注:本文所有内容摘自网络,想通过总结和梳理网络上前辈经验(https://blog.csdn.net/weixin_41813620/article/details/102998391),给自己指明道路。分享给更多人。
工作以来一直在思考算法工程师这个岗位的核心竞争力,自己的心路历程分为三个阶段。
第一阶段
这一阶段我认为算法工程师的核心竞争力是对模型的理解,对于模型不仅知其然,还得知其所以然。
于是我把目标检测的经典论文翻来覆去地看,将各种目标检测模型分解成了N个模块(part1),针对每个模块,反复比对各篇论文处理方式的异同,思考各种处理方式各自的优缺点,以及有没有更好的处理方式,比如:
深度卷积神经网络中的降采样(part2)总结了降采样的各种方式;
深度卷积神经网络中的上采样(part3)梳理了升采样的诸多方法;
关于物体检测的思考(part4)简述了anchor free与anchor based的异同,one stage和two stage的区别与联系;
深度学习高效网络结构设计(part5)和高效卷积神经网络一览(part6)总结了高效网络的设计思路与具体细节;
在anchor free检测器炙手可热的时候,Why anchor?(part7)分析了anchor free和anchor based的历史由来,以及各自利弊。
同时对目标检测实践中一些开放式的问题也有一些自己的思考,比如:
关于感受野的总结(part8)详述了感受野的计算方式和在应用时需要注意的地方;
目标检测网络train from scratch问题(part9)猜想了一下目标检测能够train from scratch的关键,在这篇文章里我质疑了DSOD和DropBlock这两篇论文对train from scratch问题下的结论(当时何恺明那篇讨论train from scratch的paper还没出来,从何恺明后来paper的实验看来,我的质疑是对的)。
上面是把模型揉碎了看,最近开始有更多时间与精力接触除了目标检测以外的任务,于是思考如何将各个计算机视觉任务统一起来,最近有了一点小的想法,该想法形成了一篇简短的文章(part10)。
第二阶段
这一阶段我认为算法工程师的核心竞争力在于代码功底好,一则知道各个模型的实现细节,二则能又快又好的实现idea。于是我用pytorch手撸了Yolov2和Yolov3。同时看了不少优秀的开源代码,比如darknet、mmdetection等等。最近正在用pytorch仿照mmdetection撸一个语义分割的训练框架。
第三阶段
最近开始接触各个行业对计算机视觉的需求,我发现一名优秀的算法工程师仅仅对模型理解不错、代码功底不错是不够的,还需要对有计算机视觉业务需求的行业有着较深入的理解。恰好最近看了一篇阿里云机器智能首席科学家闵万里的专访文章(part11),专访里这几段话我深以为然:
在阿里云的时候,我就亲自打造了一个岗位:DTC:Data Technology Consultant。DT有两个含义,一个是数据技术Data Technology,一个是数字化转型Digital Transformation,一语双关。他们像大夫,望闻问切,跟客户一起梳理出业务流程中的痛点,找到优化方式。
DTC不只是对行业整体的判断,还要对赛道中的选手体检,有开药的能力。可以把对方的难言之隐梳理出来,定量、优先级排序,然后从整体到细节,一层层结构化分解,最后进入具体执行。你要在传统行业创造新价值,就要搞清楚:什么东西制约了你的产能,制约了你的效率,制约了你的利润率。
技术人员今天往产业走,我相信整体遇到的障碍就是如何把技术思维变成以业务需求为导向的技术思维、技术分解思维。
虽然闵万里这几段话里的主体是技术咨询师,但我觉得这也是成为一名优秀算法工程师的必备品质。
总结一段话就是:
算法工程师往产业里走,需要把技术思维转变为以业务需求为导向的技术思维、技术分解思维;
算法工程师需要像大夫一样望闻问切,跟客户一起梳理出业务流程中的痛点,找到优化方式;
算法工程师不仅需要有对行业整体的判断,还需要对客户有体检、开药的能力,可以把客户的难言之隐梳理出来,定量、优先级排序,然后整体到细节,一层层结构化分解,最后进入具体执行;
要在传统行业创造新价值就要搞清楚什么东西制约了产能、效率、利润率。
仅仅输出模型的算法工程师比较容易被替代,更高的追求是输出一整套端到端的系统方案,从与客户一起梳理业务痛点、硬件选型、模型部署环境的规划与搭建、数据采集和标注标准制定、模型选型与设计等等。
附录:
part1:
目标检测分为两个阶段:训练、测试
训练阶段最重要的部分是:data,network,loss
data:对于神经网络而言,所需要的不变性一般都会encode到数据中,比如需要神经网络对图像色彩畸变具有不变性,那么就要对图像做色彩畸变增强;需要神经网络对尺度具有不变性,那么就要对图像做尺度增强。
data是神经网络的练习题,不合理的练习题不利于神经网络学习,因此需要对练习题进行筛选,去掉不合理的数据。
network:network分为backbone和head。
backbone用来学习图像特征,一般复用图像分类网络;head从图像特征中学习检测目标,例如框的坐标、类别等。
loss:这里的loss是广义的,包括整个梯度回传的过程。
测试阶段重要的部分是:postprocess
postprocess:即从head输出的特征图中获取最终输出框的过程。
综上,整个目标检测有4个重要的部分:data,network,loss, post process
1、data
数据增强:图像色彩增强(饱和度,色相,明度)、random crop、缩放、随机翻转、random erase、等等
数据选择:每个检测网络所能检测物体的尺度范围是有限的,超过这个范围的框,检测网络便无能为力,例如太大,太小。对于检测网络无能为力的框,喂给检测网络学习,不仅不能有助于检测网络的学习,还会适得其反,因此需要将超过检测网络能力范围的框丢弃。
2、network
backbone:VGG、darknet,Resnet,inception,mobilenet,等等
head:单尺度head、SSD head、FPN head
检测网络可以看作一条网路,信息在其中流动,检测网络的表达能力就像带宽一样,带宽由网络中带宽最小的地方决定。检测网络也类似,backbone和head的带宽应该匹配,不然大带宽的部分资源便只能白白浪费。
从资源利用率的角度看,backbone和head带宽匹配会提高资源利用率。例如backbone表达能力很强,但是head表的能力很弱,那么整体检测网络表现会受head的表达能力所限,backbone大于head表达能力的部分便被浪费掉了;反之同理。
从检测网络整体表达能力的角度来看,backbone和head带宽匹配才能最大化整个检测网络的表达能力。比如,为了增强检测网络的表达能力,只是提高backbone的表达能力有时候并不会奏效,这个时候从head下手也许会事半功倍。
3、loss
anchor和gt的匹配策略:faster rcnn系列、yolo系列
loss函数的选择:例如SmoothL1Loss函数用来计算坐标loss会比较稳定
不平衡问题:loss之间不平衡(loss加权)、loss内不平衡(样本重采样、样本加权、OHEM、focal loss)
4、post process
取框的策略:
从检测网络输出的特征图中decode出检测框。
之前优化pytorch版本的yolov2时,发现取框策略对mAP有一些影响。
检测框去重:
经过上一步取框后,图像上一个目标会有N个框,我们需要去掉重复框。
nms,soft nms,softer nms,iou-net,fitness nms,relation network
深度卷积神经网络中的降采样(part2)
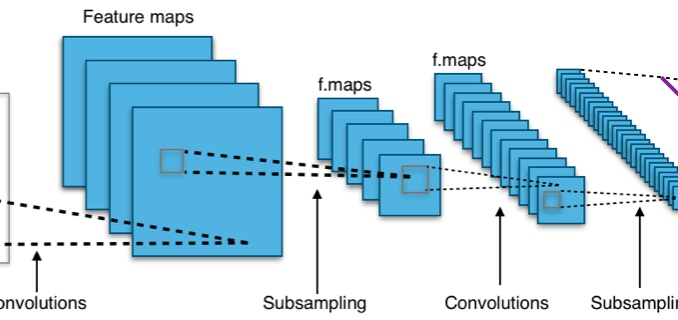
降采样指的是成比例缩小特征图宽和高的过程,比如从(W,H)变为(W/2,H/2)。深度卷积神经网络中降采样的方法主要有三种:
1、stride大于1的pooling
2、stride大于1的conv
3、stride大于1的reorg(reorganization 改组; 整顿;),在YOLOv2的论文里叫passthrough layer。
其中1和2在深度卷积神经网络中使用非常普遍,3比较小众,由Joseph Redmon在YOLOv2中首次提出。
1和2的对比在Striving for Simplicity: The All Convolutional Net(https://arxiv.org/pdf/1412.6806.pdf)中有详述,文末有这么一段总结:
With modern methods of training convolutional neural networks very simple architectures may perform very well: a network using nothing but convolutions and subsampling matches or even slightly outperforms the state of the art on CIFAR-10 and CIFAR-100. A similar architecture shows competitive results on ImageNet.
In particular, as opposed to previous observations, including explicit (max-)pooling operations in a network does not always improve performance of CNNs. This seems to be especially the case if the network is large enough for the dataset it is being trained on and can learn all necessary invariances just with convolutional layers.
大概意思就是,用stride=2的conv降采样的卷积神经网络效果与使用pooling降采样的卷积神经网络效果相当;卷积神经网络小的时候,使用pooling降采样效果可能更好,卷积神经网络大的时候,使用stride=2的conv降采样效果更好。
总体来说,pooling提供了一种非线性,这种非线性需要较深的conv叠加才能实现,因此当网络比较浅的时候,pooling有一定优势;但是当网络很深的时候,多层叠加的conv可以学到pooling所能提供的非线性,甚至能根据训练集学习到比pooling更好的非线性,因此当网络比较深的时候,不使用pooling没多大关系,甚至更好。
pooling的非线性是固定的,不可学习的,这种非线性其实就是一种先验。
第3条中降采样的优势在于能够较好的保留低层次的信息。1和2的降采样方式,好处是抽取的特征具有更强的语义性,坏处是会丢失一些细节信息。而3这种方式与1、2相反,它提取的特征语义性不强,但是能保留大量细节信息。所以当我们既需要降采样,又需要不丢失细节信息的时候,3是一个非常合适的选择。
深度卷积神经网络中的上采样(part3)
语义分割中的FCN、U-Net,目标检测中的FPN、DSSD、YOLOV3等模型为了增强模型效果,都会通过hour glass结构来融合低层和高层的信息,这样融合后的特征既具有高层特征的抽象语意信息,又具有低层特征的细节信息。而低层特征feature map比高层特征feature map大,为了融合,需要将高层特征feature map放大到跟低层特征feature map一样大,放大feature map的过程也就是升采样(upsample)过程,如下图所示。升采样具体实现有插值方式和deconv方式。

