说一下Spring中bean的加载过程,BeanFactory和FactoryBean有什么区别
概述
Spring 作为 Ioc 框架,实现了依赖注入,由一个中心化的 Bean 工厂来负责各个 Bean 的实例化和依赖管理。各个 Bean 可以不需要关心各自的复杂的创建过程,达到了很好的解耦效果。
我们对 Spring 的工作流进行一个粗略的概括,主要为两大环节:
- 解析,读 xml 配置,扫描类文件,从配置或者注解中获取 Bean 的定义信息,注册一些扩展功能。
- 加载,通过解析完的定义信息获取 Bean 实例。
 我们假设所有的配置和扩展类都已经装载到了 ApplicationContext 中,然后具体的分析一下 Bean 的加载流程。
我们假设所有的配置和扩展类都已经装载到了 ApplicationContext 中,然后具体的分析一下 Bean 的加载流程。 - 作用域。单例作用域或者原型作用域,单例的话需要全局实例化一次,原型每次创建都需要重新实例化。
- 依赖关系。一个 Bean 如果有依赖,我们需要初始化依赖,然后进行关联。如果多个 Bean 之间存在着循环依赖,A 依赖 B,B 依赖 C,C 又依赖 A,需要解这种循环依赖问题。
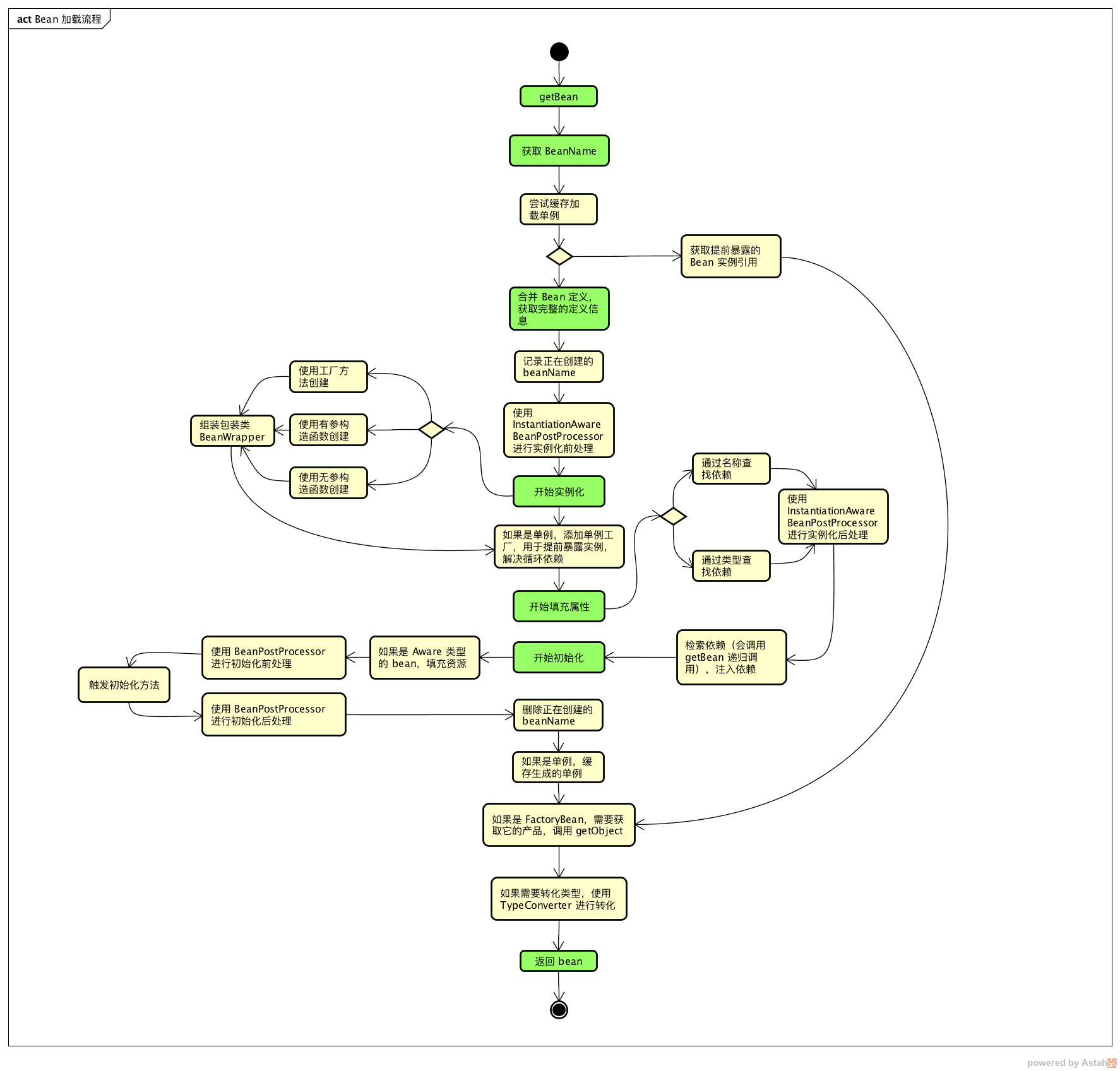
2. 总体流程
- 获取 BeanName,对传入的 name 进行解析,转化为可以从 Map 中获取到 BeanDefinition 的 bean name。
- 合并 Bean 定义,对父类的定义进行合并和覆盖,如果父类还有父类,会进行递归合并,以获取完整的 Bean 定义信息。
- 实例化,使用构造或者工厂方法创建 Bean 实例。
- 属性填充,寻找并且注入依赖,依赖的 Bean 还会递归调用
getBean方法获取。 - 初始化,调用自定义的初始化方法。
- 获取最终的 Bean,如果是 FactoryBean 需要调用 getObject 方法,如果需要类型转换调用 TypeConverter 进行转化。
BeanFactory与FactoryBean的区别
BeanFactory 以Factory结尾,表示它是一个工厂类,用于管理Bean的一个工厂
在Spring中,所有的Bean都是由BeanFactory(也就是IOC容器)来进行管理的。
但对FactoryBean而言,这个Bean不是简单的Bean,而是一个能生产或者修饰对象生成的工厂Bean,
它的实现与设计模式中的工厂模式和修饰器模式类似。
Synchronized的底层原理字节码层面如何实现加锁
应用方式
synchronized 是解决Java并发最常见的一种方法,也是最简单的一种方法。关键字 synchronized 可以保证在同一时刻,只有一个线程可以访问某个方法或者某个代码块。同时 synchronized 也可以保证一个线程的变化,被另一个线程看到(保证了可见性)
这里要注意:synchronized是一个互斥的 重量级锁 (细节部分后续会讲)
synchronized的作用主要有三个:
- 确保线程互斥的访问代码
- 保证共享变量的修改能够及时可见(可见性)
- 可以阻止JVM的指令重排序
在Java中所有对象都可以作为锁,这是synchronized实现同步的基础。
synchronized主要有三种应用方式:
- 普通同步方法,锁的是当前实例的对象
- 静态同步方法,锁的是静态方法所在的类对象
- 同步代码块,锁的是括号里的对象。(此处的可以是实例对象,也可以是类的class对象。)
原理概要
Java虚拟机中的同步(Synchronization)都是基于进入和退出Monitor对象实现,无论是显示同步(同步代码块)还是隐式同步(同步方法)都是如此。
-
同步代码块
