目录:
机器学习基础:
机器学习的分类与一般思路
微积分基础:
泰勒公式,导数与梯度
概率与统计基础:
概率公式、常见分布、常见统计量
线性代数基础:
矩阵乘法的几何意义
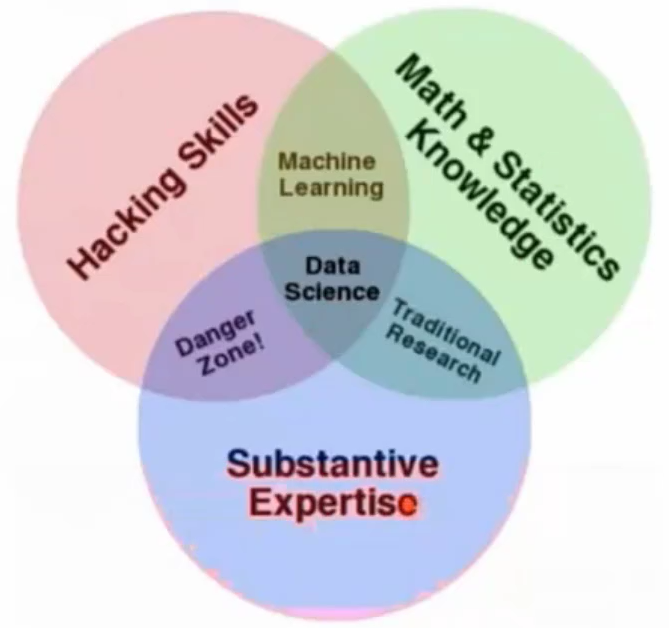
这是一张非常著名的图,请仔细挖掘其信息量。以期它在整体上指引我们的学习。
1 机器学习基础
1.1 机器学习分类
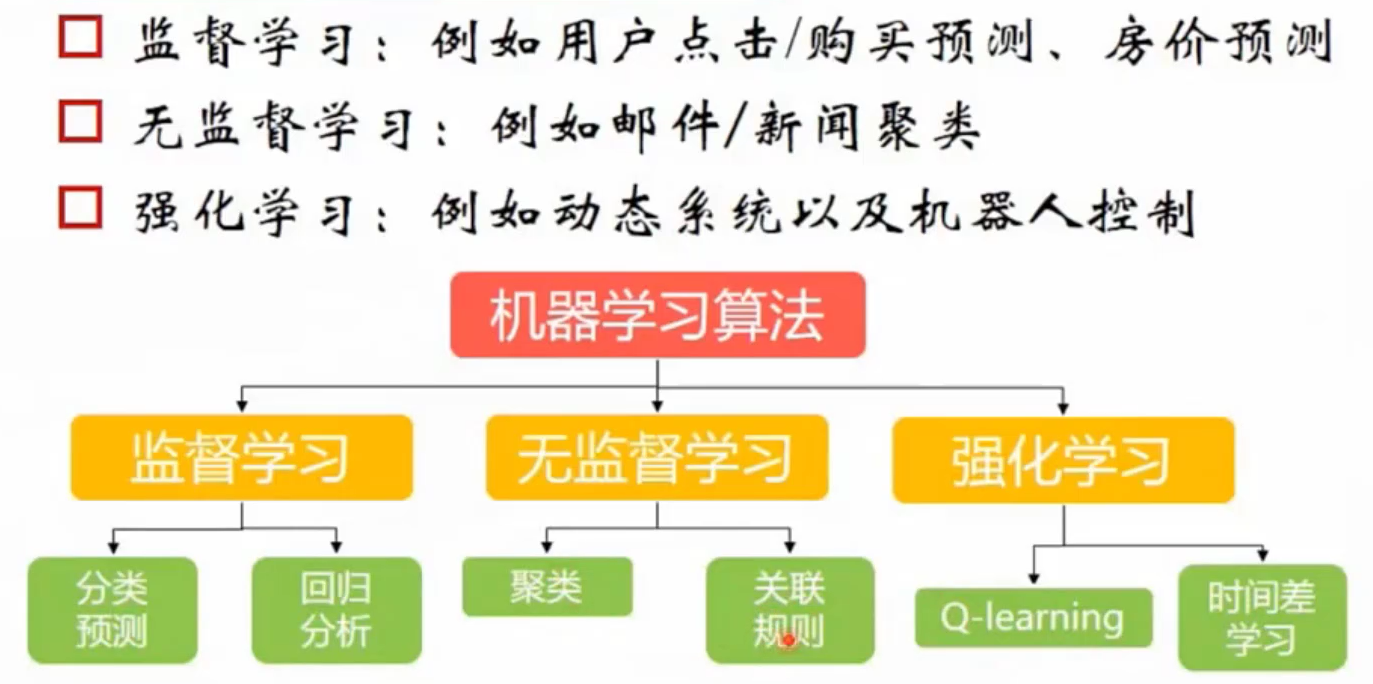
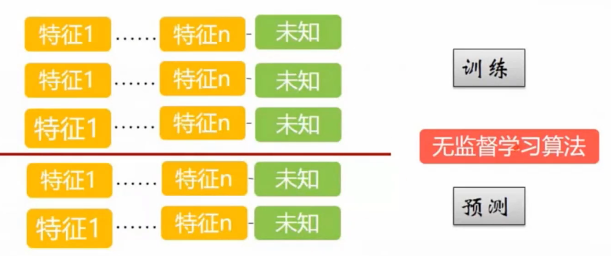
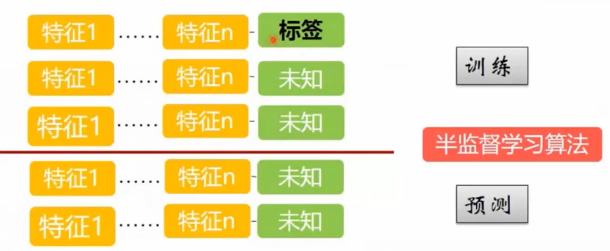
有监督学习、无监督学习、半监督学习的概念自行了解一下,不再赘述,简单贴3幅图,自行比对。

1.2 机器学习的一般思路
得分函数:

损失的函数的最优化问题:
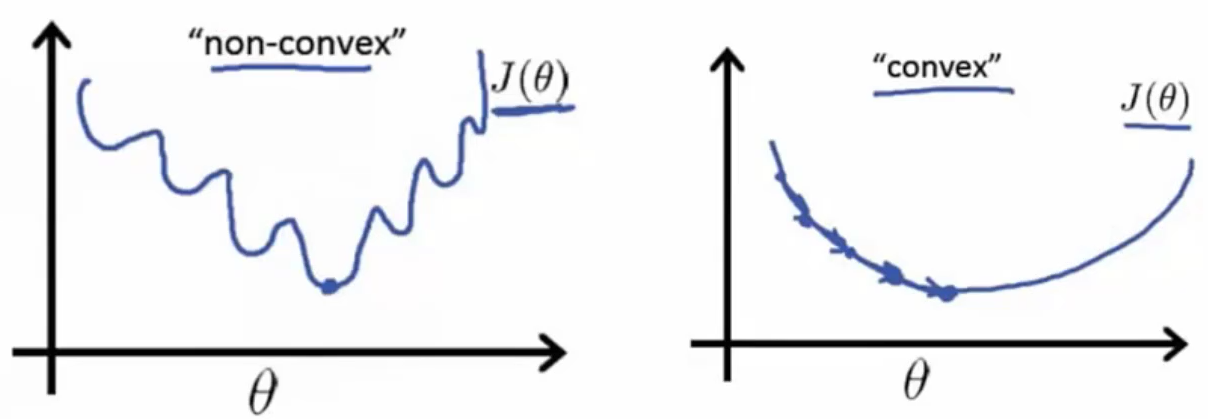
