于一个索引当中。这里有一份简易的将Elasticsearch和关系型数据术语对照表:
关系数据库 ⇒ 数据库 ⇒ 表 ⇒ 行 ⇒ 列(Columns)
Elasticsearch ⇒ 索引(Index) ⇒ 类型(type) ⇒ 文档(Docments) ⇒ 字段(Fields)
一个 Elasticsearch 集群可以包含多个索引(数据库),也就是说其中包含了很多类型(表)。这些类型中包含了很多的文档(行),然后每个文档中又包含了很多的字段(列)。Elasticsearch的交互,可以使用Java API,也可以直接使用HTTP的Restful API方式,比如我们打算插入一条记录,可以简单发送一个HTTP的请求:
PUT /megacorp/employee/1
{
"name" : "John",
"sex" : "Male",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
更新,查询也是类似这样的操作,具体操作手册可以参见Elasticsearch权威指南
索引
Elasticsearch最关键的就是提供强大的索引能力了,其实InfoQ的这篇时间序列数据库的秘密(2)——索引写的非常好,我这里也是围绕这篇结合自己的理解进一步梳理下,也希望可以帮助大家更好的理解这篇文章。
Elasticsearch索引的精髓:
一切设计都是为了提高搜索的性能
另一层意思:为了提高搜索的性能,难免会牺牲某些其他方面,比如插入/更新,否则其他数据库不用混了。前面看到往Elasticsearch里插入一条记录,其实就是直接PUT一个json的对象,这个对象有多个fields,比如上面例子中的name, sex, age, about, interests,那么在插入这些数据到Elasticsearch的同时,Elasticsearch还默默1的为这些字段建立索引--倒排索引,因为Elasticsearch最核心功能是搜索。
Elasticsearch是如何做到快速索引的
InfoQ那篇文章里说Elasticsearch使用的倒排索引比关系型数据库的B-Tree索引快,为什么呢?
什么是B-Tree索引?
上大学读书时老师教过我们,二叉树查找效率是logN,同时插入新的节点不必移动全部节点,所以用树型结构存储索引,能同时兼顾插入和查询的性能。因此在这个基础上,再结合磁盘的读取特性(顺序读/随机读),传统关系型数据库采用了B-Tree/B+Tree这样的数据结构:
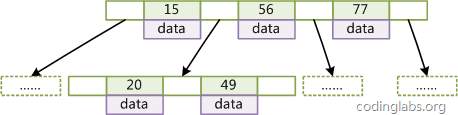
为了提高查询的效率,减少磁盘寻道次数,将多个值作为一个数组通过连续区间存放,一次寻道读取多个数据,同时也降低树的高度。
什么是倒排索引?

继续上面的例子,假设有这么几条数据(为了简单,去掉about, interests这两个field):
| ID | Name | Age | Sex |
| -- |:------------:| -----:| -----:|
| 1 | Kate | 24 | Female
| 2 | John | 24 | Male
| 3 | Bill | 29 | Male
ID是Elasticsearch自建的文档id,那么Elasticsearch建立的索引如下:
Name:
| Term | Posting List |
| -- |:----:|
| Kate | 1 |
| John | 2 |
| Bill | 3 |
Age:
| Term | Posting List |
| -- |:----:|
| 24 | [1,2] |
| 29 | 3 |
Sex:
| Term | Posting List |
| -- |:----:|
| Female | 1 |
| Male | [2,3] |
Posting List
Elasticsearch分别为每个field都建立了一个倒排索引,Kate, John, 24, Female这些叫term,而[1,2]就是Posting List。Posting list就是一个int的数组,存储了所有符合某个term的文档id。
看到这里,不要认为就结束了,精彩的部分才刚开始...
通过posting list这种索引方式似乎可以很快进行查找,比如要找age=24的同学,爱回答问题的小明马上就举手回答:我知道,id是1,2的同学。但是,如果这里有上千万的记录呢?如果是想通过name来查找呢?
Term Dictionary
Elasticsearch为了能快速找到某个term,将所有的term排个序,二分法查找term,logN的查找效率,就像通过字典查找一样,这就是Term Dictionary。现在再看起来,似乎和传统数据库通过B-Tree的方式类似啊,为什么说比B-Tree的查询快呢?