monitorenter指令插入到同步代码块的开始位置。monitorexit指令插入到同步代码块结束的位置。JVM需要保证每一个monitorenter都有一个monitorexit与之对应。
任何对象,都有一个monitor与之相关联,当monitor被持有以后,它将处于锁定状态。线程执行到monitorenter指令时,会尝试获得monitor对象的所有权,即尝试获取锁。
虚拟机规范对 monitorenter 和 monitorexit 的行为描述中,有两点需要注意。首先 synchronized 同步快对于同一条线程来说是可重入的,也就是说,不会出现把自己锁死的问题。其次,同步快在已进入的线程执行完之前,会阻塞后面其他线程的进入。(摘自《深入理解JAVA虚拟机》)
-
同步方法
synchronized方法则会被翻译成普通的方法调用和返回指令如:invokevirtual、areturn指令,在VM字节码层面并没有任何特别的指令来实现被synchronized修饰的方法,而是在Class文件的方法表中将该方法的access_flags字段中的synchronized标志位置1,表示该方法是同步方法并使用调用该方法的对象或该方法所属的Class在JVM的内部对象表示Klass做为锁对象。
原理详解
要理解低层实现,就需要理解两个重要的概念 Monitor 和 Mark Word
- Java对象头
synchronized用到的锁,是存储在对象头中的。(这也是Java所有对象都可以上锁的根本原因)
HotSpot虚拟机中,对象头包括两部分信息:
Mark Word(对象头)和 Klass Pointer(类型指针)
- 其中类型指针,是对象指向它的类元素的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。
- 对象头又分为两部分:第一部分存储对象自身的运行时数据,例如哈希码,GC分代年龄,线程持有的锁,偏向时间戳等。这一部分的长度是不固定的。第二部分是末尾两位,存储锁标志位,表示当前锁的级别。
对象头的长度一般占用两个机器码(32位JVM中,一个机器码等于4个字节,也就是32bit),但如果对象是数组类型,则需要三个机器码(多出的一块记录数组长度)。
下图是对象头运行时的变化状态:
锁标志位 和 是否偏向锁 确定唯一的锁状态
其中 轻量锁 和 偏向锁 是JDK1.6之后新加的,用于对synchronized优化。稍后讲到

- Monitor
Monitor是 synchronized 重量级 锁的实现关键。锁的标识位为 10 。当然 synchronized作为一个重量锁是非常消耗性能的,所以在JDK1.6以后做了部分优化,接下来的部分是讲作为重量锁的实现。
Monitor是线程私有的数据结构,每一个对象都有一个monitor与之关联。每一个线程都有一个可用monitor record列表(当前线程中所有对象的monitor),同时还有一个全局可用列表(全局对象monitor)。每一个被锁住的对象,都会和一个monitor关联。
当一个monitor被某个线程持有后,它便处于锁定状态。此时,对象头中 MarkWord的 指向互斥量的指针,就是指向锁对象的monitor起始地址。
monitor是由 ObjectMonitor 实现的,其主要数据结构如下:(位于HotSpot虚拟机源码ObjectMonitor.hpp文件,C++实现的)
ObjectMonitor() {
_header = NULL;
_count = 0; //记录个数
_waiters = 0,
_recursions = 0;
_object = NULL;
_owner = NULL;
_WaitSet = NULL; //处于wait状态的线程,会被加入到_WaitSet
_WaitSetLock = 0 ;
_Responsible = NULL ;
_succ = NULL ;
_cxq = NULL ;
FreeNext = NULL ;