(左)非凸函数 (右)凸函数
与实际情况的误差即损失。损失函数可以看做是得分函数的函数。我们所希望的结果是找到一个得分函数,使得它最终的损失函数是最小的,而这个最小值所对应的得分函数,或者说此时的得分函数所对应的那个权重,即上图所示的θ值,就是我们所希望的最好的机器学习算法的结果。一言以蔽之,就是通过对损失函数对权重进行修改。那么就转化为优化问题。接下来的微积分就是怎么去求解这个最优化问题。
贴图一张:
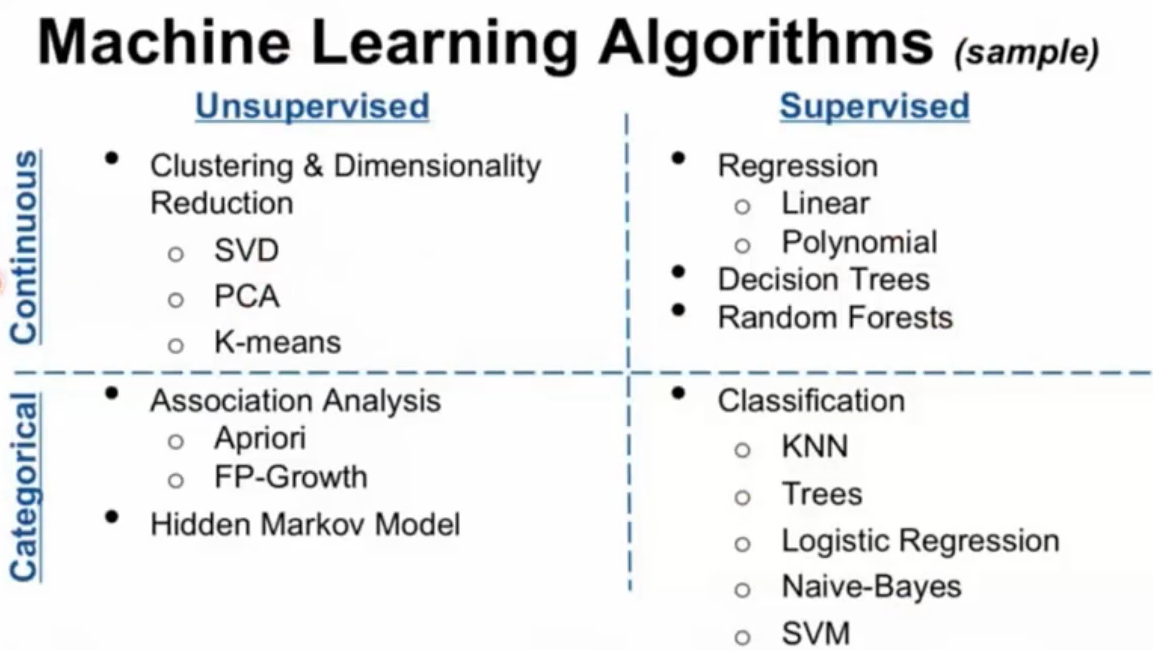
再附图一张:算法一览
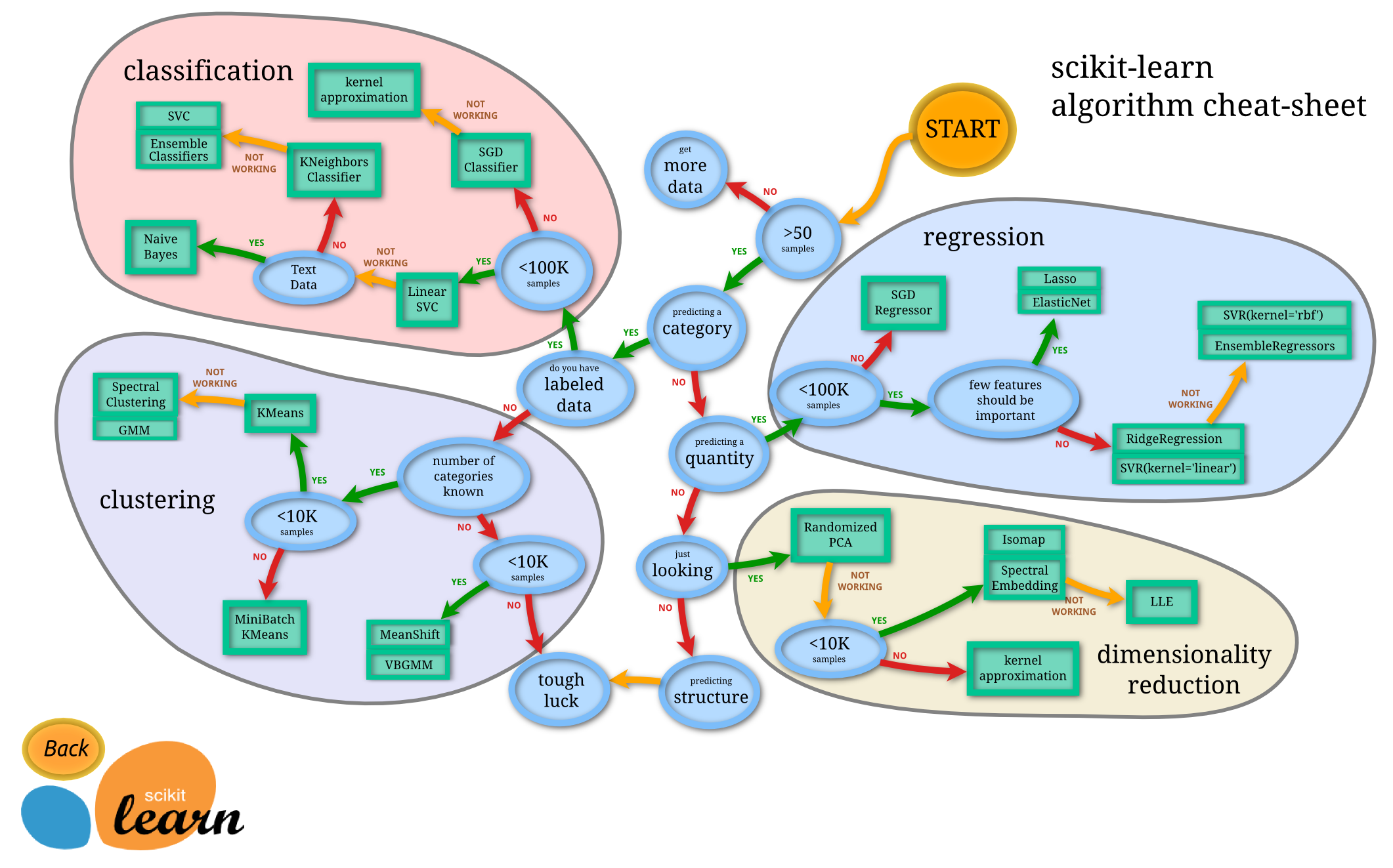
2 高等数学回顾:
2.1 微积分之:两边夹定理/夹逼定理(了解即可)
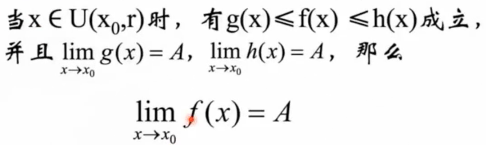
简单地说,导数就是曲线的斜率,是曲线变化快慢的反应。
二阶导数是斜率变化快慢的反应,表征曲线的凹凸性。
