一种安全的云存储方案设计(未完整理中)
一篇老文了,现在看看错漏颇多,提到的一些技术已经跟不上了。仅对部分内容重新做了一些修正,增加了一些机器学习的内容,然并卵。
这几年来,云产品层出不穷,但其安全性一直饱受诟病。这篇博文以数据隐私安全为核心,从用户需求着手,讨论云存储的安全实现问题。
因为设计问题较多,我将内容拆分为两篇,最终会得到一套较为安全且高效易用的云存储加密系统的完整设计,该系统具有以下特征:1 使用机器学习的技术进行图片内容标注和文本分类,最终实现图文混合检索功能;2 所有文档数据对云服务平台透明,加密解密过程在本地完成,全程保证用户数据安全;3 用户数据可以在不泄露明文和整体加密策略的前提下分享给其他用户;4 可以对云端的图片和数据在密文进行模糊查询;5 系统通过多次迭代返回,不断调整参数,优化搜索结果准确度。
系统设计总览
考虑到云服务商本身可能并不可信,同时防止黑客攻破云服务系统后数据泄露,数据明文不能静态存储于云端。系统在上传用户文件前将本地加密数据。因此用户将云端数据下载到本地时,最初得到的是密文数据。用户间进行数据分享时,直接分享云端存储的加密数据。
为实现加密数据的查询功能,系统设计了搜索操作模块。其核心是一个密文索引库。同样,出于安全考虑明文检索的操作放在本地完成。索引会在关键字加密后上传至云端,与云端索引完成合并。而在用户搜索时,系统采用密文对密文的查询,放在云端完成。系统支持模糊查询功能,搜索操作模块根据相似度排名返回加密后的相关文件信息,用户解密后选择下载。
系统检索前将对文档进行预处理,之后会使用机器学习的技术进行图片内容标注和文本分类,支持混合检索。在一些应用场景下,用户的待检索资料可能是手机拍摄的图文混合文档,本系统将使用 FastR-CNN 算法先对图片进行分割和标注,对其中的文字部分调用 OCR 接口文字识别,然后再进行图文混合检索。但是 OCR 识别的文字往往不够准确,这也就使得系统所支持的模糊查询功能更加重要。
虽然经过不同调试,系统的模糊查询结果已经较为优异,但是在密文基础上模糊查询效果远不如明文。本模型会在云端密文模糊查询的基础上,将匹配结果列表和对应文件的检索摘要下载本地,解密后进行本地的二次明文模糊查询得到最终结果。同时系统还将通过对比二次查询的差异,对首次密文模糊查询系统的参数进行反馈,其中包括削弱部分常见词根的权值。通过多次迭代学习最终达到提高模糊匹配精度的结果。
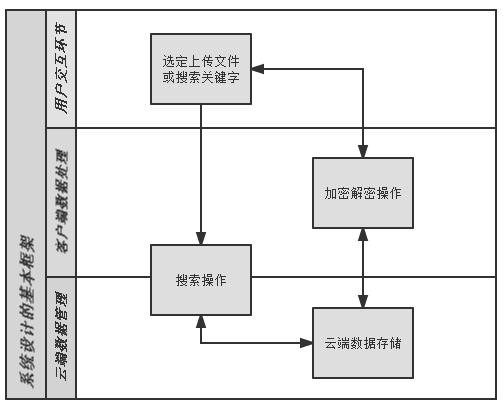
安全云存储加密管理框架设计
本系统设计的核心是本地客户端的数据加密解密操作。客户端与云端之间仅进行密文传输。同时用户可直接对云端数据进行安全分享。
密钥管理
本系统采用将密钥分散管理的策略,使用用户口令和随机信息生成二次加密密钥,加密初次加密信息,之后与初次加密后的数据封装在一起上传,避免了密钥的集中存储。这种策略的另一好处是,在进行数据分享时不存在使用属性加密或代理重加密分享方案时对云服务商的依赖性,更安全高效。
加密的处理流程
1)检查本批次预上传的文件,对文件进行分割,并使用 AES、Triple-DES、RSA 或其它设定的安全加密方式进行加密。密钥可由恰当的随机数生成器生成。初次加密时,可采用任意加密方式和密钥,但不同数据块的加密策略不应完全相同。加密、解密的密钥和相关信息将在之后进行二次加密。
2)借鉴本地数据加密软件 TrueCrypt 的策略,使用 PBKDF2 生成二次加密的密钥。其主要推导公式是:
DK = PBKDF 2(P, S, C, dkLen)
其中 DK 是最终导出密钥,参数 P 是口令(字节串),参数 S 是“盐”(字节串),参数 C(数字)是迭代次数,参数 dkLen 是导出密钥的长度。
3)确认以上各参数,导出二次加密密钥。口令是用户加密数据的加密口令,由用户负责;“盐”是每次加密随机生成的字节串,参与生成密钥后将存储于云端文件索引系统中,由索引系统负责加密(本地完成);迭代次数和导出密钥的长度,以及二次加密的具体算法,可根据对系统安全性的需求一次性确定。
4)使用二次加密密钥对初次加密的密钥文件和其他加密信息进行二次加密。然后与加密的文件数据拼接,等待上传。
5)为了提高系统安全性,系统在每次加密前都可以在制定字节位置填充冗余数据。