升采样示意图
一、插值
插值常用的方式有nearest interpolation、bilinear interpolation、bicubic interpolation。
1、nearest interpolation
将离待插值最近的已知值赋值给待插值。
2、bilinear interpolation
根据离待插值最近的 个已知值来计算待插值,每个已知值的权重由距离待插值距离决定,距离越近权重越大。示意图和计算公式如下所示。
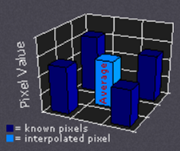 bilinear interpolation示意图
bilinear interpolation示意图 bilinear interpolation计算过程
bilinear interpolation计算过程
3、bicubic interpolation
根据离待插值最近的 个已知值来计算待插值,每个已知值的权重由距离待插值距离决定,距离越近权重越大。示意图如下所示。
 bicubic interpolation
bicubic interpolation
4、各种插值方式的区别与联系
从nearest interpolation、bilinear interpolation到bicubic interpolation,插值所利用的信息越来越多,feature map越来越平滑,但是同时计算量也越来越大,nearest interpolation、bilinear interpolation、bicubic interpolation的区别与联系可见下图示意,其中黑色的点为预测值,其他彩色点为周围已知值,用来计算预测值。
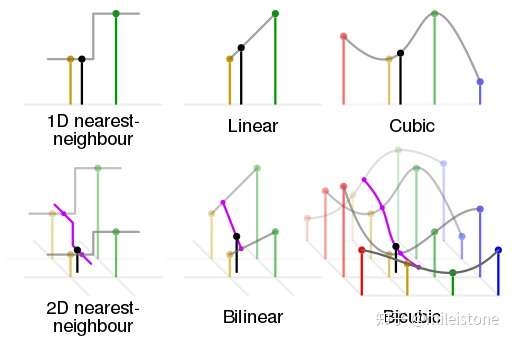 各种插值方式的区别与联系
各种插值方式的区别与联系
二、deconv
自从步入深度学习时代,我们越来越追求end2end,那么升采样能不能不用人为定义的权重,而让模型自己学习呢?答案是显然的,deconv就是解决方案之一。
1、stride=1
等价于stride=1的conv,只是padding方式不同,不能起到升采样的作用。以一维的数据为例,示意图如下,中间步骤是将卷积转换为矩阵乘法的过程。
 stride=1的deconv计算过程
stride=1的deconv计算过程
2、stride > 1
能起到升采样的作用,一般用到的deconv,stride都大于1。以一维的数据为例,示意图如下,中间步骤是将卷积转换为矩阵乘法的过程。
 stride=2的deconv计算过程
stride=2的deconv计算过程
3、名字
deconvolution也叫transposed convolution,upconvolution等等。其中deconvolution这个名字有点歧义性,容易带来困惑,transposed convolution比较容易理解。容易验证1和2中convolution和deconvolution中的权重矩阵互为转置。
三、deconv和插值的区别与联系
deconv和插值,都是通过周围像素点来预测空白像素点的值,区别在于一个权重由人为预先定义的公式计算,一个通过数据驱动来学习。
参考:
https://github.com/vdumoulin/conv_arithmetic
https://www.cambridgeincolour.com/tutorials/image-interpolation.htm
https://distill.pub/2016/deconv-checkerboard/
http://cs231n.stanford.edu/slides/2018/cs231n_2018_lecture11.pdf
关于物体检测的思考(part4)
1、基于anchor和不基于anchor
除了yolov1和densebox之外的检测网络基本都是基于anchor的。
anchor相当于增加了模型的assumption,如果模型assumption跟数据集的分布一致,那么这个assumption会有利于框的回归,提高模型的准确性;但是如果这个assumption跟数据集分布不一致,它反而会伤害模型的准确性。所以基于anchor的模型,anchor的设置比较重要,anchor要与数据分布一致。
2、one stage与two stage
one stage主要有ssd和yolo系列,two stage有rcnn系列和基于ssd的refinedet。
虽然基于ssd的改进文章比yolo的多很多,给人一种ssd比yolo好的错觉,但是yolo各方面相比ssd并不差,ssd比yolo更受欢迎的原因我认为主要是ssd基于主流框架开发,便于改进;而yolo基于小众的darknet,darknet没多少人熟悉,大家也不愿意去熟悉这样的小众框架。
小众框架社区不成熟,遇到了问题不容易找到解决方案,而且学会了darknet只能玩yolo系列模型,学习成本太高,不值当,另外darknet只支持最简单的layer,稍微复杂的layer里面都没有,如果你想基于darknet搭一些当前最fancy的结构,可能会遇到困难。
one stage和two stage的区别。two stage相当于在one stage的后面再refine一下。ssd和v1之后的yolo跟faster rcnn系列框架里的rpn差不多。
one stage给人快但是准确性不太好的印象,two stage给人准确性高但是慢的印象。但是我认为假以时日,one stage和two stage会逐渐吸收彼此的长处,最后one stage可以做到和two stage一样准,two stage可以做到和one stage一样快。
如果以速度横轴,mAP为纵轴画点阵图,那么当前one stage模型主要分布在右下角,two stage模型主要分布在左上角;而以后的话,one stage模型在这个坐标系里每个点的附近一定会有一个two stage模型。
3、数据分布
模型其实就是一系列assumption的集合。这些assumption是我们对数据集分布的假设。
模型不是孤立的,模型跟数据分布是成对出现的,这也就是我们常说“没有最好的模型,只有最合适的模型”背后的道理。
深度学习模型的超强拟合能力让我们开始遗忘assumption的重要性。在传统机器学习时代,大家非常看重assumption,因为传统机器学习时代,模型拟合能力没那么强,模型的assumption一旦跟数据分布不一致,效果会很差。而深度学习时代,模型拟合能力太强,大多数时候我们不考虑assumption是否与数据分布契合,也能训练出一个不错的模型出来。
在深度学习刚火,到处一片蓝海,大家四处跑马圈地的时候,不关注assumption,粗放式地把模型往复杂了怼,的确是一种行之有效的方式。但是现在模型方面逐渐到了瓶颈,继续往复杂了怼,效果提升有限,这个时候我们可能需要从精细化入手,比如回到传统机器学习重视assumption的思路上。
以分类为例,现实场景里类别不平衡是常见现象,所以我们经常需要想一些办法对付类别不平衡,比如对数量少的类别升采样,或者对数量少类别的loss加更大的权重等等。
这个过程其实就是在处理数据分布跟assumption不一致的问题,普通分类模型的assumption是各个类别的样本数量差不多,但是实际数据集里各个类别的样本数量却差距较大,这里出现了gap。
以检测为例,提出ohem的原因也是从assumption角度入手。ohem是解决物体框和背景框之间的平衡问题。那么更进一步,检测里面各个类别之间平衡吗?
从assumption角度思考的话,会发现天空突然广阔很多,还有很多事情可做。我相信接下来两年会有越来越多的工作会从assumption入手,更甚,传统机器学习的思路也会慢慢地融入到深度学习领域。慢慢地,改改layer就能发文章的时代会逐渐远去。潮水褪去之后,既对传统机器学习了然于胸,又对深度学习有insight,还对具体领域(例如cv、nlp等等)有着扎实基础的人才能衣着光鲜地站在沙滩上,眺望远方,欣赏波涛汹涌的海浪。
深度学习高效网络结构设计(part5)
这一年来一直在做高效网络设计的工作,2018年即将结束,是时候写一篇关于高效网络设计的总结。
首先看看当前业界几个最负盛名的高效网络简介:
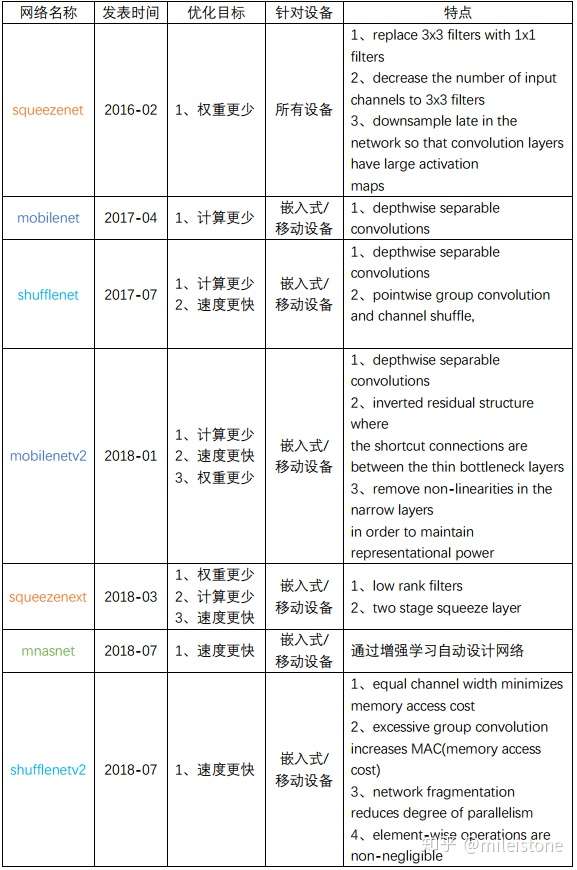
以上网络的目标主要有三个:权重少、计算少、速度快。这三者之间不存在着严格的相关关系,它们是三个独立的目标。即权重少不代表计算量少;计算量少不代表速度快。
高效网络高效的含义比较模糊,有的文章认为计算量小就是高效,有的文章认为速度快即高效。本篇总结主要从速度快入手。
速度快慢与计算量、结构是否利于并行、内存读取、运算硬件平台、具体软件实现等等都有关系,所以没有比较公允的衡量方式,一般比较好的衡量方式就是直接测速度。
从上述高效网络文章可以看出,高效网络的设计思路有如下几条:
1、depthwise separable convolutions
2、low rank filter
3、pointwise group convolution
4、避免网络分支太多,或者group太多
5、减少element wise的操作
既然已经有这么多高效网络,为什么要我们还要重新设计网络?
因为网络与任务相关,例如分类还是检测,分类是多少类,难度如何;检测是多类别检测还是单类别检测,如果是单类别,这个类别的物体有什么特性,例如人脸检测和人体检测的网络设计思路就大相径庭。我们工作中面临的任务大部分与论文里提出网络针对的任务不同,如果我们直接将论文里提出的模型拿过来用,而不加以改进,这个网络很可能不够好,例如准确率还有优化空间、或者速度还有优化空间。
高效网络和复杂网络设计的区别较大。如:
1、残差结构,仅仅是一个加的操作,这个操作在复杂网络里所耗的时间可以忽略不计,但是在高效网络里,它却成为了不可忽视的因素[shufflenetv2];
2、bottleneck,在复杂网络里,认为bottleneck可以减少计算量,但是在高效网络里,bottleneck却可能成为耗时的瓶颈
[shufflenet]We notice that state-of-the-art basic architectures such as Xception and ResNeXt become less efficient in extremely small networks because of the costly dense 1 × 1 convolutions. We propose using pointwise group convolutions to reduce computation complexity of 1 × 1 convolutions
[shufflenet]for each residual unit in ResNeXt the pointwise convolutions occupy
93.4% multiplication-adds (cardinality = 32)
3、大kernel size filter。在复杂网络里,我们越来越少用kernel size大的filter,例如5x5、7x7,我们认为用多层3x3就能达到大kernel size filter的感受野,例如两层3x3可以达到一层5x5的感受野,3层3x3可以达到一层7x7的感受野,同时计算量更小,由于网络更深,非线性也更优。但是在高效网络里,可能事情有些不同。
例如FaceBoxes提出的RDCL模块,用四层网络将feature map降为1/32。feature map大的部分非常耗时,不宜恋战,为了加速,需要在网络前端尽快将feature map的大小降下来,这个时候大kernel size filter有了用武之地,RDCL里面用到了7x7和5x5的大kernel。
 Faceboxes网络结构图
Faceboxes网络结构图
4、任务相关性。复杂网络因为表达能力够强,所以对任务不是很敏感;高效网络为了达到高效,需要充分利用任务的特点,针对该特点将与之无关的计算全部砍掉,这是高效网络的优点。然而世间没有免费的午餐,这个优点会带来缺点,因为高效网络与任务强耦合,换一个任务,网络的效果可能就不太好。例如将FaceBoxes这个网络backbone用来检测人体,效果会打一定折扣,因为人体数据的分布与人脸差异较大。
如何重新设计网络?
我将设计网络分为了五个层次:
0、入门级,直接整体替换backbone
例如将VGG16换为mobilenet。
1、初级,减channel,砍block
即成比例地降低一个经典网络的channel,例如channel数降低为之前的1/2;或者stage的block重复数减小,例如将某个stage的block重复数从8减小为6。
2、中级,替换block
比如mobilenetv2出来了之后,整体将之前模型的block替换为mobilenetv2的block;或者shufflenetv2出来之后,整体将之前模型的block替换为shufflenetv2的结构。
3、高级,从头开始设计,集众家之所长
即理解业界各个经典模型背后的motivation以及解决思路,不再拘泥于生搬硬套。将各个经典模型背后的设计思路吃透,了然于胸,下笔如有神。
4、科学家,设计出新的模块,为业界添砖加瓦,例如depthwise separable convolutions,shuffle channel等等。
网络设计的未来
从nasnet和mnasnet的相继推出,以及我自己设计网络的实践经历来看,我认为最终网络设计会完全被机器替代。
首先,我自己设计网络的过程,大概就是看各种网络结构的论文,然后把这些论文里的设计思路用到网络设计中,思路验证对了之后,再根据这个思路不断改超参,搜索得到一个该思路下的局部最优模型。这个过程其实跟nas的过程一模一样,即给定一些经典设计思路,和网络目标,最后组合这些网络设计思路得到最优模型。
 nasnet所使用的候选网络模块集合
nasnet所使用的候选网络模块集合
如果有公司能够提供比算法工程师更便宜的nas服务,我想大部分从事网络设计的算法工程师就可以下岗了,就跟当年工业革命,纺纱机出现了之后,纺织工人最后要么被裁,要么自谋出路。硬件只会越来越便宜,而算法工程师的待遇不可能一直降低,所以我想总有一天网络设计会被机器取代,就如同alphago大败李世石和柯洁一样。最后nas应该都不需要输入网络设计思路,它自己就能找到最优的网络设计思路,就像alphazero都不需要学习人类棋谱,自我博弈就可成为围棋大师。
nas服务是一群这个领域内最厉害科学家所设计的服务,nas所设计出来的模型以后必然会比大部分算法工程师好,如果nas服务又好又便宜,那么大部分公司应该都不需要雇佣算法工程师。
高效卷积神经网络一览(part6)
这里梳理了一下当前几个高效卷积神经网络,包括mobilenet[1]、mobilenetv2[2]、shufflenet[3]、shufflenetv2[4]、xception[5]、light xception[6]。
梳理的目的有二:
1、神经网络结构的细节在文章中一般会散落在各处,通过梳理,我们将网络结构的细节合为一处,形成一个网络结构说明书,按照这个说明书就能快速而又无误地实现出对应的神经网络;
2、通过比较各个高效卷积神经网络,找到其中的共性与区别。
每个网络结构说明书的重点是“基本单元”和“网络结构全貌”,网络结构中的重要细节则直接从论文中摘抄。
Mobilenet
- 基本单元