Term Index
B-Tree通过减少磁盘寻道次数来提高查询性能,Elasticsearch也是采用同样的思路,直接通过内存查找term,不读磁盘,但是如果term太多,term dictionary也会很大,放内存不现实,于是有了Term Index,就像字典里的索引页一样,A开头的有哪些term,分别在哪页,可以理解term index是一颗树:
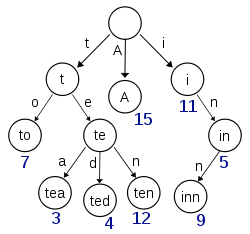
这棵树不会包含所有的term,它包含的是term的一些前缀。通过term index可以快速地定位到term dictionary的某个offset,然后从这个位置再往后顺序查找。
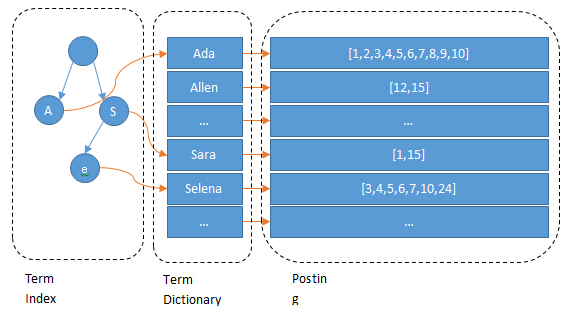
所以term index不需要存下所有的term,而仅仅是他们的一些前缀与Term Dictionary的block之间的映射关系,再结合FST(Finite State Transducers)的压缩技术,可以使term index缓存到内存中。从term index查到对应的term dictionary的block位置之后,再去磁盘上找term,大大减少了磁盘随机读的次数。
这时候爱提问的小明又举手了:"那个FST是神马东东啊?"
一看就知道小明是一个上大学读书的时候跟我一样不认真听课的孩子,数据结构老师一定讲过什么是FST。但没办法,我也忘了,这里再补下课:
FSTs are finite-state machines that map a term (byte sequence) to an arbitrary output.
假设我们现在要将mop, moth, pop, star, stop and top(term index里的term前缀)映射到序号:0,1,2,3,4,5(term dictionary的block位置)。最简单的做法就是定义个Map<string, integer="">,大家找到自己的位置对应入座就好了,但从内存占用少的角度想想,有没有更优的办法呢?答案就是:FST(理论依据在此,但我相信99%的人不会认真看完的)
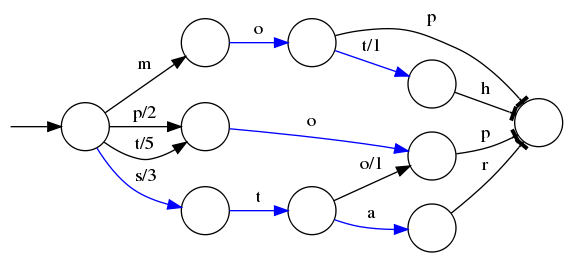
⭕️表示一种状态
-->表示状态的变化过程,上面的字母/数字表示状态变化和权重
将单词分成单个字母通过⭕️和-->表示出来,0权重不显示。如果⭕️后面出现分支,就标记权重,最后整条路径上的权重加起来就是这个单词对应的序号。
FSTs are finite-state machines that map a term (byte sequence) to an arbitrary output.
FST以字节的方式存储所有的term,这种压缩方式可以有效的缩减存储空间,使得term index足以放进内存,但这种方式也会导致查找时需要更多的CPU资源。
后面的更精彩,看累了的同学可以喝杯咖啡……
压缩技巧
Elasticsearch里除了上面说到用FST压缩term index外,对posting list也有压缩技巧。
小明喝完咖啡又举手了:"posting list不是已经只存储文档id了吗?还需要压缩?"
嗯,我们再看回最开始的例子,如果Elasticsearch需要对同学的性别进行索引(这时传统关系型数据库已经哭晕在厕所……),会怎样?如果有上千万个同学,而世界上只有男/女这样两个性别,每个posting list都会有至少百万个文档id。 Elasticsearch是如何有效的对这些文档id压缩的呢?
