本文是针对视频中行为者的行为进行弱监督标注信息的分割,和广义的图像语义分割不同,暂放。
国外泛读!title(19):Weakly Supervised Semantic Segmentation using Web-Crawled Videos(使用Web抓取的视频进行弱监督语义分割)---CVPR2017
本文的核心思想是利用弱监督标注的图像和视频去学习一个用于语义分割的单DCNN网络。
本文提出的单DCNN包括两部分:一个用于图像分类和判别性定位的编码器和一个用于图像分割的解码器。
本文提出的方法框架如下图:

本文采用解耦深度编码器 - 解码器架构[13]作为我们的语义分割模型,并对其注意机制进行了修改。
编码器f enc生成类别预测和粗略关注映射,其识别每个预测类别的区别性图像区域,并且解码器f dec从相应的关注映射中估计每个类别的密集二进制分割掩码。这两部分用不同的数据集进行训练。
本文同时提出了一种从网络上检索相关视频的全自动方法。
国外选读泛读!title(20):WILDCAT: Weakly Supervised Learning of Deep ConvNets for Image Classification, Pointwise Localization and Segmentation(WILDCAT:针对图像分类,点对点定位和分割的弱监督学习深度卷积神经网络)---CVPR2017
暂时只关注弱监督图像分割的部分内容。
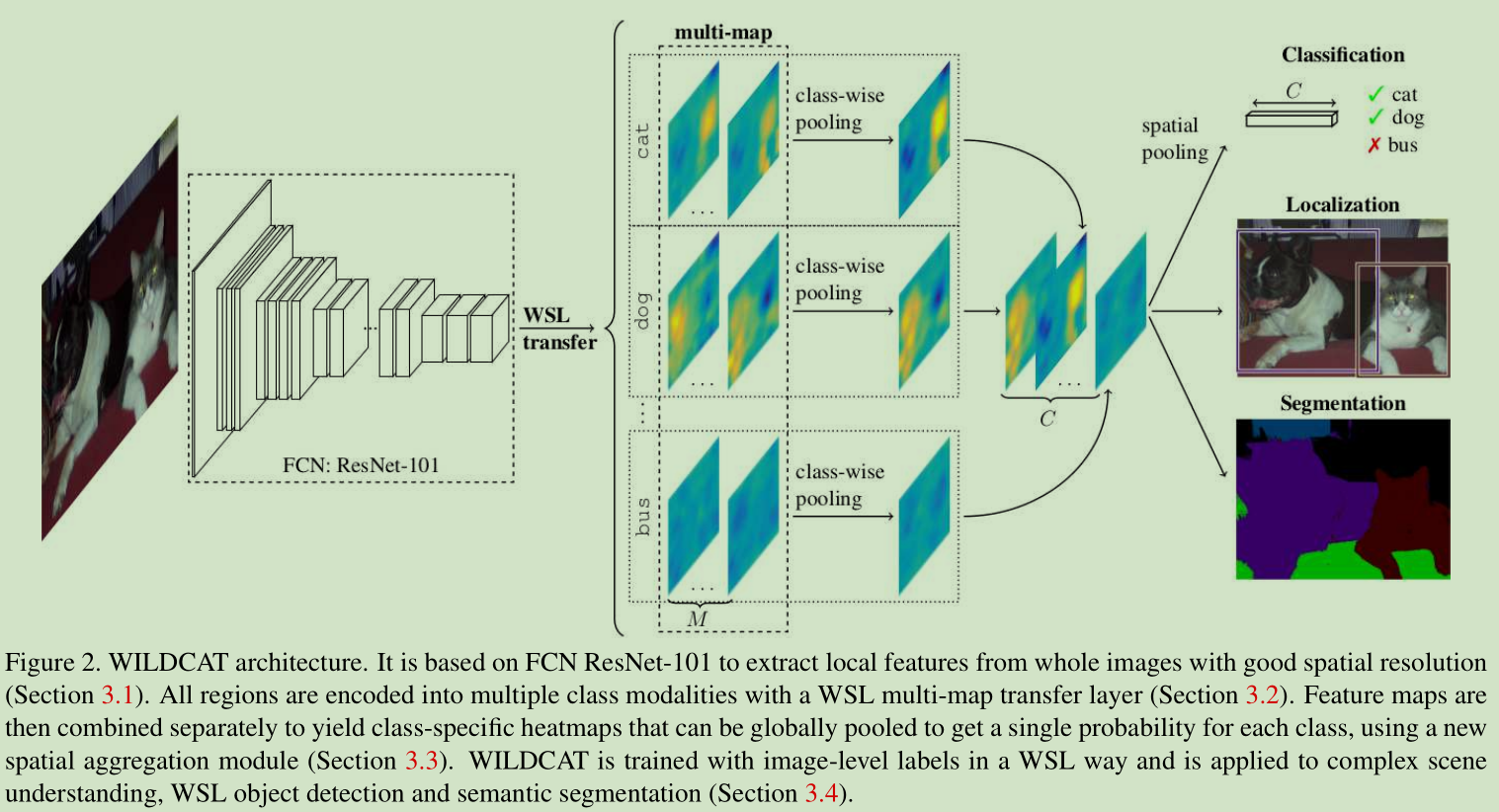
WILDCAT结构:整体WIDLCAT体系结构基于适用于空间预测的FCN网络结构 [42],与类别相关联的多地图弱监督学习(WSL)传输层编码模式以及一个用于学习准确定位WSL的全局池化层。
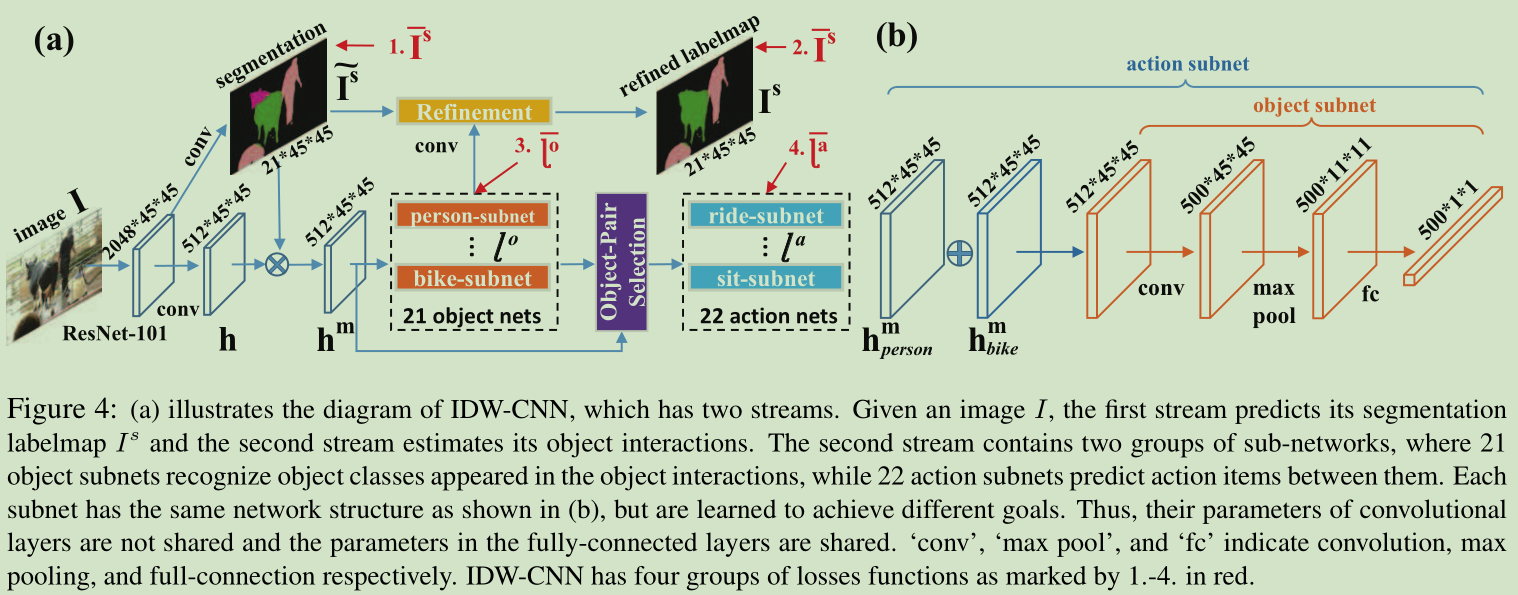