- 网络全貌
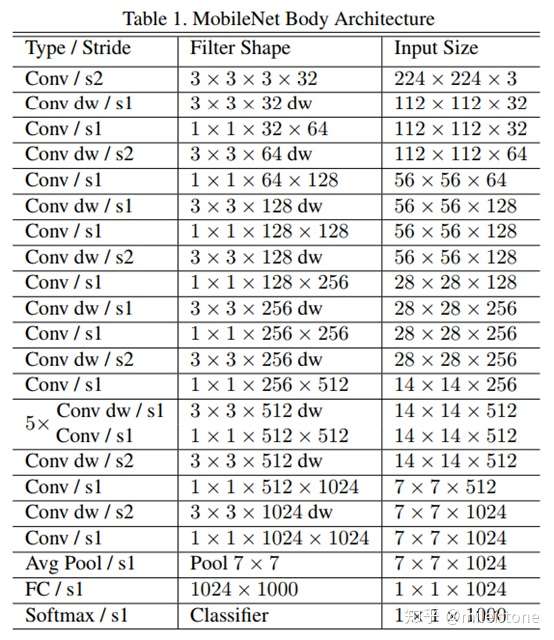
- 资源占比
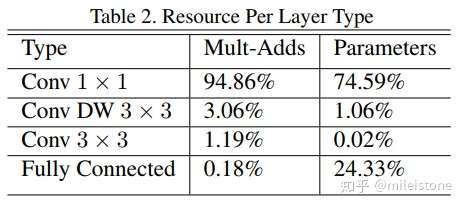
- Width Multiplier
In order to construct these smaller and less computationally expensive models we introduce a very simple parameter α called width multiplier. The role of the width multiplier α is to thin a network uniformly at each layer. For a given layer and width multiplier α, the number of input channels M becomes αM and the number of output channels N becomes αN.
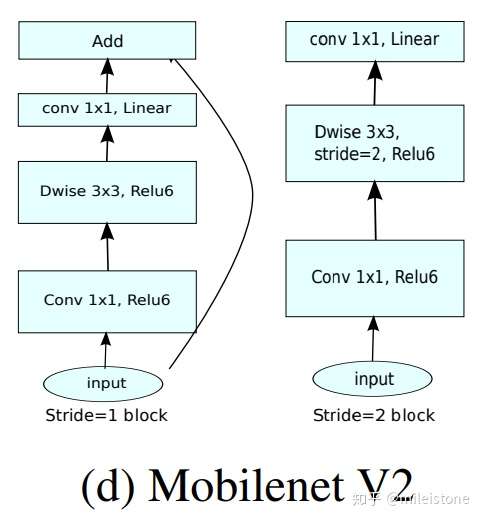
Mobilenetv2
- 基本单元
We use batch normalization after every layer.