在这种策略下,每块加密数据两次加密的最终密码钥都是唯一的,部分数据被破解解密对系统中其他文件的安全影响很小。同时,因为文件在加密前可以进行切割操作,每个文件不同数据块使用不同密钥二次加密,暴力破解难度极大。
搜索解密文件的处理流程
1)用户确认下载某个文件。
2)从云端获取的“盐”和用户的数据加密口令,从 PBKDF2 密钥生成程序中导出二次加密时使用的密钥,解密下载数据,获取初次加密信息。
4)根据初次加密信息,解密获得最终文件,并按需合并。
数据安全分享的处理流程
1)用户通过索引系统确认需要分享的文件,指定要分享的用户。
2)从索引结果中获得该文件下载地址和“盐”。获取对方用户的分享加密公钥。
3)用新获取的“盐”和用户的数据加密口令,从 PBKDF2 密钥生成程序中导出二次加密时使用的密钥。用对方的公钥加密文件下载地址和二次加密时使用的对称密钥,并发给对方。
4)对方用户收到分享的数据后,用分享加密私钥解密,获取初次加密信息和下载地址。
5)下载文件,按初次加密信息解密,合并文件。

由于每个文件初次加密和二次加密的密钥都不相同,只要不泄露密钥的推导算法和每个文件对应加密参数。仅将指定文件解密信息透露给用户,对系统整体安全不构成威胁。
基于机器学习的图片标注和文本分类
系统检索会对待检索资料进行格式化,我们考虑到用户的待检索资料可能是图文混合的网页或 pdf 文档,甚至是手机拍摄的图文混合照片(情报工作)。纯文字部分我们可以直接使用常规方法检索,针对更复杂的情况,将使用 Fast R-CNN 算法先对图片进行识别和标注,对其中的文字部分调用 OCR 接口文字识别,然后再进行图文混合检索。
另一方面,搜索的触发形式往往来自于一次或一组关键字查询,当被检索资源较多时,返回的结果可能是包含关键字的不同类型的文档,用户可能希望能对这些结果进行筛选,我们综合比较 KNN 算法和朴素贝叶斯算法后,选取后者对文档进行分类。增加文档的类别属性,以便于后续返回搜索结果后的筛选。我们也可以预见,如果分类的准确性较高,不同类别文档有一定的典型性,我们在之后的检索中可以对不同类型的文档采取不同的索引创建方式,控制索引文件的大小和提高搜索结果的精度。

