数据结构,简单来说就是计算机存储、组织数据的方式。在C语言中,内建的数据类型有简单变量、数组、指针、结构以及联合。实现数据结构一是要设计表示数据的方案,二还要考虑到针对这种数据结构的操作集,在C中可以把操作编写为函数。
比如说写一个程序,编译前不清楚究竟要记录多少条数据,定义一个大小为5的数组,可能不够用,但是大小为500的话,可能有用不了那么多,也许可以考虑使用动态数组或者是动态内存分配,但是即使是编译前不需要考虑数组大小,但在程序开始运行时就得必须确定一个值,这样很不灵活。
理想情况是可以不确定地添加数据,而不是事先指定数据的多少。在这种需求下,C内置的数据类型就显得力不从心了,必须设计新的数据类型。
链表的基本结构是节点,每个节点包括存储的数据以及指向下一个节点的指针,最后一个节点有一个特殊的结束标记,通过指向第一个节点的头指针来使用链表,这样做可以实现非常灵活的内存动态管理。和数组相比,也是有缺点的,比如数组可以根据下表直接计算得到数据的地址,而链表就只能按指针顺序不断跳转以找到需要的数据。
数据类型从抽象的概念到具体的实现,有三个步骤。
为类型的属性和可对类型执行的操作提供一个抽象的描述。这个描述不应受到任何特定实现或编程语言的约束。这样一种正式的抽象描述被成为抽象数据类型(ADT)
开发一个实现该ADT的编程接口。即说明如何存储数据并描述用于所需操作的函数集合。在C中,可以提供一个结构的定义以及用来操作该结构的函数原型,想使用该类型的人可以使用这个接口来进行编程。
编写代码实现接口。但使用者无需知道细节。
节点
typedef struct node
{
Item item;//需要存储的数据
struct node *next;//指向下一个节点,若是末尾,则置为NULL
} Node;
定义链表类型
typedef struct list
{
Node *head; //指向链表头的指针,链表的入口
Node *tail; //指向链表尾的指针,可以增加操作的效率
int size; //链表的大小
} List;
基本操作集
void InitializeList(List *plist);//定义一个List后,需使用该函数初始化List
unsigned int ListItemCount(const List *plist);//确定List长度
bool AddItem(Item item, List *plist);//在末尾添加项目
void EmptyTheList(List *plist);//清除List内容释放内存
//...
可以看到ListItemCount并不需要传入指针,这样做是为了统一格式,避免混乱。
Comparing Arrays to Linked Lists
Data Form Pros Cons
Array Directly supported by C. Provides random access. Size determined at compile time.Inserting and deleting elements is time consuming.
Linked list Size determined during runtime.Inserting and deleting elements is quick. No random access.User must provide programming support.
With an array, you can use the array index to access any element immediately.This is called random access.
With a linked list, you have to start at the top of the list and then move from node to node until you get the node you want, which is termed sequential access.
队列也被称为“waiting line”,正如名字所暗示的那样,它们很容易被想象成一群等待的人,排队时,排队越早,优先级越高。将数据添加至队列时,数据放在最后,将数据放入队列中的操作称为”enqueue“;取出数据时,将最早添加的数据取出,称为“dequeue”。这种方式称为"First In First Out"(FIFO)。
在C中实现时,可以使用链表或数组,这里我使用的是数组。数组是在连续有限固定的内存空间上排列,如果每次出队时将后面的数据前移一位,效率将会很低;或者是每次出队时弃用出队出队数据的内存空间,迟早会用完内存。所以这两种办法都不理想,需要使用一些小手段来标记数组形成环形数组。
定义链表类型
typedef struct queue {
Item* pitem; //pointer to array
unsigned items; //number of items in queue
unsigned head; //index of front of queue
} Queue;
用(queue.head + queue.items) % MAXQUEUE来当作下标访问数组,这里MAXQUEUE是10。
队列其实没什么好说的,和栈一样,实现起来不算困难。
二叉搜索树,结合了链表和数组的优点,既可以频繁的插入和删除元素又支持频繁的搜索。
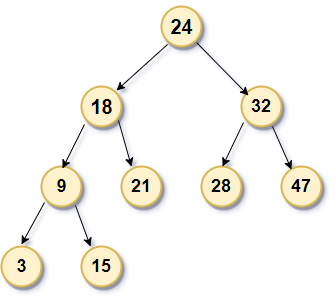
如图所示,每一个节点包含需要存储的数据和两个分别指向左子节点和右子节点的指针。二叉树或是一个空树,或是一个指定某节点为根的节点集合。每一个节点都有两个作为其后代的根,称之为左子树和右子树。每一个子树本身又是一个二叉树。所有左子树的项目排在根项目的前面,右子树的项目排在根项目的后面。
由二叉树的性质可以得到,最小点位于二叉树的最左边,这里是3。最大点位于二叉树的最右边,这里是47。
如果要添加节点,比如19,小于24,大于18,小于21,于是便成为了21的左子节点。
这里用伪代码递归简单写了一下,循环应该也可以。
//这里就不处理相等的情况了
AddNode(new, root)
if new < root
if root.left == NULL
root.left = new
else
AddNode(new, root.left)
else
if root.right == NULL
root.right = new
else
AddNode(new, root.right)
end
搜索节点的过程和上述类似,就不赘述了。
如果要删除一个节点的话,分几种情况
像15这种,没有子节点的,直接删掉就好
假如21的右子节点是22(图中没画),没有左子节点的,删掉21后,再把22接到21原来的位置
如果要删的节点有两个子树的话就麻烦了,比如要删掉24的话,可以找到左子树的最大节点21,把21移到24的位置,或者是把右子树的最小节点28移到24的位置,注意如果21或28有枝叶的话往上补位。
树的遍历一般有三种:前序遍历,中序遍历以及后序遍历,由于本人刚学,这里就不接着说了。
就不应该用有道云笔记编辑的...完全没办法转化。
下一篇我要用markdown来写了