SVM全称是Support Vector Machine,即支持向量机,是一种监督式学习算法。它主要应用于分类问题,通过改进代码也可以用作回归。所谓支持向量就是距离分隔面最近的向量。支持向量机就是要确保这些支持向量距离超平面尽可能的远以保证模型具有相当的泛化能力。
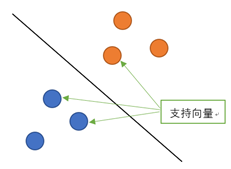
当训练数据线性可分时,通过硬间隔最大化,学习一个线性分类器,即线性可分支持向量机;当训练数据近似线性可分时,通过软间隔最大化,也学习一个线性分类器,即线性支持向量机;当训练数据线性不可分时,通过使用核技巧,将低维度的非线性问题转化为高维度下的线性问题,学习得到非线性支持向量机。
所谓核技巧就是将低维数据映射到高维空间的办法。如果原始数据是有限维的,那么一定存在一个高维特征空间使样本可分。

支持向量机的一些证明推导公式不在这里说明。我简单说明一下支持向量机在Python中的实现。
在Python中sklearn算法包已经实现了所有基本机器学习的算法。直接from sklearn import svm就可以调用该算法。
以Iris数据集为例,从UCI数据库(archive.ics.uci.edu)中下载的data文件比较工整,无需做进一步处理可以直接使用。
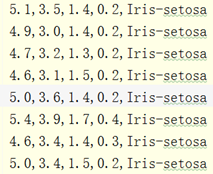
从网上其他地方下载下来的csv格式数据集可能比较混乱,如下图:

这种有样本序号有列名的数据集需要预处理一下才方便做实验。处理时需要导入pandas,将csv格式转换成便于处理的DataFrame格式。

其中names是设置列名称。
然后是使用drop方法消除原数据集中的第一行(列名称)以及第一列(样本序号)。

其中('a',axis=1)代表消除的是列名称为a的一整列。(0 ,axis=0)代表消除第0行。
最后使用to_csv方法输出文件即可处理完毕。

其中'newiris.csv'是指生成文件名,sep指的是分割符号(空格为 ),index为行索引(即序列号),header为列名称。
处理结果如下:

接下来开始SVM实验。首先读取我们刚才处理好的数据集。具体方法是使用numpy中的loadtxt方法此方法可以读取txt、csv、data格式的数据。

第一个位置path指的文件路径,dtype指的是读出来的数据类型,delimiter指的是分隔符,converters指的是将数据列与转换函数进行映射的字典。
我们数据的第五列显然不是float类型,因此要写一个函数进行转换。

读取后的结果如下:

接下来需要将读取到的数据集特征指标与结果分开,并划分为训练集与测试集,此处为了方便作图只取了前两列特征值做实验:

其中size指的是样本数量,若此数小于1表示样本比例,大于1的整数表示样本数量。random_state指的是随机数的种子。
准备好后就可以开始训练SVM了。

kernel指的是核函数rbf是高斯核。高斯核的gamma值越小,分类界面越连续;gamma值越大,分类界面越“散”,分类效果越好,但有可能会过拟合。linear为线性核。线性核C越大分类效果越好,但有可能会过拟合。
decision_function_shape有两个取值,一个是ovr,即一个类别与其他类别进行划分;另一个是ovo,即将类别两两之间进行划分,用二分类的方法模拟多分类的结果。
最后用测试集去查看分类准确度,此处可以直接调用score方法查看准确度,也可以调用sklearn中metrics的accuracy_scor方法查看。两者没有区别。

结果为0.7333333。结果不尽如人意但可以慢慢改参数改进。
最后绘制图片:

可以看到绿点几乎可以被很好的区分,但是蓝点和红点存在不易区分的地方。这时候调整核技巧或者将更多的特征属性加入学习可能会有更好的效果。