Frame Of Reference
增量编码压缩,将大数变小数,按字节存储
首先,Elasticsearch要求posting list是有序的(为了提高搜索的性能,再任性的要求也得满足),这样做的一个好处是方便压缩,看下面这个图例: 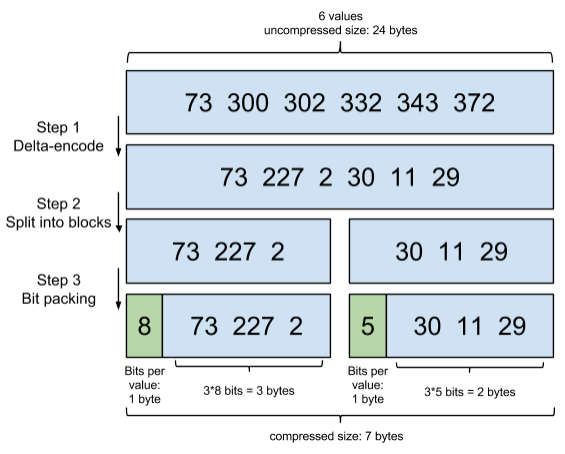
如果数学不是体育老师教的话,还是比较容易看出来这种压缩技巧的。
原理就是通过增量,将原来的大数变成小数仅存储增量值,再精打细算按bit排好队,最后通过字节存储,而不是大大咧咧的尽管是2也是用int(4个字节)来存储。
Roaring bitmaps
说到Roaring bitmaps,就必须先从bitmap说起。Bitmap是一种数据结构,假设有某个posting list:
[1,3,4,7,10]
对应的bitmap就是:
[1,0,1,1,0,0,1,0,0,1]
非常直观,用0/1表示某个值是否存在,比如10这个值就对应第10位,对应的bit值是1,这样用一个字节就可以代表8个文档id,旧版本(5.0之前)的Lucene就是用这样的方式来压缩的,但这样的压缩方式仍然不够高效,如果有1亿个文档,那么需要12.5MB的存储空间,这仅仅是对应一个索引字段(我们往往会有很多个索引字段)。于是有人想出了Roaring bitmaps这样更高效的数据结构。
Bitmap的缺点是存储空间随着文档个数线性增长,Roaring bitmaps需要打破这个魔咒就一定要用到某些指数特性:
将posting list按照65535为界限分块,比如第一块所包含的文档id范围在0~65535之间,第二块的id范围是65536~131071,以此类推。再用<商,余数>的组合表示每一组id,这样每组里的id范围都在0~65535内了,剩下的就好办了,既然每组id不会变得无限大,那么我们就可以通过最有效的方式对这里的id存储。
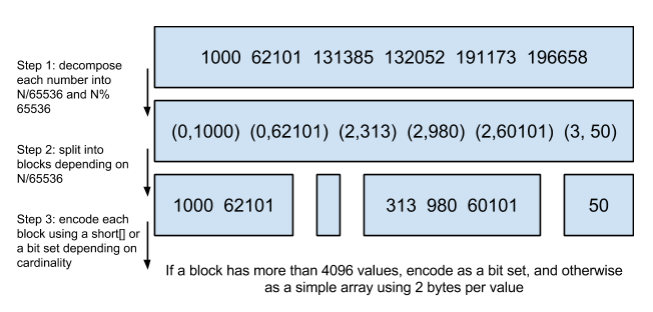
细心的小明这时候又举手了:"为什么是以65535为界限?"
程序员的世界里除了1024外,65535也是一个经典值,因为它=2^16-1,正好是用2个字节能表示的最大数,一个short的存储单位,注意到上图里的最后一行“If a block has more than 4096 values, encode as a bit set, and otherwise as a simple array using 2 bytes per value”,如果是大块,用节省点用bitset存,小块就豪爽点,2个字节我也不计较了,用一个short[]存着方便。
那为什么用4096来区分大块还是小块呢?
个人理解:都说程序员的世界是二进制的,4096*2bytes = 8192bytes < 1KB, 磁盘一次寻道可以顺序把一个小块的内容都读出来,再大一位就超过1KB了,需要两次读。
联合索引
上面说了半天都是单field索引,如果多个field索引的联合查询,倒排索引如何满足快速查询的要求呢?