在GIS中,往往一条二阶导数连续的曲线,我们称之为“光顺”的。
还记得高中物理老师时常念叨的吗:加速度的方向总是指向轨迹曲线凹的一侧。
2.2 常用函数的导数(非常非常非常基础了!!!):
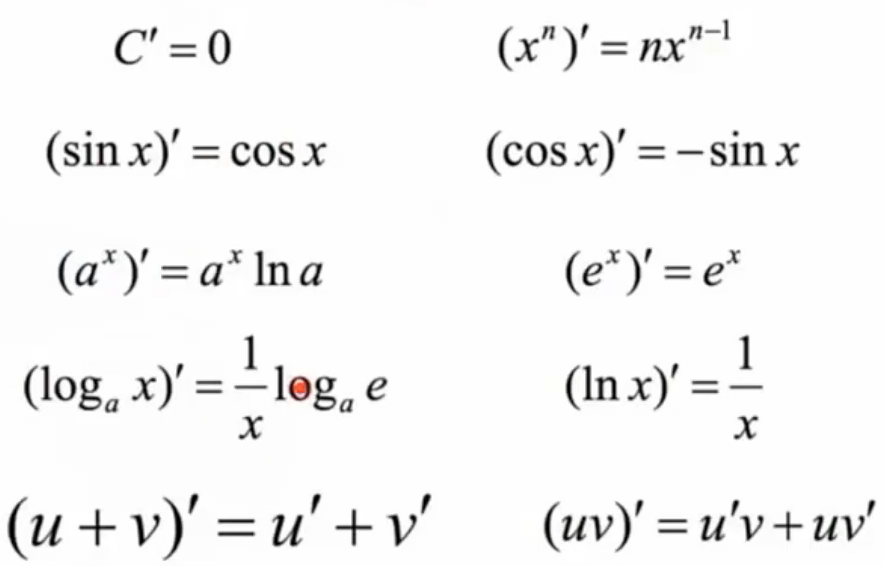
Taylor公式-Maclaurin公式:

2.3 方向导数:
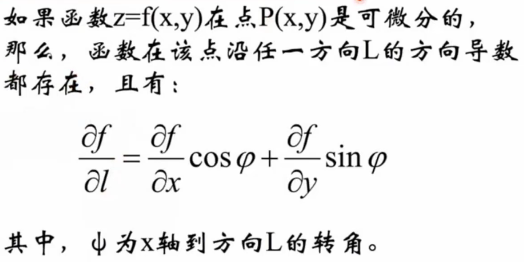
2.4 梯度(梯度是一个向量,导数是一个标量。):

2.5 凸函数的概念:

考虑Jensen inequality(琴生不等式)。
2.6 凸函数的判定:

即:一元二阶可微函数在区间上是凸的,当且仅当它的二阶导数是非负的。
2.7 凸函数的表述:

意义:可以在确定函数的凹凸性之后,对函数进行不等式替换。
2.8 凸优化:即凸函数的最优化理论。