国内泛读!title(21):Learning Object Interactions and Descriptions for Semantic Image Segmentation(学习对象交互与描述的语义图像分割)---CVPR2017
本文主要是从训练数据的角度来提升CNN分割性能的。由于像素级别标记的样本很少,制作样本成本高。这里直接根据关键词从网络上搜索相关图像,建立了一个数据库IDW, 结合 VOC12上面的训练数据联合训练,对此设计了一个 IDW-CNN 模型,经过联合训练得到的模型用于分割,性能提升比较大。
国内精读!title(22):Object Region Mining with Adversarial Erasing: A Simple Classification to Semantic Segmentation Approach(基于对抗擦除的物体区域挖掘)---CVPR2017
图像语义分割是计算机视觉领域的核心研究问题之一。一般来讲,训练高性能的语义分割模型需要依赖于大量的像素级的人工标注(即标注每个像素点的语义信息)。然而,标注这类的训练样本非常困难,往往需要大量的金钱和时间。为了降低获取训练样本的难度,研究人员提出采用一些相对容易获取的标注作为监督信息(我们称之为弱监督),并用于训练图像语义分割模型。目前这些弱监督信息主要包括了bounding boxes,scribbles,points和labels,如图1。

图1
在这些弱监督信息中,图像的labels标注最容易获取,我们着重研究如何利用图像的labels作为监督信息,训练出用于语义分割的模型。而这一问题的成功的关键在于如何构建图像标签同像素点之间的关联,从而自动生成图像像素级的标注,进而利用FCN训练语义分割模型。

图2