- 利用跳表(Skip list)的数据结构快速做“与”运算,或者
- 利用上面提到的bitset按位“与”
先看看跳表的数据结构:
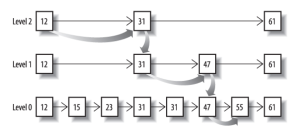
将一个有序链表level0,挑出其中几个元素到level1及level2,每个level越往上,选出来的指针元素越少,查找时依次从高level往低查找,比如55,先找到level2的31,再找到level1的47,最后找到55,一共3次查找,查找效率和2叉树的效率相当,但也是用了一定的空间冗余来换取的。
假设有下面三个posting list需要联合索引:
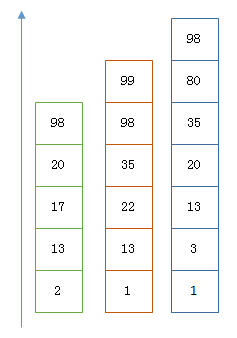
如果使用跳表,对最短的posting list中的每个id,逐个在另外两个posting list中查找看是否存在,最后得到交集的结果。
如果使用bitset,就很直观了,直接按位与,得到的结果就是最后的交集。
总结和思考
Elasticsearch的索引思路:
将磁盘里的东西尽量搬进内存,减少磁盘随机读取次数(同时也利用磁盘顺序读特性),结合各种奇技淫巧的压缩算法,用及其苛刻的态度使用内存。
所以,对于使用Elasticsearch进行索引时需要注意:
- 不需要索引的字段,一定要明确定义出来,因为默认是自动建索引的
- 同样的道理,对于String类型的字段,不需要analysis的也需要明确定义出来,因为默认也是会analysis的
- 选择有规律的ID很重要,随机性太大的ID(比如java的UUID)不利于查询
关于最后一点,个人认为有多个因素:
其中一个(也许不是最重要的)因素: 上面看到的压缩算法,都是对Posting list里的大量ID进行压缩的,那如果ID是顺序的,或者是有公共前缀等具有一定规律性的ID,压缩比会比较高;
另外一个因素: 可能是最影响查询性能的,应该是最后通过Posting list里的ID到磁盘中查找Document信息的那步,因为Elasticsearch是分Segment存储的,根据ID这个大范围的Term定位到Segment的效率直接影响了最后查询的性能,如果ID是有规律的,可以快速跳过不包含该ID的Segment,从而减少不必要的磁盘读次数,具体可以参考这篇如何选择一个高效的全局ID方案(评论也很精彩)
Elasticsearch是如何实现Master选举的?
- Elasticsearch的选主是ZenDiscovery模块负责的,主要包含Ping(节点之间通过这个RPC来发现彼此)和Unicast(单播模块包含一个主机列表以控制哪些节点需要ping通)这两部分;
- 对所有可以成为master的节点(node.master: true)根据nodeId字典排序,每次选举每个节点都把自己所知道节点排一次序,然后选出第一个(第0位)节点,暂且认为它是master节点。
- 如果对某个节点的投票数达到一定的值(可以成为master节点数n/2+1)并且该节点自己也选举自己,那这个节点就是master。否则重新选举一直到满足上述条件。
- 补充:master节点的职责主要包括集群、节点和索引的管理,不负责文档级别的管理;data节点可以关闭http功能。
Elasticsearch中的节点(比如共20个),其中的10个选了一个master,另外10个选了另一个master,怎么办?
- 当集群master候选数量不小于3个时,可以通过设置最少投票通过数量(discovery.zen.minimum_master_nodes)超过所有候选节点一半以上来解决脑裂问题;
- 当候选数量为两个时,只能修改为唯一的一个master候选,其他作为data节点,避免脑裂问题。
客户端在和集群连接时,如何选择特定的节点执行请求的?