如果你能够把一个数学问题变成一个凸优化问题,那这个问题就可以认为是解决了,哪怕你硬算也能找到其最优解。因凸优化理论现已及其成熟而且方便。
3 概率与统计基础
3.1 概率公式
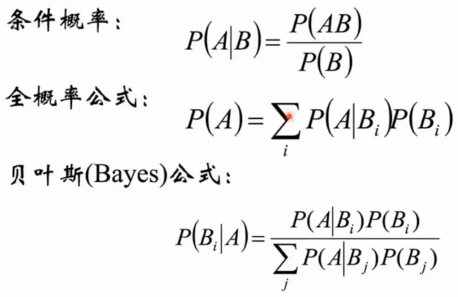
各概率公式切忌硬看不思考,一定要通过生动的方式去理解。
3.2 常见的概率分布
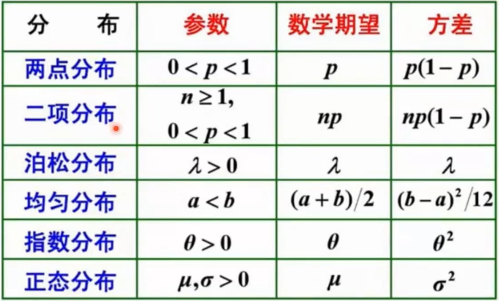
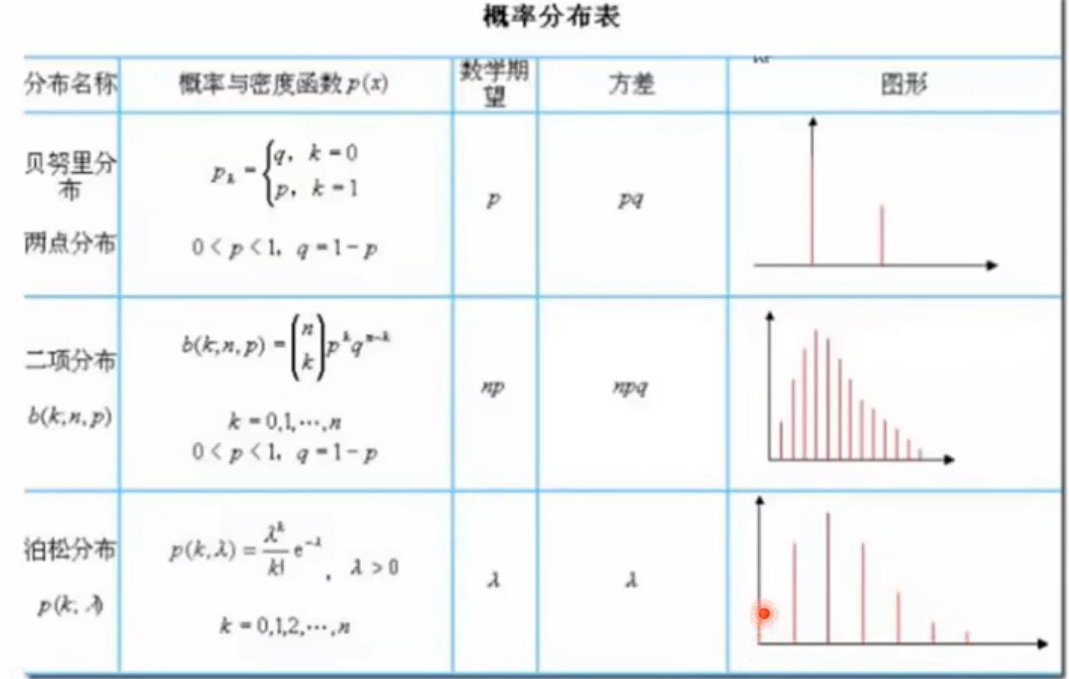
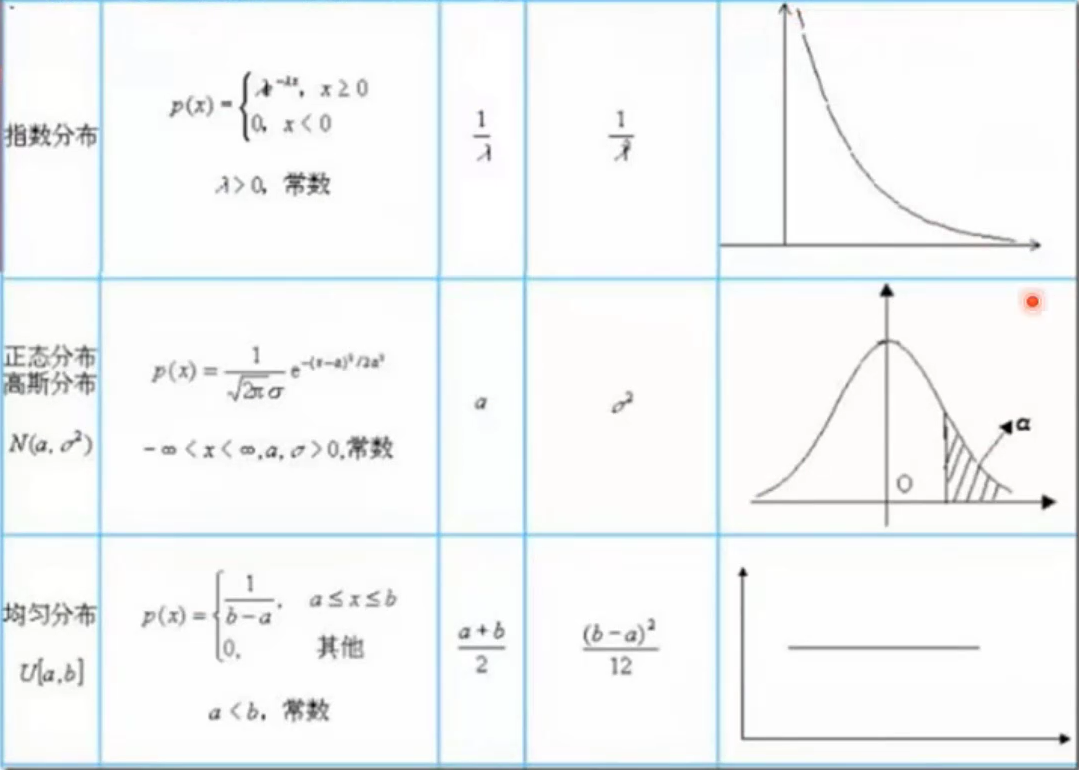
3.3 概率与统计的关注点
在大学概率与统计是一门课,实质上,二者是两种不同的观察视角。
概率论问问题的方式:根据是否已知整体进行区分

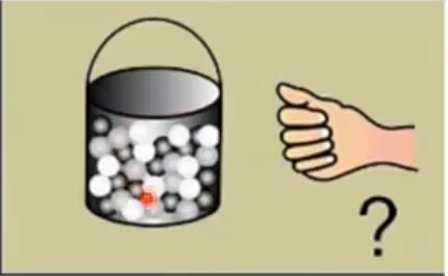
概率问问题的方式是:你已经知道桶里面有白球和黑球,你现在从白球和黑球里面抓出一把,你判断你这一把里面是白球或黑球的概率。这是,已知总体,判断抽样出来的结果。