- 网络全貌
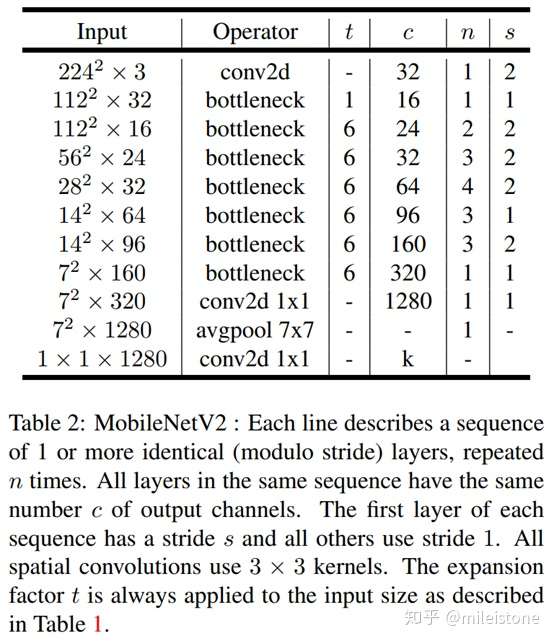
- Width Multiplier
One minor implementation difference, with [1] is that for multipliers less than one, we apply width multiplier to all layers except the very last convolutional layer. This improves performance for smaller models.
Shufflenet
- 基本单元
we set the number of bottleneck channels to 1/4 of the output channels for each ShuffleNet unit.
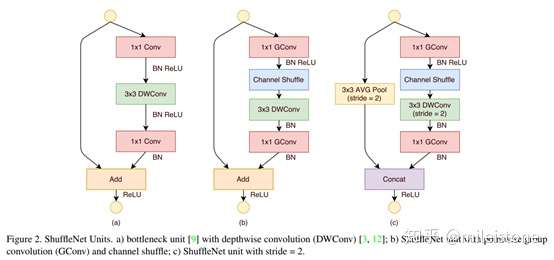
- 网络全貌
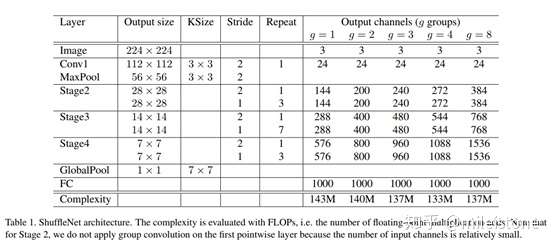
Note that for Stage 2, we do not apply group convolution on the first pointwise layer because the number of input channels is relatively small.
- Width multiplier
To customize the network to a desired complexity, we can simply apply a scale factor s on the number of channels. For example, we denote the networks in Table 1 as ”ShuffleNet”, then ”ShuffleNet
” means scaling the number of filters in ShuffleNet
times of ShuffleNet
Shufflenetv2
- 基本单元
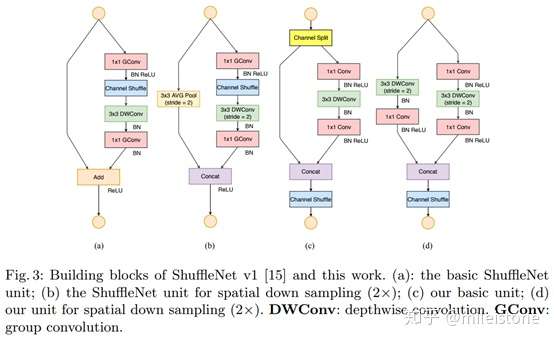
It is clear that when c1 : c2 is approaching 1 : 1, the MAC becomes smaller and the network evaluation speed is faster.
即channel split的时候,左右两个branch的channel平均分效果最好。
At the beginning of each unit, the input of c feature channels are split into two branches withand
channels, respectively. Following G3, one branch remains as identity. The other branch consists of three convolutions with the same input and output channels to satisfy G1. The two 1 × 1 convolutions are no longer group-wise, unlike [3]. This is partially to follow G2, and partially because the split operation already produces two groups.
- 网络全貌
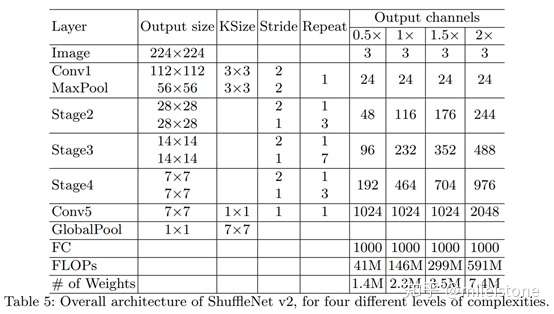
- Width multiplier
the number of channels in each block is scaled to generate networks of different complexities, marked as,
Xception
- 基本单元
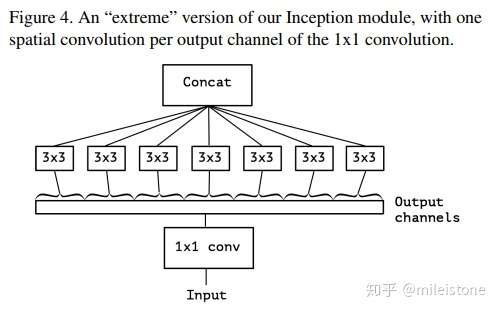
Two minor differences between and “extreme” version of an Inception module and a depthwise separable convolution would be:
1. The order of the operations: depthwise separable convolutions as usually implemented (e.g. in TensorFlow) perform first channel-wise spatial convolution and then perform 1x1 convolution, whereas Inception performs the 1x1 convolution first.
2. The presence or absence of a non-linearity after the first operation. In Inception, both operations are followed by a ReLU non-linearity, however depthwise separable convolutions are usually implemented without non-linearities.
We argue that the first difference is unimportant, in particular because these operations are meant to be used in a stacked setting.
the absence of any non-linearity leads to both faster convergence and better final performance.
- 网络全貌
Note that all Convolution and SeparableConvolution layers are followed by batch normalization (not included in the diagram). All SeparableConvolution layers use a depth multiplier of 1 (no depth expansion).
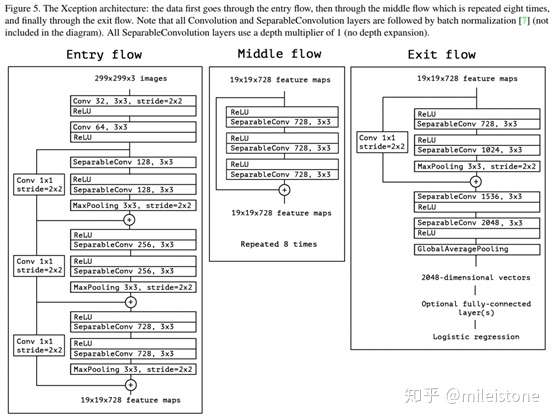
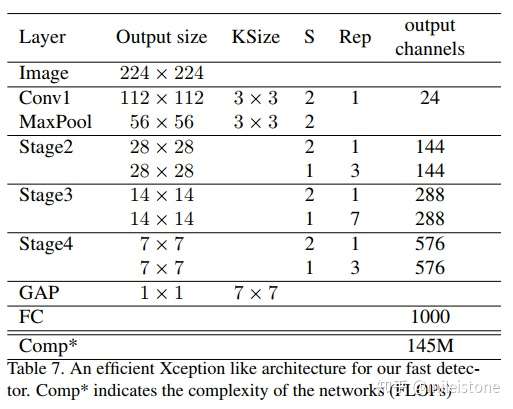
Light Xception
An efficient Xception like architecture for our fast detector An efficient Xception like architecture for our fast detector.
- 网络全貌
we do not use the pre-activation design
综合来看
1、所有模型,无论是普通conv、point wise conv(无论是否执行group操作)还是depth wise conv后面都会接上一个bn层;
2、是否pre activation得根据具体模型和具体任务来决定;
3、mobilenet、mobilenetv2的depth wise conv之后接了非线性layer,而shufflenet、shufflenetv2、xception的depth wise conv之后没接非线性layer。到底是接好还是不接好,有点类似是否pre activation,得根据具体任务、具体模型来决定;
4、separable conv模块中point wise conv和depth wise conv的顺序对模型影响不大;
5、第一层和最后一层会有一些特殊处理,需要注意,如mobilenetv2在用width multiplier进行模型缩放时,对最后一层不会缩放;shufflenet第2个stage的第一层point wise conv不会执行group操作。
一些感想
高效网络结构有点像机器学习算法,没有最好的机器学习算法,只有最合适的,高效网络结构亦然,每种高效网络结构也有自己的assumption,没有一种网络结构可以”放之四海而皆准“,比如并不是任何情况下使用separable conv替换普通conv就一定能提高网络前向速度。
硬件实现、软件实现以及网络结构自身特点,都可能改变网络前向速度的瓶颈,网络前向速度的瓶颈变了,设计思路就得跟着变,这需要我们对各种高效网络设计的motivation和assumption了然于胸。
我依据对以上高效网络的理解,试着实现了一下,实现代码如下。
Why anchor?(part7)
1、为什么需要anchor机制
anchor机制由Faster-RCNN提出,而后成为主流目标检测器的标配,例如SSD、Yolov2、RetinaNet等等。
Faster-RCNN中使用anchor机制的motivation如下:
In contrast to prevalent methods [8], [9], [1], [2] that use pyramids of images (Figure 1, a) or pyramids of filters (Figure 1, b), we introduce novel “anchor” boxes that serve as references atmultiple scales and aspect ratios. Our scheme can be thought of as a pyramid of regression references (Figure 1, c), which avoids enumerating images or filters of multiple scales or aspect ratios.
即anchor机制要解决的问题是scale和aspect ratio变化范围大,之前的解决方法是pyramids of images或者pyramids of filters。pyramids of images耗时,而pyramids of filters是传统CV的做法,当时CNN-based的CV还没有一种对应pyramids of filters的方案(对应的方案得等到2016年底的FPN,即pyramids of features)。
所以作者提出了一种新的解决方案——anchor机制。
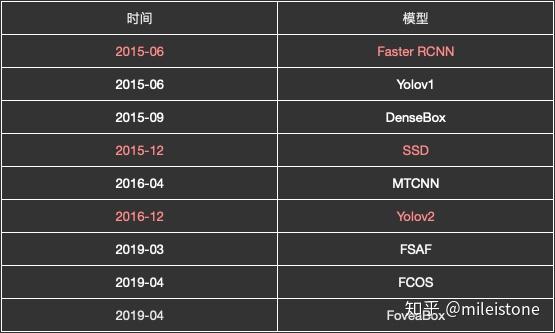 图1.1 目标检测简史
图1.1 目标检测简史 图1.2 两个gt boxbox落到同一个cell
图1.2 两个gt boxbox落到同一个cell
虽然作者解释anchor机制是为了解决scale和aspect ratio变化范围大的问题,但anchor机制还顺便解决了另外一个重要的问题——gt(ground truth)box与gt box之间overlap过大会导致多个gt box映射到一个cell(即检测head上的一个特征点),从而导致gt box丢失,如图1.2所示,人体框和球拍框中心点相同,会落到统一个cell里。有了anchor机制之后,一个cell里会有多个anchor,不同anchor负责不同scale和aspect ratio的gt box,即使有多个框会映射到同一个cell,也不会导致gt box丢失。具体地,在训练阶段,gt box丢失会导致模型不能见到全量gt;在测试阶段,gt box丢失,会导致recall降低。
简而言之,anchor机制有两个作用:分而治之(将scale和aspect ratio空间划分为几个子空间,降低问题难度,降低模型学习难度)和解决gt box与gt box之间overlap过大导致gt box丢失问题。同理,pyramids of images和pyramids of features也有上述两个作用。
2、八仙过海,各显神通
上面已经说了,anchor机制是pyramids of images和pyramids of features的替代方案。换一句话说,pyramids of images、pyramids of features和anchor机制是解决同一个问题的三种思路。
比如DenseBox,MTCNN使用的是pyramids of images机制;而FCOS、FoveaBox使用的是pyramids of features机制;Faster-RCNN、Yolov2使用的是anchor机制;SSD、RetinaNet、Yolov3糅合了anchor机制和pyramids of features机制。
3、anchor free一定更好吗?
最近几个月anchor free的相关文章喷涌而出,大有革掉anchor based检测器命的势头,那么问题来了,anchor free就一定比anchor based的方法更好吗?
anchor free和anchor based方法各有优劣。例如,anchor free的前提是基于图像金字塔或者特征金字塔这个前提,但是无论哪种金字塔都会增加计算,降低检测速度,而anchor机制可以减少金字塔层数,进而提高检测速度。
就如同pyramids of images和pyramids of features两种方法各有优劣一样。基于pyramids of features的FPN大火的同时,基于pyramids of images的MTCNN方法依然有自己的一片天地。
无论是pyramids of images、pyramids of features还是anchor机制,没有孰优孰劣,它们有各自的优缺点,应该按需使用,甚至糅合到一起使用,取每种方法的长处,规避每种方法的短处。
例如ACN(Anchor Cascade for Efficient Face Detection)结合了pyramids of images和anchor机制,从而在速度和效果上取得了一个不错的折中。
技术是螺旋前进的,一个技术领域往往有多个演进路线,而每个时代,由于硬件或者理论基础等等的限制,总会有一个当前最优的演进路线,但是没有一个技术演进路线在任何时代都是最优的。就跟机器学习里的no free lunch理论一样,没有一个模型能在所有任务上都表现最优,同理没有一个技术路线能在任何时代都代表最先进方向。
关于感受野的总结(part8)
感受野是卷积神经网络里面最重要的概念之一,为了更好地理解卷积神经网络结构,甚至自己设计卷积神经网络,对于感受野的理解必不可少。
一、定义
感受野被定义为卷积神经网络特征所能看到输入图像的区域,换句话说特征输出受感受野区域内的像素点的影响。
比如下图(该图为了方便,将二维简化为一维),这个三层的神经卷积神经网络,每一层卷积核的 ,
,那么最上层特征所对应的感受野就为如图所示的7x7。
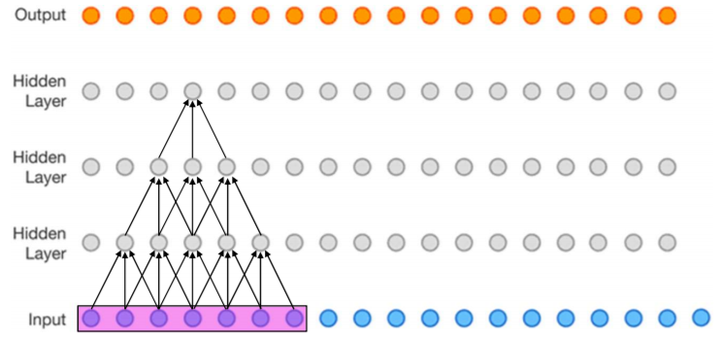 感受野示例[1]
感受野示例[1]
二、计算方式
其中 表示特征感受野大小,
表示层数,
,
表示输入层,
,
。
- 第一层特征,感受野为3
 第1层感受野[1]
第1层感受野[1]
- 第二层特征,感受野为5
 第2层感受野[1]
第2层感受野[1]
- 第三层特征,感受野为7
第3层感受野[1]
如果有dilated conv的话,计算公式为
三、更上一层楼
上文所述的是理论感受野,而特征的有效感受野(实际起作用的感受野)实际上是远小于理论感受野的,如下图所示。具体数学分析比较复杂,不再赘述,感兴趣的话可以参考论文[2]。
 有效感受野示例[2]
有效感受野示例[2]
下面我从直观上解释一下有效感受野背后的原因。以一个两层 ,
的网络为例,该网络的理论感受野为5,计算流程可以参加下图。其中
为输入,
为卷积权重,
为经过卷积后的输出特征。
很容易可以发现, 只影响第一层feature map中的
;而
会影响第一层feature map中的所有特征,即
。
第一层的输出全部会影响第二层的 。
于是 只能通过
来影响
;而
能通过
来影响
。显而易见,虽然
和
都位于第二层特征感受野内,但是二者对最后的特征
的影响却大不相同,输入中越靠感受野中间的元素对特征的贡献越大。
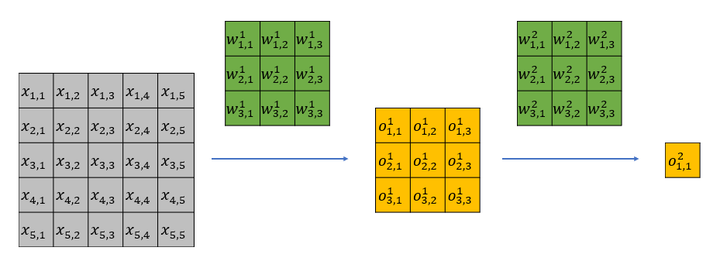 两层3x3 conv计算流程图
两层3x3 conv计算流程图
四、应用
- 分类
Xudong Cao写过一篇叫《A practical theory for designing very deep convolutional neural networks》的technical report,里面讲设计基于深度卷积神经网络的图像分类器时,为了保证得到不错的效果,需要满足两个条件:
Firstly, for each convolutional layer, its capacity of learning more complex patterns should be guaranteed; Secondly, the receptive field of the top most layer should be no larger than the image region.
其中第二个条件就是对卷积神经网络最高层网络特征感受野大小的限制。
- 目标检测
现在流行的目标检测网络大部分都是基于anchor的,比如SSD系列,v2以后的yolo,还有faster rcnn系列。
基于anchor的目标检测网络会预设一组大小不同的anchor,比如32x32、64x64、128x128、256x256,这么多anchor,我们应该放置在哪几层比较合适呢?这个时候感受野的大小是一个重要的考虑因素。
放置anchor层的特征感受野应该跟anchor大小相匹配,感受野比anchor大太多不好,小太多也不好。如果感受野比anchor小很多,就好比只给你一只脚,让你说出这是什么鸟一样。如果感受野比anchor大很多,则好比给你一张世界地图,让你指出故宫在哪儿一样。
《S3FD: Single Shot Scale-invariant Face Detector》这篇人脸检测器论文就是依据感受野来设计anchor的大小的一个例子,文中的原话是
we design anchor scales based on the effective receptive field
《FaceBoxes: A CPU Real-time Face Detector with High Accuracy》这篇论文在设计多尺度anchor的时候,依据同样是感受野,文章的一个贡献为
We introduce the Multiple Scale Convolutional Layers
(MSCL) to handle various scales of face via enriching
receptive fields and discretizing anchors over layers
引用:
[1]convolutional nerual networks
[2]Understanding the Effective Receptive Field in Deep Convolutional Neural Networks
目标检测网络train from scratch问题(part9)
注:这篇文章是在何恺明那篇讨论train from scratch的paper之前写的。
大多数目标检测网络的backbone都会在ImageNet数据上pretrain,第一个提出train from scratch的是DSOD,最近DropBlock论文里也顺便做了一个train from scratch的实验。而且两篇文章的实验都显示,train from scratch跟pretrain效果相当,甚至略微好一些。
After fine-tuning the whole detection framework on “07+12” trainval set, we achieve 70.3% mAP on the VOC 2007 test-set. The corresponding training-from-scratch solution achieves 70.7% accuracy, which is even slightly better[1].