基于 Fast R-CNN 的图片标注
FastRCNN 是 Ross Girshick 在 RCNN 的基础上增加了 Multi task training。整个的训练过程和测试过程比 RCNN 快了许多。算法通过以下三步实现:
1.用 selective search 在一张图片中生成约 2000 个 object proposal,即 RoI。2.把它们整体输入到全卷积的网络中,在最后一个卷积层上对每个 ROI 求映射关系,并用一个 RoI pooling
layer 来统一到相同的大小-> (fc)feature vector 即提取一个固定维度的特征表示。
3.继续经过两个全连接层(FC)得到特征向量。特征向量经由各自的 FC 层,得到两个输出向量:第一个是分类,使用 softmax,第二个是每一类的 bounding box 回归。
CNN、R-CNN、Fast R-CNN
CNN,即卷积神经网络是在 BP 神经网络的基础上的改进,有三个重要的思想架构:局部区域感知、权重共享、空间或时间上的采样。特征的提取通过多次卷积操作实现,最终得到一个特征向量,用于以后的 SVM。

为了更好地实现图片识别,R-CNN 在此之上有了两点改进 1:可以将卷积神经网络应用 region proposal 的策略,自底下上训练可以用来定位目标物和图像分割 2:当标注数据是比较稀疏的时候,在有监督的数据集上训练之后到特定任务的数据集上 fine-tuning 可以得到较好的新能,也就是说可以通过 fine-tuning Imagenet 上训练好的模型,快速获取自己训练数据的模型。

Fast R-CNN 在此基础上做了进一步改进,克服了三大问题。R-CNN 训练的时候,除了先生成 Proposal,要先做 CNN 提取特征,之后用 SVM 分类器,最后再做 bbox regression。Fast R-CNN 实现了 end-to-end 的连续训练。
R-CNN 训练时间和空间开销大。所以 Fast R-CNN 用了 image-centric 的训练方式来通过卷积的 share特性来降低运算开销;Fast R-CNN 提取特征给 SVM 训练时候需要中间要大量的磁盘空间存放特征,Fast R-CNN 也去掉了 SVM 这一步。

如图所示,训练过程可以理解为:selective search 在一张图片中得到大量(两千)object proposal(RoI)
缩放图片的 scale 得到图片金字塔,FP 得到 convN 的特征金字塔。对于每个 scale 的每个 ROI,求取映射关系,在 convN 中 crop 出对应的 patch。并用一个单层的 SPP layer(Rol pooling layer)来统一到一样的尺度。继续经过两个全连接得到特征,这特征有分别 share 到两个新的全连接,连接上两个优化目标。
第一个优化目标是分类,使用 softmax,第二个优化目标是 bbox regression,使用了一个 smooth 的 L1-loss。
Fast RCNN 中,提取 OP 的过程和训练过程仍然是分离的。因此我们在训练过程中,需要用 OP 的
方法先把图像 OP 提取好,再送入 Fast RCNN 中训练,在检测过程中也是如此需要先把相应的测试图像的 OP 提取出来送入检测。
图片标注效果测试
使用 Fast R-CNN 进行图像识别的测试效果非常理想,识别效率很高。vgg_cnn_m_1024 之类的中型网络准确度常常超过 95%。

最后我们尝试将 Fast R-CNN 用于我们的安全云存储系统。我们选用了训练好的模型,识别带检索的文档中的,军事图片,效果良好。待上传数据经由 Fast R-CNN 分类后的返回结果是一系列表示信息,每个信息由一个类别编号和四个数字组成的识别区域坐标表示。系统仅需要获取类别编号作为从本文档中识别出的图片信息,在创建文档索引过程中写入 Document 的 Field 域,用于关键字检索。