数理统计问问题的方式:统计问题是概率问题的逆向工程

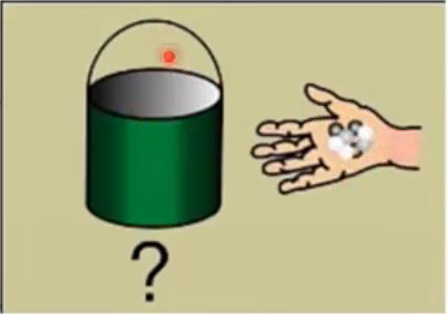
而更多的情况是,你根本不知道桶里面有多少黑球多少白球,你只能从中抽取一小部分,来看这一小部分里白球和黑球的比例,然后基于求得的比例,再反推桶里面黑球和白球的总体比例。以上,这是两种不同的思路。
然后再看下面这张图,这个就很有意思了:
概率统计与机器学习的关系(二者思维很像,紧密交织在一起):
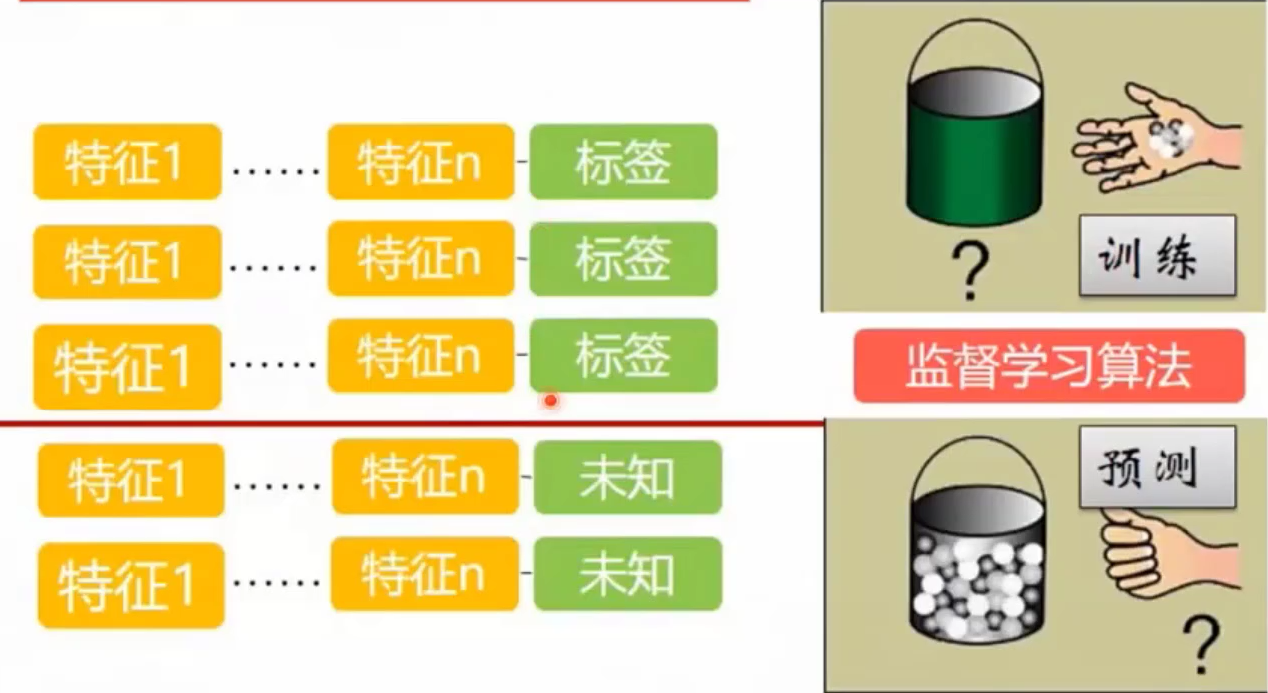
预测即是求取概率,请认真思考片刻。。。so,得出结论:概率统计的问题和机器学习学习问题是天然相关的,如果你不了解概率与统计问题,那么只机器学习的第一步抽样过程,很可能就会抽错,抽错了样本,学出来的算法必然是错误的算法,这个错的算法在未知的数据上预测出来的结果肯定是非常差的。