目前我们注意到研究人员们提出了一些自上而下的attention方法(CAM[1], EP[2]等)。这类方法可以利用训练好的分类CNN模型自动获得同图像标签最相关的区域。如图2所示,我们给出了通过CAM方法获取的attention map。可以看出对于一个图像分类模型,往往物体的某个区域或某个instance对分类结果的贡献较大。因此这类attention方法只能找到同标签对应的某个物体最具判别力的区域而不是物体的整个局域。如何利用分类网络定位物体的整个区域,对语义分割任务具有重要意义。

图3
图3给出了我们的motivation。我们将第一张图片以及它对应的标签“person”输入到网络中进行训练。继而,网络会尝试从图中发现一些证据来证明图中包含了“person”。一般来讲,人的head是最具判别力的部位,可以使此图被正确地判别为“person”。若将head从图片中移除(如第二张图中的橙色区域),网络会继续寻找其它证据来使得图像可以被正确分类,进而找到人的body区域。重复此操作,人的foot区域也可以被发现。由于训练本身是为了从图片中发现对应标签的证据而擦除操作则是为了掩盖证据,因此我们称这种训练-擦除-再训练-再擦除的方式为对抗擦除(adversarial erasing)。
对抗擦除方法
基于上述的motivation,我们采用了对抗擦除的机制挖掘物体的相关区域。如图4所示,我们首先利用原始图像训练一个分类网络,并利用自上而下的attention方法(CAM)来定位图像中最具判别力的物体区域。进而,我们将挖掘出的区域从原始图片中擦除,并将擦除后的图像训练另一个分类网络来定位其它的物体区域。我们重复此过程,直到网络在被擦除的训练图像上不能很好地收敛。最后将被擦除的区域合并起来作为挖掘出的物体区域。
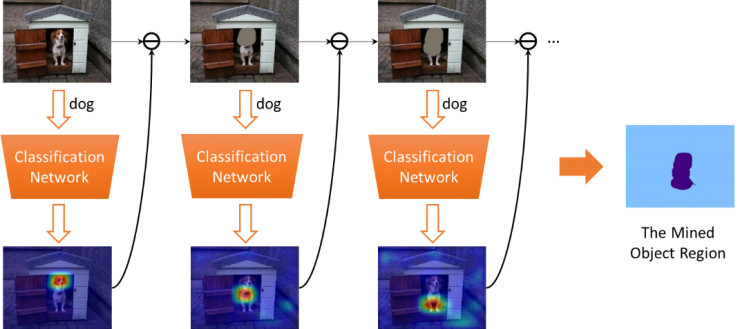
图4
对抗擦除的框架