- TransportClient利用transport模块远程连接一个elasticsearch集群。它并不加入到集群中,只是简单的获得一个或者多个初始化的transport地址,并以 轮询 的方式与这些地址进行通信。
详细描述一下Elasticsearch索引文档的过程。
- 协调节点默认使用文档ID参与计算(也支持通过routing),以便为路由提供合适的分片。
shard = hash(document_id) % (num_of_primary_shards)
- 当分片所在的节点接收到来自协调节点的请求后,会将请求写入到Memory Buffer,然后定时(默认是每隔1秒)写入到Filesystem Cache,这个从Momery Buffer到Filesystem Cache的过程就叫做refresh;
- 当然在某些情况下,存在Momery Buffer和Filesystem Cache的数据可能会丢失,ES是通过translog的机制来保证数据的可靠性的。其实现机制是接收到请求后,同时也会写入到translog中,当Filesystem cache中的数据写入到磁盘中时,才会清除掉,这个过程叫做flush;
- 在flush过程中,内存中的缓冲将被清除,内容被写入一个新段,段的fsync将创建一个新的提交点,并将内容刷新到磁盘,旧的translog将被删除并开始一个新的translog。
- flush触发的时机是定时触发(默认30分钟)或者translog变得太大(默认为512M)时;

补充:关于Lucene的Segement:
- Lucene索引是由多个段组成,段本身是一个功能齐全的倒排索引。
- 段是不可变的,允许Lucene将新的文档增量地添加到索引中,而不用从头重建索引。
- 对于每一个搜索请求而言,索引中的所有段都会被搜索,并且每个段会消耗CPU的时钟周、文件句柄和内存。这意味着段的数量越多,搜索性能会越低。
- 为了解决这个问题,Elasticsearch会合并小段到一个较大的段,提交新的合并段到磁盘,并删除那些旧的小段。
详细描述一下Elasticsearch更新和删除文档的过程。
- 删除和更新也都是写操作,但是Elasticsearch中的文档是不可变的,因此不能被删除或者改动以展示其变更;
- 磁盘上的每个段都有一个相应的.del文件。当删除请求发送后,文档并没有真的被删除,而是在.del文件中被标记为删除。该文档依然能匹配查询,但是会在结果中被过滤掉。当段合并时,在.del文件中被标记为删除的文档将不会被写入新段。
- 在新的文档被创建时,Elasticsearch会为该文档指定一个版本号,当执行更新时,旧版本的文档在.del文件中被标记为删除,新版本的文档被索引到一个新段。旧版本的文档依然能匹配查询,但是会在结果中被过滤掉。
详细描述一下Elasticsearch搜索的过程。
- 搜索被执行成一个两阶段过程,我们称之为 Query Then Fetch;
- 在初始查询阶段时,查询会广播到索引中每一个分片拷贝(主分片或者副本分片)。 每个分片在本地执行搜索并构建一个匹配文档的大小为 from + size 的优先队列。PS:在搜索的时候是会查询Filesystem Cache的,但是有部分数据还在Memory Buffer,所以搜索是近实时的。
- 每个分片返回各自优先队列中 所有文档的 ID 和排序值 给协调节点,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表。
- 接下来就是 取回阶段,协调节点辨别出哪些文档需要被取回并向相关的分片提交多个 GET 请求。每个分片加载并 丰富 文档,如果有需要的话,接着返回文档给协调节点。一旦所有的文档都被取回了,协调节点返回结果给客户端。
- 补充:Query Then Fetch的搜索类型在文档相关性打分的时候参考的是本分片的数据,这样在文档数量较少的时候可能不够准确,DFS Query Then Fetch增加了一个预查询的处理,询问Term和Document frequency,这个评分更准确,但是性能会变差。

在Elasticsearch中,是怎么根据一个词找到对应的倒排索引的?
SEE:
Elasticsearch在部署时,对Linux的设置有哪些优化方法?