这就是一个非常大的坑,很多机器学习初学者,不了解机器学习与统计的关系,而直接去硬套算法,得出的效果是非常不好的。问题不在于对算法的了解,而在于对统计的一些概念,以及对抽样的一些方法的了解的缺失。
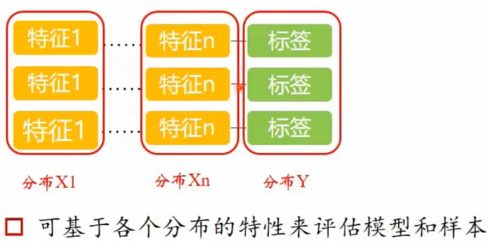
概率统计与机器学习的关系:
概率统计的是分布,机器学习训练出来的是模型,模型可能包含了很多分布。
训练与预测过程的一个核心评价指标就是模型的误差。
误差本身就可以是概率的形式,与概率紧密相关。
对误差的不同定义方式就演化成了不同损失函数的定义方式。
机器学习是概率统计的进阶版本(不严谨的说法)
3.4 重要统计量
都是描述全局(整体)统计量
期望
方差
协方差
3.4.1 期望
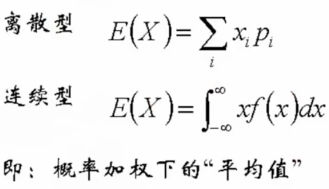
3.4.2 方差

3.4.3 协方差