_EntryList = NULL ; //处于等待锁block状态的线程,会被加入到该列表
_SpinFreq = 0 ;
_SpinClock = 0 ;
OwnerIsThread = 0 ;
}
object monitor 有两个队列 _EntryList 和 _WaitSet ,用来保存ObjectWaiter对象列表(每个等待锁的线程都会被封装成ObjectWaiter对象)_owner 指向持有 objectMonitor的线程。
当多个线程同时访问一个同步代码时,首先会进入 _EntryList 集合,当线程获取到对象的monitor后,会进入_owner 区域,然后把monitor中的 _owner 变量修改为当前线程,同时monitor中的计数器_count 会加1。
根据虚拟机规范的要求,在执行monitorenter指令时,会尝试获取对象的锁。如果对象没有被锁定(获取锁),获取对象已经被该线程锁定(锁重入)。则把计数器加1(
_count加1)。相应的,在执行monitorexit指令时,会讲计数器减1。当计数器为0时,_owner指向Null,锁就被释放。(摘自《深入理解JAVA虚拟机》)
如果线程调用 wait() 方法,将释放当前持有的monitor,_owner变量恢复为null,_count变量减1,同时该线程进入_WaitSet 等待被唤醒。
底层实现
- synchronized 代码块低层原理
从Javac编译成的字节码可以看出(具体编译文件看参考链接),同步代码块使用的是monitorenter和monitorexit指令,其中monitorenter指向同步代码块的开始位置,monitorexit指向同步代码块的结束位置。
在线程执行到monitorenter指令时,当前线程将尝试获取锁,即尝试获取锁对象对应的monitor的持有权。当monitor的count计数器为0,或者monitor的owner已经是该线程,则获取锁,count计数器+1。
如果其他线程已经持有该对象的锁,则该线程被阻塞,直到其他线程执行完毕释放锁。
线程执行完毕时,count归零,owner指向Null,锁释放。
值得注意的是,编译器将会确保,无论通过何种方法完成,方法中的每一条monitorenter指令,最终都会有monitorexit指令对应,不论这个方法正常结束还是异常结束,最终都会配对执行。
编译器会自动产生一个异常处理器,这个处理器声明可以处理所有的异常,它的目的就是为了确保monitorexit指令最终执行。
- synchronized 方法低层原理
方法级的同步是隐式,即无需通过字节码来控制的,它实现在方法调用和返回操作中。
在Class文件方法常量池中的方法表结构(method_info Structure)中, ACC_SYNCHRONIZED 访问标志区分一个方法是否为同步方法。在方法被调用时,会检查方法的 ACC_SYNCHRONIZED 标记是否被设置。如果被设置了,则线程将持有该方法对应对象的monitor(调用方法的实例对象or静态方法的类对象),然后再执行该方法。
最后在方法执行完成时,释放monitor。
在方法执行期间,执行线程持有了monitor,其他任何线程都无法再获得同一个monitor。
以下是字节码实现:
public class SyncMethod {
public int i;
public synchronized void syncTask(){
i++;
}
}
使用javap反编译后的字节码如下:
Classfile /Users/zejian/Downloads/Java8_Action/src/main/java/com/zejian/concurrencys/SyncMethod.class
Last modified 2017-6-2; size 308 bytes