DropBlock论文实验表格
DSOD提到他们目标检测网络能train from scratch的关键是
One of the key findings is that deep supervision, enabled by dense layer-wise connections, plays a critical role in learning a good detector.
DropBlock论文认为目标检测网络能train from scratch的原因在于
The results suggest model regularization is an important ingredient to train object detector from scratch.
通过我自己的实验经验,以及个人理解,我认为目标检查网络能train from scratch的关键是:
- one stage结构
one stage结构比two stage结构更加end2end一些,更利于train from scratch。
- 训练充分
我们可以看到无论是DSOD还是dropblock里train from scratch的retinanet训练时间都比在预训练模型上训练的时间要长,这个保证了训练足够充分。或者说train from scratch的时候,需要额外的训练时间先让网络跟预训练网络同一起跑线。也可以这样理解,在pretrain网络上训练目标检测器时,总的训练时间=pretrain分类器的时间+训练目标检测器的时间。
我认为deep supervision的作用主要是有利于训练比较深的网络,并不是train from scratch的关键。如果网络比较浅,即使没有deep supervision,同样可以train from scratch。
就如同在图像分类中,残差结构是训练深层卷积神经网络的关键,但不能说残差结构是训练卷积神经网络的关键,因为当网络比较浅的时候,即使没有残差结构,网络同样可以学得很好。
[1]Shen Z, Liu Z, Li J, et al. Dsod: Learning deeply supervised object detectors from scratch[C]//The IEEE International Conference on Computer Vision (ICCV). 2017, 3(6): 7.
[2]Ghiasi G, Lin T Y, Le Q V. DropBlock: A regularization method for convolutional networks[J]. arXiv preprint arXiv:1810.12890, 2018.
文章(part10)

图1、全卷积网络图解
最近一个月先后想明白了目标检测和图像分类、语义分割和图像分类之间的联系。
通过论文《Single-Stage Multi-Person Pose Machines》和《PolarMask: Single Shot Instance Segmentation with Polar Representation》,进一步找到了图像分类、语义分割、图像分类、多人姿态估计和实例分割之间的共同点。
即这些任务对应的模型大部分是全卷积神经网络,例如单阶段目标检测、语义分割等等,即使不是全卷积神经网络的图像分类模型,只要将最后一层fc换成1x1的conv,也就转换为了全卷积神经网络。
所有的任务都可以统一为一个全卷积神经网络,该全卷积神经网络输出的特征图如同昆虫的复眼,每个grid为一只眼睛,每只眼睛所看到的东西不一样,但是每只眼睛的视野范围相同(即,每只眼睛的感受野大小相同),每只眼睛单独工作,互不影响。具体可见图1,图像输入到全卷积网络中,输出的特征图大小为4*4,中间2*2个眼睛,每个眼睛看到的是图像不同的部位。
然后每只眼睛会判断:1、它看到了什么物体(类别);2、这个物体有什么特点(属性,可选项)。
以图像分类为例子,每只眼睛(因为使用了global average pooling,图像分类只有一只眼睛)会判断它看到了什么物体(类别)。
以语义分割为例子,每只眼睛会判断它看到了什么物体(类别)。
以目标检测为例子,每只眼睛会判断它看到了什么物体(类别),这个东西的x offset、y offset、w、h分别是多少(属性)。
以实例分割为例子,每个眼睛会判断它看到了什么物体,以该眼睛所在的地方为中心,该物体的36条极线分别有多长(属性)。
其他基于CNNs的计算机视觉任务可依次类推。
总结一句话就是:基于CNNs的任务的核心是全卷积神经网络,全卷积神经网络输出的特征图像昆虫的复眼,每个grid都是一只眼睛,每只眼睛的感受野相同,但是看到的内容不同,每只眼睛独立判断它看到了什么东西,这个东西有什么属性。
根据这一点,我们能更好的理解业界为了解决某种计算机视觉任务而设计的模型,当面对业界还没有研究过的计算机视觉任务时,我们也能自己设计出模型。
专访文章(part11)
闵万里博士的新办公室在深圳蛇口,推窗就是大海,跟他新事业一样崭新而充满未知。
我对他华丽的人生履历很熟悉,同时对他的新事业感到好奇。
他才41岁,但已在学术、产业都遐迩闻名。
14岁在合肥,他是中科大少年班天才少年中的一员。
18岁远赴美国求学于芝加哥大学攻读博士。
25岁在要求苛刻的统计领域凭满纸数学公式的论文获得博士学位。
其后他先在IBM的纽约办公室待了6年,是蓝色巨头里雄心勃勃的年轻研究员。
再后来2010年,他来到新加坡,即将准备把IBM探索的“智慧城市”项目雏形在狮城落地。但当时计算很贵、AI复兴还遥远无边,他也还没有实现从理论到实践、论文到产业价值创造的初衷。
这是他离职跳槽的核心原因。2年后,他又回到了大洋彼岸,出现在Google的山景城总部。这段经历很短暂,但收获了他其后被人所熟知的花名“山景”。

2013年,他被阿里巴巴说服,决定拥抱变化,回国落户杭州,其后一待6年,开创了一个全新的业务和部门。等到他临走前,那个叫“机器智能”的部门从无到有,从1个人到400多人,而“机器大脑”计划也开始在各个行业落地发芽。
特别是用AI技术和云治理杭州交通、改善救护车效率的案例,不仅有口皆碑,并且因之写就的学术论文,再次斩获全球顶级期刊的认可。
离开阿里前,他是集团副总裁,是阿里云机器智能首席科学家,是受人尊敬的“山景博士”。他才41岁,巨头之下,前途依旧不可限量。
所以当他宣布离职创业,成立风险投资公司“北高峰资本”的消息,自然令人意外又不得其解。

有评论祝福:跟他共事有过交集,知晓他的为人和才学,前路必将远大、光亮。
也有评论纯属吃瓜式惋惜,只知道他的履历和天才,认为年纪轻轻就投身投资,未免有些可惜——更希望他能留在产业中发挥更大的价值。
知我者谓我心忧。
在新征途的新办公室里,闵万里说:离职创业,是为了更好实现产业之志,并且现在天时、地利、人和都具备了。
他表示开启的新事业前无古人。投资为名,但资本、技术、产业和人才都具备才得以达成“四位一体”,与众不同的是,北高峰资本的着眼点是农业和工业等传统领域。
闵万里说:我从未忘记,自己出自大别山农村。农业是人类发展之本,但在技术变迁的长河里,它被遗忘太久了。
所以闵万里和他的“北高峰资本”,究竟为何出发?从何出发?又将会到哪里去?他的新价值、新边界和新格局又是什么?
一切都在量子位这万字专访实录中。