- 64 GB 内存的机器是非常理想的, 但是32 GB 和16 GB 机器也是很常见的。少于8 GB 会适得其反。
- 如果你要在更快的 CPUs 和更多的核心之间选择,选择更多的核心更好。多个内核提供的额外并发远胜过稍微快一点点的时钟频率。
- 如果你负担得起 SSD,它将远远超出任何旋转介质。 基于 SSD 的节点,查询和索引性能都有提升。如果你负担得起,SSD 是一个好的选择。
- 即使数据中心们近在咫尺,也要避免集群跨越多个数据中心。绝对要避免集群跨越大的地理距离。
- 请确保运行你应用程序的 JVM 和服务器的 JVM 是完全一样的。 在 Elasticsearch 的几个地方,使用 Java 的本地序列化。
- 通过设置gateway.recover_after_nodes、gateway.expected_nodes、gateway.recover_after_time可以在集群重启的时候避免过多的分片交换,这可能会让数据恢复从数个小时缩短为几秒钟。
- Elasticsearch 默认被配置为使用单播发现,以防止节点无意中加入集群。只有在同一台机器上运行的节点才会自动组成集群。最好使用单播代替组播。
- 不要随意修改垃圾回收器(CMS)和各个线程池的大小。
- 把你的内存的(少于)一半给 Lucene(但不要超过 32 GB!),通过ES_HEAP_SIZE 环境变量设置。
- 内存交换到磁盘对服务器性能来说是致命的。如果内存交换到磁盘上,一个 100 微秒的操作可能变成 10 毫秒。 再想想那么多 10 微秒的操作时延累加起来。 不难看出 swapping 对于性能是多么可怕。
- Lucene 使用了大量的文件。同时,Elasticsearch 在节点和 HTTP 客户端之间进行通信也使用了大量的套接字。 所有这一切都需要足够的文件描述符。你应该增加你的文件描述符,设置一个很大的值,如 64,000。
补充:索引阶段性能提升方法
- 使用批量请求并调整其大小:每次批量数据 5–15 MB 大是个不错的起始点。
- 存储:使用 SSD
- 段和合并:Elasticsearch 默认值是 20 MB/s,对机械磁盘应该是个不错的设置。如果你用的是 SSD,可以考虑提高到 100–200 MB/s。如果你在做批量导入,完全不在意搜索,你可以彻底关掉合并限流。另外还可以增加 index.translog.flush_threshold_size 设置,从默认的 512 MB 到更大一些的值,比如 1 GB,这可以在一次清空触发的时候在事务日志里积累出更大的段。
- 如果你的搜索结果不需要近实时的准确度,考虑把每个索引的index.refresh_interval 改到30s。
- 如果你在做大批量导入,考虑通过设置index.number_of_replicas: 0 关闭副本。
对于GC方面,在使用Elasticsearch时要注意什么?
- SEE:https://elasticsearch.cn/article/32
- 倒排词典的索引需要常驻内存,无法GC,需要监控data node上segment memory增长趋势。
- 各类缓存,field cache, filter cache, indexing cache, bulk queue等等,要设置合理的大小,并且要应该根据最坏的情况来看heap是否够用,也就是各类缓存全部占满的时候,还有heap空间可以分配给其他任务吗?避免采用clear cache等“自欺欺人”的方式来释放内存。
- 避免返回大量结果集的搜索与聚合。确实需要大量拉取数据的场景,可以采用scan & scroll api来实现。
- cluster stats驻留内存并无法水平扩展,超大规模集群可以考虑分拆成多个集群通过tribe node连接。
- 想知道heap够不够,必须结合实际应用场景,并对集群的heap使用情况做持续的监控。
Elasticsearch对于大数据量(上亿量级)的聚合如何实现?
- Elasticsearch 提供的首个近似聚合是cardinality 度量。它提供一个字段的基数,即该字段的distinct或者unique值的数目。它是基于HLL算法的。HLL 会先对我们的输入作哈希运算,然后根据哈希运算的结果中的 bits 做概率估算从而得到基数。其特点是:可配置的精度,用来控制内存的使用(更精确 = 更多内存);小的数据集精度是非常高的;我们可以通过配置参数,来设置去重需要的固定内存使用量。无论数千还是数十亿的唯一值,内存使用量只与你配置的精确度相关。
在并发情况下,Elasticsearch如果保证读写一致?
- 可以通过版本号使用乐观并发控制,以确保新版本不会被旧版本覆盖,由应用层来处理具体的冲突;
- 另外对于写操作,一致性级别支持quorum/one/all,默认为quorum,即只有当大多数分片可用时才允许写操作。但即使大多数可用,也可能存在因为网络等原因导致写入副本失败,这样该副本被认为故障,分片将会在一个不同的节点上重建。
- 对于读操作,可以设置replication为sync(默认),这使得操作在主分片和副本分片都完成后才会返回;如果设置replication为async时,也可以通过设置搜索请求参数_preference为primary来查询主分片,确保文档是最新版本。
如何监控Elasticsearch集群状态?