机器学习比较多用协方差。期望、方差全部是一个随机变量,而协方差是评价两个随机变量的线性关系,请注意只能评价线性关系,非线性关系协方差是评价不出来的。
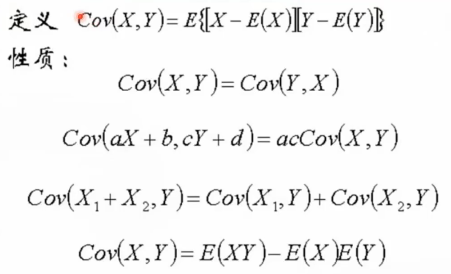
我们看定义里的公式:X-E(X)、Y-E(Y)这两部分,随机变量减去随机变量的期望,这其实就是一个去均值化的过程,而这个去均值化的过程实质上就是我们在机器学习里面进行数据预处理工作里面所包含的一个过程。所以求协方差的同时,就把数据预处理的工作给做了。然后减完均值之后,将二者进行内积,这其实可以理解成将我们的特征进行数据预处理之后对应的向量的几何的内积。把这层几何意义理解清楚了,看很多公式会感觉轻松而通透。
还有一点,你的协方差如果同时除以X的标准差和Y的标准差,得出来的结果叫做相关系数。它的几何意义是:特征去均值化之后的向量之间的夹角(的cos值)。联想将两个向量的内积除以两个向量的模长,得到的就是两向量的夹角的cos值。这个cos值就是相关系数。