图5为对抗擦除方法的细节。我们基于VGG16训练图像的分类网络,将最后两个全连接层替换为卷积层,CAM被用来定位标签相关区域。在生成的location map(H)中,属于前20%最大值的像素点被擦除。我们具体的擦除方式是将对应的像素点的值设置为所有训练集图片的像素的平均值。
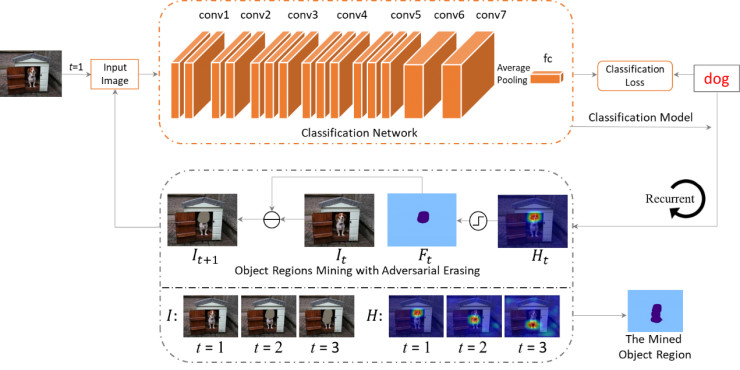
图5
我们发现在实施第四次擦除后,网络训练收敛后的loss值会有较大提升(图6右)。主要原因在于大部分图片中的物体的区域已经被擦除,这种情况下大量的背景区域也有可能被引入。因此我们只合并了前三次擦除的区域作为图片中的物体区域。图6左给出部分训练图像在不同训练阶段挖掘出的物体区域,以及最后将擦除区域合并后的输出。
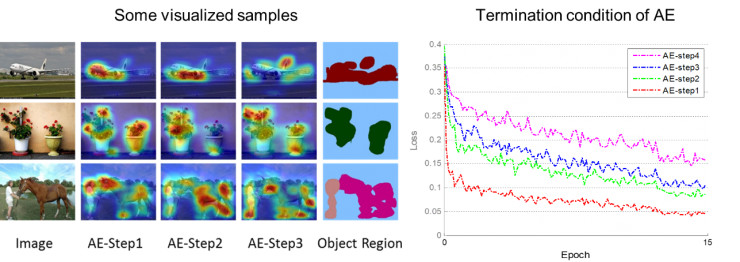
图6
对抗擦除在弱监督语义分割中的应用
我们利用显著性检测技术生成的显著图获取图像的背景信息,并同通过对抗擦除获得物体区域结合生成用于训练语义分割网络的segmentation mask(其中蓝色区域表示未指派语义标签的像素,这些像素点不参与训练)。由于在生成的segmentation mask中包含了一些噪声区域和未被标注的区域,为了更加有效地训练,我们提出了一种PSL(Prohibitive Segmentation Learning)方法训练语义分割网络,如图7。该方法引入了一个多标签分类的分支用于在线预测图像包含各个类别的概率值,这些概率被用来调整语义分割分支中每个像素属于各个类别的概率,并在线生成额外的segmentation mask作为监督信息。由于图像级的多标签分类往往具有较高的准确性,PSL方法可以利用分类信息来抑制分割图中的true negative区域。随着训练的进行,网络的语义分割能力也会越来越强,继而在线生成的segmentation mask的质量也会提升,从而提供更加准确的监督信息。
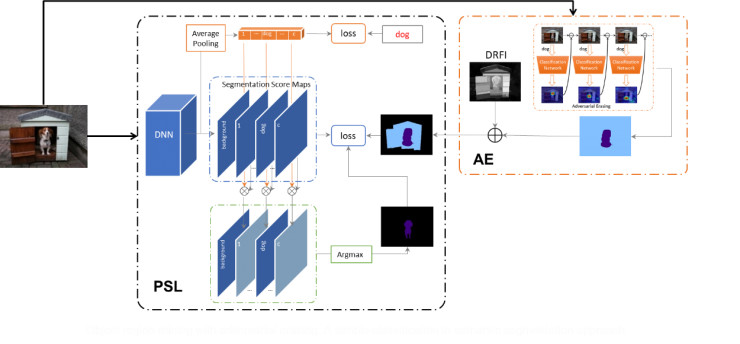