要点
- 新技术革命当前,有搞AI、搞机器人,但很少有人下农田下车间。
- 四位一体:团队、时机、资本和技术方法。
- 走群众路线,抛弃技术精英那种从天上往地下俯视的方式。
- AI专家们进入传统行业,太过迷信深度学习,这不是长远之道。
- 中国上一代创投的“思维黑洞”:被日活量绑架,被流量绑架。
- 我对农业情有独钟,我自己就是从农村走出来的。
- 我融资拿钱的过程也很神奇,甚至没来得及写BP。
- 马云给我的启发:敢于放弃当下的局,去追求一个更大的局。
- 在传统行业数据恰恰不是石油。
- 没有云计算就没有今天的AI,但是没有AI就没有未来的云。
- 在学在产在VC不是本质,本质应该是最大化价值创造。

对话实录
创业VC:我要下农田、车间
量子位:先讲下您创业做投资的来龙去脉吧?
闵万里:我在内部告别信里说:创办了一个风险投资基金,聚焦传统产业(制造业,农业,医疗)及周边,用云智能技术注入和资本加持,组合型赋能、推动传统产业实现数字化转型和智能升级。
所以某种程度上,它不是一个传统VC或投资基金,准确来说它应该是一支技术性基金。
我的核心逻辑有两个:一,确保我的技术和经验在传统行业中可以创造价值;二,创造的是新价值。
量子位:举个例子?
闵万里:最传统领域,比如石油。今天某油田快枯竭了,但我有新技术、新金刚钻,可以再往下突破200米,然后能继续把石油开采出来。
这是新技术才能带来的新价值,但通常都会被忽略,我们创造就是这种价值。
量子位:这个难度在什么地方?
闵万里:难度可能要比研究无人驾驶还大。因为你要在一个很多人刨过的地里刨出油水,这是对不确定性的一种选择。
一个不确定的领域,也是一个新战场,你要在其中找到新价值。
而且像石油这样非常成熟的行业,你要再去找到新价值,其中有非比寻常的不确定性。
因为可能的价值都已经被找到了,有可能你最后颗粒无收,所以我说选择“在别人刨过的地里再发现价值”,这是一个具有挑战的选择。
量子位:既然“不确定性”如此明显,为什么还要选择?
闵万里:因为这两个产业都是根本,农业和制造业,人类赖以发展了上千年,对吧?
互联网带来巨大繁荣,但根本上离不开这两大产业。
电商再强大,也要靠制造。社交再发达,没有农业我们没法儿吃饭。
然而在科技进步面前,技术革命永远有它遗忘的角落,制造和农业,就是两个被忽视的角落。
所以新技术革命当前,有搞AI、有搞机器人,但很少有人说“我要下农田”、“我要下车间”。
量子位:或许是因为“天下熙熙,皆为利来”?
闵万里:坦白讲,事物一分为二。在别人刨过的地里再发现价值是有难度的,但并非没有可能性。
因为阿里云的经历,过去几年农田和车间我都去过,这些地方恰恰有着被忽视的最大价值空间。
因为真的被遗忘太久了,与时代脱节的厉害,才最具备逆势而行的勇气。
所以这个问题明确一下就是:在确定性场景下寻找不确定性价值。
确定场景:几千年来都是确定的,人都要吃饭穿衣。
不确定价值:有被新技术赋能转型升级的机会。
某种程度上,我仍旧在做在阿里时的事情:赋能传统行业。但现在我还有资本加持,这会让金刚钻更有动力和保障。
量子位:时机也具备了?
闵万里:其实最大的痛点,是如何以规模化方式直面产业界痛点,把合适的技术、方法输送给他们。
而这个过程,我在阿里这些年都经历、积累过了,在很多垂直行业都取得过成功。
之前讲我创业是“二位一体”,实际应该是“四位一体”:时机、资本、技术方法,再加上我愿意下车间、下农田做这件事。
我要做的就是直接加速传统行业的智能化转型升级,用技术让整个产业真正受益。

方法:不给剑,给剑谱
量子位:怎么开始?
闵万里:亲自下手干。我自己就是一个“四位一体”的组合,带资金、带技术,然后放大器、加速器。
我相信干出成绩后,就能吸引更多技术同行、资本关注这里面的机会,那么接下来将大有可为,去实现更大的变革。
量子位:有投资案例了吗?
闵万里:正在看两个制造业项目。
量子位:投资传统行业会被认为见效慢。
闵万里:恰恰相反,有些是立竿见影的。我们之前做工业大脑、农业大脑,成功案例基本都是一年之内交付且全部回款。
传统行业有自己的规则:真的假不了,假的真不了,是真是假,最慢一年之内也能见分晓。
它们的价值已经无需论证,你用新武器、新方法,很快就能找到新价值。
主要就是农业亩产增加、产线废品率降低、能耗降低……这几件事。
大道至简,这都是被遗忘的价值洼地。
量子位:但具体如何选择什么样的公司展开?标准是什么?
闵万里:首先,我们要投的是有产业背景的公司,而不是纯技术公司。
因为纯技术公司太多了,有产业背景才是稀缺的,这些公司它熟知行业背景、痛点,只是缺AI、缺云等方面的能力和认知。
所以我管他们叫“近水楼台未得月”。
量子位:那如何帮他们得“月”?
闵万里:核心是精准注入方法论。现在有很多云产品,都是“剑”,但我不一样,我给的是“剑谱”。
很多新技术就像新武器,但光有新武器没有战法是没什么威力的。
我通过投资,附加方法论,帮助他们成为行业的数字化转型专家。

回报:创造价值就不必担心估值
量子位:这种投资模式,回报够吗?
闵万里:这种回报不是单一的。
一方面,是转型升级后直接带来的价值创造回报。
另一方面,转型升级之后,资本市场对它的重估,就不再是传统产业,也不是周边的IT服务商,而是整个产业数字化转型的引领者。
过去几年,有些传统模式一旦套上AI的概念都会估值翻番。这体现了市场对新概念的渴求,愿意给高估值、预期高回报。
如果现在你真正地实现了新价值的创造,而且还成为了整个产业迈向智能化的引领者,为什么不会有高回报?
大逻辑很明确,关键就是先把价值创造做出来。
这就是为什么我需要基金去做的原因,有保障,不必在投入方面去说服。
量子位:重要的是LP也相信这套逻辑。
闵万里:因为这套逻辑不是设想,已经在多个行业取得显著成果。
很幸运我之前在阿里有团队支持,在多个垂直行业都有了成功案例,并且我认为我们已经找到了可通用迁移的窍门。
很多案例现在都是公开的,攀钢、信息光腾、天合光能、恒逸石化、中策橡胶、金星通讯、迪森热能……光听名字,就知道这些行业有多传统、有多不同。
在这么多实践案例之后,我认为经验模式是可以泛化的。
所以我离职创业,如果只选一个行业,那就太可惜了。我希望做的是一个改变产业的事情。
量子位:也决定了你现在的模式和做事方式?
闵万里:是的,我一定要找一种机制能够同时把这些方法论投射、注射到这些产业当中去,让这些产业能够同时享受到这些新技术的价值。
所以我立刻排除了那种融资创业的可能性,我必须选一个行业聚焦,打穿打透,不然的话是没法创业成功的。
另外,我还要找到一种方式,能够同时注射阿里云和产业,填平二者之间的鸿沟。
我要对接的两方很明确,一边是阿里云或者掌握智能化转型的技术精英,一边是巨大的传统产业。
而且最关键的是,这种转型并非标品。
量子位:这又跟普遍的认知有所不同。
闵万里:很多人认为企业、产业数字化转型可以标准化去复制,我认为不可能。
这就跟医生看病有点像,你要开药,就要望闻问切因人而异,不能看似感冒就都给两粒头孢。
在传统行业智能化转型里,没有一个放之四海而皆准的东西。
就算是你有很多标准化的产品,也可能一上来就标准化覆盖,你需要先服务,找到病根和切入点,然后把方法和产品给他。
所以这也是我无法留在阿里云完成的事情,因为我会受限于阿里云本身的产能,我需要带着产品和人去服务客户。

量子位:不能让客户主动找阿里云?
闵万里:我确实想过,理想的情况当然是传统产业被激发,然后敞开心扉拥抱AI,打消沟通成本和障碍。但早几年的实践说明,这种想法并不可行。
早几年对方对你是极度怀疑的,你进入传统行业,对他们而言完全是新人,不懂工业、不懂制造业,这个时候你要推广方案就需要时间、解释起来也不轻松,配合度还低。
进行了2年之后,好处是对方不再怀疑了,但是改成自我怀疑了。他们不知道自己的工厂是否具备转型的可能性和可行性,这种智能化转型的红利,它们这个行业龙头能否享受到,毕竟你讲的标准化案例,对方也不具备。
如果我留在阿里云,还是一个线性增长的过程。而今天这种方式,就是一种激活,一种杠杆、一种放大器。
量子位:为什么离职创业就释放了活力?
闵万里:离开阿里云有了杠杆、资本的力量,加上方法论的注入,能够让传统产业的人主动的敞开心扉,思想解放。因为我钱都投给你了,跟你成为了一国;你理解我讲的,思想一解放,之前积蓄的生产力也都释放出来,我再提供正确的方法论,一下子就是干柴烈火。
星星之火,有两种方式可以燎原:
一种方式,靠东风来吹,吹到哪里是哪里,吹到干柴就最好。但风不对,运气不好,火就会灭。
另一种方式更稳妥,我这东风猛吹草,把它往火堆上聚拢,火堆就会越烧越猛。
我认为后一种方式更快,核心是发动群众,走群众路线。抛弃技术精英那种从天上往地下俯视的方式。
真正埋头产业后,你才会发现原来被你忽视的价值空间会是如此巨大,光打一口井是不够的,你还要动用资本的力量、正确的方法,再配之以技术,进而让更多产业价值主动喷薄而出。
量子位:与阿里云也不是竞争关系?
闵万里:实际上是共赢。因为涉及标准云产品,我们就成了阿里云的客户,或者说给阿里云创造新客户。