这个相关系数是评价特征间线性相关性的一个指标。所以在机器学习的一些模块里,通过计算,会得到一个相关性矩阵,这个矩阵就是很好的评价指标。
相关系数(值在-1到+1之间):
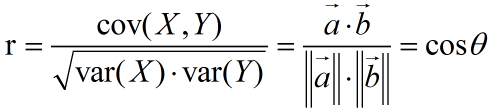
去均值化是机器学习里面一个比较重要的预处理方法,它能够帮助更加快捷、方便,也更加准确地求出结果。
下面进入矩阵分析和线性分析的这套思路:
4 线性代数基础
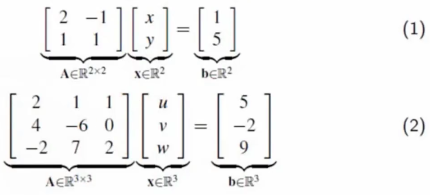
4.1 A*x的几何意义
矩阵绝不是把一堆数用括号括起来!
![]()
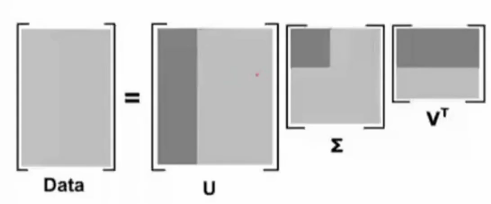
4.2 SVD(奇异值分解)算法---机器学习里面一个非常重要的降维算法
4.3 矩阵乘法在计算中的优势
将很多for循环写成矩阵或者向量乘法的形式。
矩阵计算模块在底层有优化。
Numpy进行矩阵运算很快。