图7
实验结果
本文提出的对抗擦除和PSL方法,在Pascal VOC 2012数据集上获得了目前最好的分割结果。部分测试图片上也达到了令人满意的分割结果。
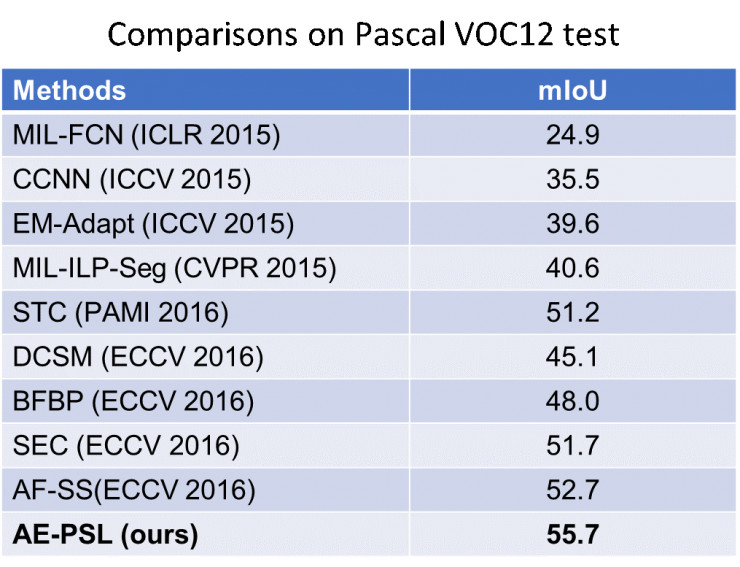

Reference
[1] B. Zhou, etc. Learning Deep Features for Discriminative localization. CVPR, 2016.
[2] J. Zhang, etc. Top-down Neural Attention by Excitation Backprop. ECCV, 2016.
国内暂时泛读!title(23):Learning to Detect Salient Objects with Image-level Supervision(图像级监督信息的显著性对象检测学习)---CVPR2017
abstract:深度神经网络(DNN)大大改善了显著物体检测的最新技术水平。然而,训练DNN需要昂贵的像素级注释。本文中,我们利用图像级标签提供重要线索的前景显着对象,并开发一种弱监督学习方法,用于仅使用图像级标签的显着性检测。 前景推理网络(FIN)是为这项具有挑战性的任务而引入的。
在我们的训练方法的第一阶段,FIN联合训练了完全卷积网络(FCN)
图像级标签预测。提出了全局平滑池化层,使FCN能够将对象类别标签分配到相应的对象区域,而FIN能够使用预测的显著图捕获所有潜在的前景区域。在第二阶段,FIN以其预测的显著图作为ground truth进行微调。为了细化ground truth,开发了迭代条件随机场来强化空间标签的一致性并进一步提升性能。
本文提出一个用图像级标注作为弱监督信息来训练而得的显著性探测器。本文方法包括两步:1 图像级标注的预训练 2 像素级标注的自训练