人才:纯技术思维不适用,迷信深度学习太短视
量子位:人才从哪里来?
闵万里:我把这些帮助企业转型的人才称为教练。我都会亲自培训。
在阿里云的时候,我就亲自打造了一个岗位:DTC:Data Technology Consultant。
DT有两个含义,一个是数据技术Data Technology,一个是数字化转型Digital Transformation,一语双关。
他们像大夫,望闻问切,跟客户一起梳理出业务流程中的痛点,找到优化方式。
在阿里云时,这批人全部按照商学院的方式训练,我们把他们叫作梦之队、特种部队,人不多但精,一个行业两个人就够。
量子位:所以现在你这支技术基金需要的人才,更看重的是传统背景,而不是计算机?
闵万里:计算机领域我懂,我教就好了。我今天要做的是互补型投资,我有资金、技术和方法论,你有转型的决心和行业背景,你没有的我给,你有的我不必重复,双方化学反应,快速成长。
这是赋能型投资。而关键的DTC人才方面,我要精准注入一个角色给他。
量子位:相当于加强传统VC里的分析、咨询?
闵万里:这是必须的。但不只是对行业整体的判断,还要对赛道中的选手体检,有开药的能力。
可以把对方的难言之隐梳理出来,定量、优先级排序,然后从整体到细节,一层层结构化分解,最后进入具体执行。
你要在传统行业创造新价值,就要搞清楚:什么东西制约了你的产能,制约了你的效率,制约了你的利润率。
量子位:投前投后参与度都很深入。
闵万里:对,纯技术分解,或许只需要关注性能指标的提升,但现在需要关注的是如何传导到整体,而且形成价值闭环。
有点像4×100比赛里,你把第二棒速度提升了,但是二三棒没交接好还是没用的,最后的结果是各个环节传导的体现。
我们所有的动作都是为了最后创造价值,不是局限在中间某个环节的提升。
一个球赛,中场倒球再多、假动作再炫酷都没用,关键是为前锋创造射门机会进球。
量子位:这是思维问题?
闵万里:对,技术人员今天往产业走,我相信整体遇到的障碍就是如何把技术思维变成以业务需求为导向的技术思维、技术分解思维。
量子位:也有赋能传统产业的AI公司,但想走标准化产品和方案的路线。
闵万里:我绝对不看好这样做。To B有个特点,得量身定做。
同样生产轮胎橡胶的,A厂家的产线是从德国进口的、使用四年。B工的产线从日本进口、两年工龄。
你觉得你调节参数的产生的工艺参数都应该是一样的吗?这是不可能的。
我们To C做个App,点一下,无论喜不喜欢,损失的只是1、2秒钟。
To B产线,没弄好一个批次就得损失好几十万。
所以To B企业对于价值风险的考量非常严格,对那种似是而非的标准化产品容忍度非常低。
归根结底,一系列动作后不能传导到价值提升,只是搞个炫酷的大屏幕可视化之类的,根本没用。
量子位:传统行业的退出回报速度跟得上吗?
闵万里:我们谈VC退出回报,在互联网时代看规模化复制的速度。
传统行业这方面可能慢,但客单价放在那里。
我去年做工业方案,人均创造的价值有几百万,纯软件能实现这样的速度吗?
传统产业当中,边探索,边实施,边交付,边验收,边回款,一年创造的人均价值,可能是有些小技术概念公司一年的利润。
这充分证明了,我们不能简单地以你是用什么工具来定义价值创造。
现在到了跨界结合的时候,老眼光看新价值并不恰当。氢气和氧气在一起可能产生的是水,还可能产生双氧水,谁的客单价高?
所以回到回报问题,价值创造大、客单价高,回报也不可能低。
量子位:你的方法论是什么?
闵万里:To B需要定制化,但方法上有共性和规律。
我探索了几年,有心得,包括怎么样把业务流抽象为数据流,然后再用网络流,并找准关键节点下手。
这套方法论归根溯源,还是我10多年前博士论文中研究的东西。
我相信万物至繁终究归于至简,牛顿的三大定律,那么简洁的数学公式,结果就能把人造卫星送上天。
现在技术专家们进入传统行业,太过迷信工具型技术,对深度学习、AI非常痴迷,觉得锤子哪里都能发挥作用。搞黑盒子,这是短期行为,不是长远发展的正确道路。
离开杭州,摆脱流量思维
量子位:技术赋能产业,是不是也意味着有新评价标准的时候到来?
闵万里:一个很重要的问题:新技术在传统产业当中带来它整体的升级转型,所以就是你怎么衡量它的价值。
但归根结底,估值不能偏离价值。互联网也好,传统产业也好,估值都是基于价值创造、围绕价值创造展开的。
现在技术变革传统行业才刚刚开始,衡量变革的指标也在不断成型,比如效率提升、能耗降低……
但有一点,肯定不会按日活量之类的指标。
中国上一代创投里有种某种程度上的“思维黑洞”,被日活量绑架,被流量绑架。
这也是我离开杭州创业的原因。杭州说来说去,做什么都离不开“阿里巴巴”,围绕阿里生态做事。

量子位:那又为什么是深圳?
闵万里:刚才解释了为什么离开杭州,接着解释下为什么选择深圳。
今天我的第一个判断就是,珠三角制造业的整体转型升级压力是最大的,这里有改革开放最早的一批企业,区域性产业特点突出。
另外,这里的人思想活跃度最高,敢为天下先。
以后“北伐”与否不知道,但肯定会南下,比如东南亚,有很多农业和制造业的转型升级机会。
我现在越做越有信心,相信中国在很多垂直行业里的创新,尤其是AI实践是处于全球领先水平的。
我之前去澳洲、中东演讲,客户跟我说他们以前都想过,但都没机会做起来。
今天中国可能有全球最好的场景,技术也不弱,以后出海输出也大有可为。
我们最近就在看几个东南亚的农业科技项目。

对农业情有独钟,被新技术遗忘太久
量子位:别人说传统行业升级,通常指的是工业。
闵万里:我对农业情有独钟,我自己就是从农村走出来的,大别山的农村。
所以我知道中国农民几千年来都是看天吃饭,被新技术遗忘。
我跟LP说,今天想要做的事情,就是希望让工人、农民更早享受到人工智能和DT数据技术的价值。
让亩产增加一点,施肥少一点,灌溉水节约一点,我说这才是我要实现的价值。
今天我们做事的方法里,有一种就是希望激励农业和工业周边的人,让他们敞开心扉,我把正确的方法给他们,依靠群众,走群众路线。
量子位:你的LP怎么说?
闵万里:后来他不给了我这笔钱吗?我觉得从他们的格局和角度,也应该赞同人类发展肯定需要农业和工业的与时俱进。
如果农业、工业使用的还是300年前的技术,服务现在和未来,那太滞后和脱节了。
量子位:阿里的经历也帮了忙,成了你证明你模式的案例?
闵万里:是的,我前几年在阿里这么干,也都有别人的质疑,但我先干起来,当可以拿出东西来说话了,那个时候别还有什么办法质疑你?
用速度争取时间,用成果打败质疑。
之前阿里云就叫“阿里云”,我们参与努力后,现在是“阿里云智能”,我们证明了智能在产业中的效果和潜力。
所以还是回归本质,先别动不动就谈互联网模式,是不是可复制。先证明有没有创造价值、有没有创造新价值。
黑猫白猫,抓到老鼠才是好猫。这句话到今天依然是对的。
量子位:干就完了。
闵万里:现在不是模式太少而是太多,而且对互联网模式过度痴迷。
很多从业者宁可要每月一块钱的细水长流,也不要一次性拿200万,因为他们觉得细水长流稳定、可预期。
但很多人不思考,这其中的关键不在于你第一次收获的200万可以持续多久,而是你拿到200万的能力,是不是还能够帮你拿到更多的200万?是不是有另外的痛点你也可以帮解决?
所以今天这个时代,是一个能力不断变现的时代,能力就是最坚固的护城河。
量子位:这种认知也更符合产业落地。
闵万里:之前很多人都说产品是护城河、技术是护城河,但我觉得背后的能力才是护城河——你源源不断打造产品和技术的能力。
一个成熟产品和技术有什么护城河?人都这么聪明,今天你搞出来了,明天满大街都是。
所以那种迷信互联网模式——搞一个稳定产品躺着有收入的模式,在To B产业里不现实。
这里的情况是,一旦你停止了价值创新和创造,可能就要被市场淘汰。

几亿美元融资,我连BP都没写
量子位:那你的创业有参考吗?
闵万里:我想谈谈最近常思考的例子——通用电气。
历史非常悠久,追溯到1879年爱迪生发明电灯泡,然后1882年在纽约曼哈顿成立发电厂。之后通用电气没有停留在灯泡上,随后发明了电气机车、微波炉、电磁炉、X光机……直到1982年的医疗CT机。
这100年里,通用电气几乎踩在了每一个时代节点上,踩准了那个时代他创造价值的方式。
他最初是做照明,但并没有叫“照明电气”,而是通用电气。
围绕“电”这项根本技术的价值创造。但1982年医疗CT推出之后,GE似乎就把这个关键忘了,搞了很多业务创新,搞金融创新,唯独没有继续价值创造。
所以去年8月16日,GE被踢出了道琼斯30——霸榜100多年后。
GE的工业互联网平台到处叫卖也没人买,非常凄惨,不得不分拨,但没人愿意接手。
我自己把GE的这段历史叫作“辉煌100年失落30年”,而且这后30年里,参与其中的还有大家奉为管理学大师的杰克·韦尔奇,他搞了很多管理变革,但结果也看到了,或许对管理大师也需要重估了。
现在我也跟团队讲,我们的目标是要做General Computing——通用计算,不是非得上云、不是非得深度学习,核心是把业务本质问题找准、并且解决掉。

量子位:大道至简,万佛归宗。
闵万里:说实在的,我们今天有太多思维,也有很多大咖大师,大家一上来先讲模式,先说是XX领域的谁谁谁。
但是人们没看到的是,那些企业家都是掌握了独门绝技、不断在创造价值,然后才百尺竿头更进一步。
如果内功还没练好,就开始花拳绣腿,结果只会越来越差。
所以我说价值创造这件事,一定会是所有企业乃至行业最后必须回答的根本性问题。
对于我的创业来说,就是通过资金加技术的方式,给被投的企业创造价值,给整个产业创造价值。
这其中的两层我现在都理顺了,解清楚了,感谢之前的那些产业实践。
量子位:什么时候这些思考成为现在的体系?
闵万里:应该是春节的时候,那时候钱已经拿到了。
量子位:一般都是想明白再出去找钱。
闵万里:我觉得钱真的不是问题。我从春节到6月(离职),主要是进行内部沟通、交接清楚,我不想因为我的离开,让亲手做起来的业务和部门就此偃旗息鼓。
我拿钱的过程也很神奇,都没有BP,没有写融资材料,就阐述了一下我将来想做的这件事,对方就给钱了。
量子位:是阿布扎比的私人投资?
闵万里:是,但具体姓名背景就不公开说了。当时我还有朋友怀疑对方会不会是骗子,我说哪有骗子给钱的,而且人家的各种东西都在那儿放着。
量子位:太因缘巧合了。
闵万里:我当时在迪拜演讲,主要是城市大脑的东西,他们(LP)还不知道我做的工业案例等,但当下就给予了肯定。
第二次再见面,我把工业、农业,以及做这件事的方法思路都分享给了他们,然后就得到了这个创业的大天使。
量子位:规模多少?
闵万里:第一期有几亿美元,可以先把这种投资方式启动起来。
我有时觉得自己比爱迪生还要幸运,他创业前没有“阿里”这样的大平台,融资还要到处坐火车。而我生逢其时,很幸运。