基于多项式朴素贝叶斯算法的文本分类
朴素贝叶斯分类算法是一种有监督的机器学习方法。它是一个基于概率的学习方法。
每个测试样例属于某个类别的概率 = 某个类别中出现样例中词的概率的乘积(类条件概率) * 出
现某个类别的概率(先验概率)
p(cate|doc) = p(word| cate) * p(cate)
具体计算类条件概率和先验概率时,朴素贝叶斯分类有两种模型:
1)多元分布模型(muiltinomial model)
以单词为粒度,不仅仅计算特征词出现/不出现,还要计算出现的次数。
类条件概率 p(word | cate) = (类 cate 下单词 word 出现在所有文档中的次数之和 + 1) / (类 cate
下单词总数 + 训练样本中不重复的特征词总数)。
先验概率 p(cate) = 类 cate 下单词总数 / 训练样本中的特征词总数
2)伯努利模型(Bernoulli Model)
以文件为粒度
类条件概率 p(word | cate) = (类 cate 下出现 word 的文件总数 + 1) / (类 cate 下的文件总数 + 2)
先验概率 p(cate) = (类 cate 下的文件总数) / (整个训练样本文件总数)

相关实验表明,多元分布模型计算准确率更高,所以分类器选用多元分布模型计算。
值得注意的是对文本分类的前提是,用户文档的可能分类类别大致确定。如果我们仅仅确定部分类别,剩下的全归为一个其它类时,测试集分类的结果将非常差。另外一个需要给出的参数是先验概率,我们首先需要对大量的已分好类的文档进行训练。一个疑问是,用户之后再上传的文档可能完全不同于之前的训练文档,分类资料中的一些关键字也可能随着时间的变化产生了概念漂移。然而相关研究证明,如果本系统在一个相对稳定的应用背景下使用,朴素贝叶斯算法可以很好的处理上述问题。
文本分类效果测试
使用 Newsgroup 文档集做测试,其中包含约两万篇文档,文档已经分好类,较为平均的分布在已知的 20 个类中。我们首先对文档预处理,对每篇文档进行文本化操作,为后续构造字典、提取特征词做准备。主要是主要是去除非字母字符,转换大写为小写,去除停用词。然后构造字典表,统计所有文档中出现过的每个词的总的出现次数。利用多项式朴素贝叶斯算法对文档集做分类,采用十组交叉测试取平均值,以为一般认为采用多项式模型比伯努利模型准确度高 。计算类条件概率和先验概率,并做好
平滑处理。其中相关资料表明类条件概率 p(word | cate) = (类 cate 下出现 word 的文件总数 + 0.0001) / (类
cate 下的文件总数 + 训练样本中所有类单词总数,能取得较优结果。后使用贝叶斯公式计算某一个测
试样本属于某个类别的概率。最后根据正确类目文件和分类结果文件统计出准确率,同时制作混淆矩阵,查看分类效果。

为了验证多项式朴素贝叶斯效果,我们训练集和测试集选取的比例是 9:1,在调整好平滑参数后,分类器的准确度能达到 85%左右,效果较为理想。当然,如果采用 KNN 算法,准确度有希望能够得到进一步提高,但经测试 KNN 的运行时间效率远低于朴素贝叶斯分类,生成向量和计算的过程也将占用更多的系统资源,最终我们选用多项式朴素贝叶斯分类。生成的文本类别将写入之后的 Document 中,以用于搜索结果的筛选。
密文索引上的的模糊查询
在文件上传前本地加密用户文件的云存储策略极大提升了用户数据安全性,但也丧失了大部分搜索特性。为了实现密文基础上的搜索功能,系统建立了一个索引系统。索引系统的设计兼顾数据的安全隐私和云系统的高效便捷。用户的本地客户端在加密上传文件的同时分析本地未加密的数据明文,筛选索引关键字加密后写入索引,并上传与云端索引合并。索引采用倒排结构。用户搜索下载文件时,客户端加密用户关键字,上传至云端索引系统,进行密文对密文的搜索。同时,系统通过使用 N-gram 分词技术,实现了模糊查询功能。
更多内容请看下篇:
一种安全云存储方案设计(下)——基于Lucene的云端搜索与密文基础上的模糊查询
备注:图片标注部分,关于卷积神经网络相关算法的原理,参考了《论文笔记 Fast R-CNN》 http://blog.csdn.net/happyer88/article/details/51757794
论文出处:http://arxiv.org/abs/1504.08083
转载请注明 作者 Arthur_Qin(禾众) 及文章地址 http://www.cnblogs.com/arthurqin/p/6274624.html