MD5 checksum f34075a8c059ea65e4cc2fa610e0cd94
Compiled from "SyncMethod.java"
public class com.zejian.concurrencys.SyncMethod
minor version: 0
major version: 52
flags: ACC_PUBLIC, ACC_SUPER
Constant pool;
//省略没必要的字节码
//==================syncTask方法======================
public synchronized void syncTask();
descriptor: ()V
//方法标识ACC_PUBLIC代表public修饰,ACC_SYNCHRONIZED指明该方法为同步方法
flags: ACC_PUBLIC, ACC_SYNCHRONIZED
Code:
stack=3, locals=1, args_size=1
0: aload_0
1: dup
2: getfield #2 // Field i:I
5: iconst_1
6: iadd
7: putfield #2 // Field i:I
10: return
LineNumberTable:
line 12: 0
line 13: 10
}
SourceFile: "SyncMethod.java"
从字节码可以看出,synchronized修饰的方法并没有monitorenter和monitorexit指令。而是用ACC_SYNCHRONIZED的flag标记该方法是否是同步方法,从而执行相应的同步调用。
ReentrantLock如何实现非公平锁的“非公平锁”与“公平锁”区别
1 ReentrantLock和synchronized区别
(1) synchronized 是Java的一个内置关键字,而ReentrantLock是Java的一个类。
(2) synchronized只能是非公平锁。而ReentrantLock可以实现公平锁和非公平锁两种。
(3) synchronized不能中断一个等待锁的线程,而Lock可以中断一个试图获取锁的线程。
(4) synchronized不能设置超时,而Lock可以设置超时。
(5) synchronized会自动释放锁,而ReentrantLock不会自动释放锁,必须手动释放,否则可能会导致死锁。
2 公平锁和非公平锁的区别
(1) 线程在获取锁调用lock()时,非公平锁首先会进行一次CAS尝试抢锁,如果此时没有线程持有锁或者正好此刻有线程执行完释放了锁(state == 0),那么如果CAS成功则直接占用锁返回。
(2) 如果非公平锁在上一步获取锁失败了,那么就会进入nonfairTryAcquire(int
acquires),在该方法里,如果state的值为0,表示当前没有线程占用锁或者刚好有线程释放了锁,那么就会CAS抢锁,如果抢成功了,就直接返回了,不管是不是有其他线程早就到了在阻塞队列中等待锁了。而公平锁在这里抢到锁了,会判断阻塞队列是不是空的,毕竟要公平就要讲先来后到,如果发现阻塞队列不为空,表示队列中早有其他线程在等待了,那么公平锁情况下线程会乖乖排到阻塞队列的末尾。
如果非公平锁 (1)(2) 都失败了,那么剩下的过程就和非公平锁一样了。
(3) 从(1)(2) 可以看出,非公平锁可能导致线程饥饿,但是非公平锁的效率要高。
concurrentHashmap是安全的吗,concurrentHashmap的size怎么求
并发场景下,需要怎么设定锁
mysql用什么索引
Mysql目前主要有以下几种索引类型:FULLTEXT,HASH,BTREE,RTREE。
1. FULLTEXT
即为全文索引,目前只有MyISAM引擎支持。其可以在CREATE TABLE ,ALTER TABLE ,CREATE INDEX 使用,不过目前只有 CHAR、VARCHAR ,TEXT 列上可以创建全文索引。