- Marvel 让你可以很简单的通过 Kibana 监控 Elasticsearch。你可以实时查看你的集群健康状态和性能,也可以分析过去的集群、索引和节点指标。
介绍下你们电商搜索的整体技术架构。

介绍一下你们的个性化搜索方案?
SEE 基于word2vec和Elasticsearch实现个性化搜索
是否了解字典树?
- 常用字典数据结构如下所示:

- Trie的核心思想是空间换时间,利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。它有3个基本性质:
根节点不包含字符,除根节点外每一个节点都只包含一个字符。
从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
每个节点的所有子节点包含的字符都不相同。

- 可以看到,trie树每一层的节点数是26^i级别的。所以为了节省空间,我们还可以用动态链表,或者用数组来模拟动态。而空间的花费,不会超过单词数×单词长度。
- 实现:对每个结点开一个字母集大小的数组,每个结点挂一个链表,使用左儿子右兄弟表示法记录这棵树;
- 对于中文的字典树,每个节点的子节点用一个哈希表存储,这样就不用浪费太大的空间,而且查询速度上可以保留哈希的复杂度O(1)。
拼写纠错是如何实现的?
- 拼写纠错是基于编辑距离来实现;编辑距离是一种标准的方法,它用来表示经过插入、删除和替换操作从一个字符串转换到另外一个字符串的最小操作步数;
- 编辑距离的计算过程:比如要计算batyu和beauty的编辑距离,先创建一个7×8的表(batyu长度为5,coffee长度为6,各加2),接着,在如下位置填入黑色数字。其他格的计算过程是取以下三个值的最小值:
如果最上方的字符等于最左方的字符,则为左上方的数字。否则为左上方的数字+1。(对于3,3来说为0)
左方数字+1(对于3,3格来说为2)
上方数字+1(对于3,3格来说为2)
最终取右下角的值即为编辑距离的值3。

- 对于拼写纠错,我们考虑构造一个度量空间(Metric Space),该空间内任何关系满足以下三条基本条件:
d(x,y) = 0 -- 假如x与y的距离为0,则x=y
d(x,y) = d(y,x) -- x到y的距离等同于y到x的距离
d(x,y) + d(y,z) >= d(x,z) -- 三角不等式
- 根据三角不等式,则满足与query距离在n范围内的另一个字符转B,其与A的距离最大为d+n,最小为d-n。
- BK树的构造就过程如下:每个节点有任意个子节点,每条边有个值表示编辑距离。所有子节点到父节点的边上标注n表示编辑距离恰好为n。比如,我们有棵树父节点是”book”和两个子节点”cake”和”books”,”book”到”books”的边标号1,”book”到”cake”的边上标号4。从字典里构造好树后,无论何时你想插入新单词时,计算该单词与根节点的编辑距离,并且查找数值为d(neweord, root)的边。递归得与各子节点进行比较,直到没有子节点,你就可以创建新的子节点并将新单词保存在那。比如,插入”boo”到刚才上述例子的树中,我们先检查根节点,查找d(“book”, “boo”) = 1的边,然后检查标号为1的边的子节点,得到单词”books”。我们再计算距离d(“books”, “boo”)=2,则将新单词插在”books”之后,边标号为2。
- 查询相似词如下:计算单词与根节点的编辑距离d,然后递归查找每个子节点标号为d-n到d+n(包含)的边。假如被检查的节点与搜索单词的距离d小于n,则返回该节点并继续查询。比如输入cape且最大容忍距离为1,则先计算和根的编辑距离d(“book”, “cape”)=4,然后接着找和根节点之间编辑距离为3到5的,这个就找到了cake这个节点,计算d(“cake”, “cape”)=1,满足条件所以返回cake,然后再找和cake节点编辑距离是0到2的,分别找到cape和cart节点,这样就得到cape这个满足条件的结果。