全文索引并不是和MyISAM一起诞生的,它的出现是为了解决WHERE name LIKE “%word%"这类针对文本的模糊查询效率较低的问题。
2. HASH
由于HASH的唯一(几乎100%的唯一)及类似键值对的形式,很适合作为索引。
HASH索引可以一次定位,不需要像树形索引那样逐层查找,因此具有极高的效率。但是,这种高效是有条件的,即只在“=”和“in”条件下高效,对于范围查询、排序及组合索引仍然效率不高。
3. BTREE
BTREE索引就是一种将索引值按一定的算法,存入一个树形的数据结构中(二叉树),每次查询都是从树的入口root开始,依次遍历node,获取leaf。这是MySQL里默认和最常用的索引类型。
4. RTREE
RTREE在MySQL很少使用,仅支持geometry数据类型,支持该类型的存储引擎只有MyISAM、BDb、InnoDb、NDb、Archive几种。
相对于BTREE,RTREE的优势在于范围查找。
B+树为什么索引快(B+树优点)
- B+树的高度一般为2-4层,所以查找记录时最多只需要2-4次IO,相对二叉平衡树已经大大降低了。
- 范围查找时,能通过叶子节点的指针获取数据。例如查找大于等于3的数据,当在叶子节点中查到3时,通过3的尾指针便能获取所有数据,而不需要再像二叉树一样再获取到3的父节点。
幻读是什么,Innodb如何避免幻读
innodb下的幻读是由MVCC 或者 GAP 锁 或者是next-key lock 解决的
间隙锁的锁定范围是多少
JVM内存模型
gc的种类 mingc和fullgc的区别,什么时候发生gc
新生代 GC(Minor GC):指发生在新生代的垃圾收集动作,因为 Java 对象大多都具
备朝生夕灭的特性,所以 Minor GC 非常频繁,一般回收速度也比较快。
老年代 GC(Major GC / Full GC):指发生在老年代的 GC,出现了 Major GC,经常
会伴随至少一次的 Minor GC(但非绝对的,在 ParallelScavenge 收集器的收集策略里
就有直接进行 Major GC 的策略选择过程) 。MajorGC 的速度一般会比 Minor GC 慢 10
倍以上。
Minor GC触发机制:
当年轻代满时就会触发Minor GC,这里的年轻代满指的是Eden代满,Survivor满不会引发GC。
Full GC触发机制:
(1)调用System.gc时,系统建议执行Full GC,但是不必然执行
(2)老年代空间不足
(3)方法区空间不足
(4)通过Minor GC后进入老年代的平均大小大于老年代的可用内存
(5)由Eden区、survivor space1(From Space)区向survivor space2(To Space)区复制时,对象大小大于To Space可用内存,则把该对象转存到老年代,且老年代的可用内存小于该对象大小
当永久代满时也会引发Full GC,会导致Class、Method元信息的卸载。
volatile底层实现
多核cpu在cpu级别怎么做到可见性
hashmap和concurrenthashmap的区别与实现
Hashmap本质是数组加链表。根据key取得hash值,然后计算出数组下标,如果多个key对应到同一个下标,就用链表串起来,新插入的在前面。
ConcurrentHashMap:在hashMap的基础上,ConcurrentHashMap将数据分为多个segment(段),默认16个(concurrency level),然后每次操作对一个segment(段)加锁,避免多线程锁的几率,提高并发效率。
HashMap不是线程安全的,而ConcurrentHashMap是线程安全的
string stringbuffer stringbuilder区别及实现