马云启发:敢于放弃当下的局,去追求一个更大的局
量子位:除了一个大平台,阿里对你的影响是什么?
闵万里:更重要的还是思想。我真的觉得这在你职业生涯的成长过程中非常关键,如果没遇到一些像马老师这样段位的人,你自己就没办法再上一个段位。
你一定需要有人给你树立一个榜样,你会发现到了这个山头,前面还有更高的山。
如果你只看到,这一路过程很艰辛,现在眼前已经有这么多很美好的风景可以享受了,你就永远攀不上去了,你也就到了职业生涯的顶点了。
我一度以为阿里就是我的顶点,但因为马老师他们,我今天发现阿里其实是另一个起点,我又有了新的目标。
量子位:马云他们给你最大启发是什么?
闵万里:敢于放弃眼下,敢于放弃当下的局,去追求一个更大的局,我觉得这才是最大的启发。
量子位:在阿里这几年,你印象最深的是啥?
闵万里:2015年6月1日,我刚到阿里云,六一儿童节,就我一个人。
然后慢慢开始后来ET大脑业务的试水,最早是帮助浙江交通进行整个浙江高速公路的路况预测,2015年10月份完工,当时就在国内上了头条。
2015年全年里都是7个人的团队,但由于第一个项目的成功,上面很快决定给我加持,2016年3月开始,一下子划了30个人的名额给我。
后来一年内又翻一番,等到工业大脑也见成效了,又增加了270人,直到我今年离开,团队已经有430多人了。
量子位:你对数字、数据都记得很准?
闵万里:原因很简单,因为我真正用心去做了的。只有倾注了心血,才能够铭记于心。
量子位:这段“从0到1”的经历,也算是为现在创业做了铺垫。
闵万里:我觉得证明了一件事——当你在不断证明自己的时候,你也会得到资源,甚至资源会向你靠拢。
量子位:有合伙人吗?
闵万里:没有,还在找,主要找的是投资合伙人,因为投资是很专业的活,我自己没有经验,需要一个非常资深的投资合伙人。
团队其他成员的话,我有信心自己培养。我从阿里离职创业,一个人都没带走,因为真是心怀感恩的。
回到“护城河”问题上来,具体人才本身也不是护城河,培养团队的能力才是护城河。
马老师他们自己也分享过,当年的18罗汉,不一定都是最优秀的,但他们善于学习,经常组织集体学习。
不是说三个臭皮匠顶个诸葛亮吗?那18个人就是6个诸葛亮。
我现在也是怀着这种心态的,谁也不是天生什么都会,都是学习、实践出来的。
量子位:有时候找人也是降低学习培养过程中的时间风险吧。
闵万里:风险不是问题。在我今天说的投资逻辑中,已经说了先用技术方式精准地判断价值创造,那么风险的不确定性就会降低很多。
某种程度上,我是用技术的确定性,来对抗风险投资中的不确定性。
量子位:之前也没有过个人天使投资的行为?
闵万里:真没有过。但如果回顾我过去打垂直行业的经历,就会发现其实是由很多“命题作文”组成的。
在阿里每个财年结束都是要交成绩单的,否则项目就会有被砍掉的担忧。
大公司内部也会面临有限资源、有限时间和精力,还有开拓新业务的挑战。
现在只是换了个姿势做选题,做“命题作文”。

数据恰恰不是新时代石油
量子位:但你之前是在最大的巨头公司,即便是“有限”,在数据资源方面也有优势。
闵万里:我觉得这里有普遍的认知偏差。
首先是对于数据,特别是传统产业的数字化升级,其实核心在传统产业中,科技巨头平台没有突出的不同。
其次,大家听过了很多“数据是新时代的石油”,但在传统行业,数据恰恰不是石油。
很简单,石油是不可再生资源,用一点少一点,但传统行业里,生产环节一启动,数据是源源不断产生的,它是一个通货膨胀的东西,又是会迅速贬值,过期作废的东西。
所以“数据是新时代石油”在传统行业里是不成立。
相反,正因为数据在这里不是石油,价值也转瞬即逝,更应该迅速抓关键把它利用到极致。
以前没有云计算,算不快,可能客观条件上有利用难度。但现在有了云计算,有AI这样的技术,客观条件就成熟了。
所以也是有对数据的这种认知,让我们做很多案例的时候,更迫切找到最关键的、数据生成度最密集的控制环节,这样才能在光伏、橡胶,石化等行业干出名堂。
量子位:听起来这是趟过很多坑之后的总结。
闵万里:如果今天再给我一次机会,我可能就不做了,太累了,说实在的,很辛苦。
当时真的是又要写代码又要下车间,还要不断科普,相互理解对方的行业术语。
量子位:你得亲自写代码?
闵万里:是啊,最早几个案例,都是我亲自写代码、写公式,每个大项目核心的算法设计,我都亲自把关。
拥有这些经历的好处就是今天对于流程里很多障碍、潜在的问题,关键性节点,我都特别清楚。
当时我团队里的人最怕跟我汇报,因为我会当场让他写流程公式,你不用跟我说解了多少bug,怎么设计的,你就把基本逻辑用最简单的公式表达出来就行。
万物至繁归于至简,牛顿三大定律多简明的公式,就能让火箭卫星上天。
量子位:写公式倒不常见。
闵万里:现在也是,被投对象来了我也要求他们写公式、逻辑推导。
我们市场上充斥太多靠新名词和新术语去融资的人,我觉得都是浮云,一有风吹草动就会被当成炮灰。
事情的本质,事物的基本面,一定是简朴有力的。
技术交汇爆发的大时代
量子位:为什么创业取名“北高峰”?
闵万里:这是杭州的一座山,灵隐寺就在这座山上。在山上眺望,你能看到钱塘江,看到西湖,看到阿里巴巴园区。
钱塘江是时代大潮,西湖是千年美景,又有阿里巴巴这样的公司,这不就意味着你是站在巨人肩膀上吗?
最初取名就想找地名,先在深圳南山附近想了想,没有太好的,后来就灵机一动,干脆直接叫“北高峰”。
我离开杭州之前,团队送行,写了一副对联赠别:
白云飞掠白云山,山景趟过山景木。横批:南山北峰。

量子位:也有站在时代浪潮之巅的意思,有云、有AI……
闵万里:必须的,真是生逢其时。
早些年没有云,AI计算是很昂贵的,我最早在IBM开展智慧交通灯项目时,一年下来就要花费好几千万新币,普及是很难。
现在好了,云计算来了,用卖服务的方式使用计算,跟用电一样。现在大学生也能负担得起超算,用十分钟二十分钟就行,用完还回去,门槛大大降低。
深度学习等使用大数据的方法也成熟了,能够让我们更好的实时计算和深度挖掘数据,寻找变量之间的定性关系,这些对于传统行业的帮助很大。
所以我也说,没有云计算就没有今天的AI,但是没有AI就没有未来的云。
量子位:之前马化腾表达过云、AI和大数据的关系,但没人从时间维度思考过其中关系。
(马化腾认为:数字化转型就是让企业在云端用AI处理大数据)
闵万里:我因为都经历过,自己实践过,从云计算还没成为概念的时代,到AI因为深度学习复兴的现在。
而且回头来看,云和AI,解决了生产力和生产关系的问题。
它们带来先进的生产力,可以让有生产资料、有产业场景的这批人,变得更好,创造新价值。
量子位:北高峰的投资风格会是什么?
闵万里:我们要做的事和做事的方法都说了,最后投资的话,还有一个心态问题。
我对回报的期望是长期的,你看我们的投资领域和理念,并不是在短期内随波逐流追热点,追热点只会成为分母。
要找到蓝海市场,你就得在寒冬时节出海;春暖花开的时候,大家是一窝蜂下饺子,众声喧哗,很难分清做实事的和讲故事的。
投资都讲风口,我很理性,我觉得很多时候你要具备掌握风口的能力,在风还没起的时候就开始造风。
在学在产在VC,核心是最大化价值创造
量子位:其实您离职消息宣布后,我们后台最多的评论是“这样学术的人才竟然做投资基金去了”,有惋惜的意思。
闵万里:学术也好、在产业界也好,最后核心还是如何最大化创造价值。
我2002年开始博士论文课题研究,核心是基于数学理论推导的统计算法设计。
2003年底投出,2005年发表。数学论文的审稿周期一般都很长,但当时有个匿名评审说:
“这篇稿子的作者会终生以这篇文章为荣。”
博士论文后来确实成了我的成名作,里面全是数学,十几页的数学公式推导,思考期间在图书馆里经常感到很沮丧,老是证不过去,几个证明的环节有时会死死卡住,后来还是受惠于20世纪50年代哥伦比亚大学的一个华人教授周元鑫写的一本《概率论》的教材,里面的一个定理,帮助我跨过了难关。
后来就是这篇论文,开创了随机过程领域对于非独立过程的大样本性质的理论体系, 打破了1960年以来的Strong Mixing理论局限,成功应用到了交通流,股票等领域。
2009年有机构统计,这篇论文成为过去5年随机过程领域十大被引用次数最多的论文之一,在很多实际领域发挥作用。
这也给了我另一层启示,我可以用自己的文章、自己的理论,然后自己选择赛道去创造价值。
但这样开创性的东西,你会一直有吗?学术研究有时候持续保持这样的开创性不单单需要努力。
或者你就用常见的玩法,随时看别人最新发的论文研究,找到不足之处,马上跟一篇,但这样价值又有多大?
如果真的能把理论研究在更多领域的实际应用中放大,价值就出来了。
量子位:有时候学术理论和实际应用,界限被划定得太粗暴了,只看title而不是成果。
闵万里:我的研究成果其实也没有停止。2011年我又发表了一篇新论文(其实2007年就完成了,IBM因为商业考量内部审批了很久),把在IBM新加坡任职的核心成果给理论化了。
还是用数学的方法去搞交通工程,再次成为这个领域里被引用次数最多的文章。

然后进入阿里后,开始搞ET大脑,继续把理论和实践推进。
在今年离职阿里前,5月1日,我收到了IEEE的论文接收反馈函,论文的核心内容是全局数据模型对救护车路线和红绿灯的优化。
在之前的阿里交通大脑里,这是一个标志性成果,而世界范围内,这样的文章也是全新的。
所以论文不用多,我每个阶段都有一篇代表作,既对自己的有一个交代,也对学术和产业有实际价值,两三篇足矣。
科研更多的是理想状态下的自我修炼,但现实应用中条件永远不完美,一进入现实,那就成为了该怎样寻求最优解、近似解。
问题的本质不是身处何方,不是做学术还是在产业,而是用现实问题视角,思考需要用什么样的技术来解决行业问题。
永远都有时髦的新技术,然而那些时时把热点当做核心出发点的人是走不远的。
我们带着技术进传统产业的时候,绝大部分人不看好,觉得是价值洼地,但这种时候我们偏向虎山行,最后用结果证明我们的坚持和判断。
这其中,也是对理论和方法的自信吧。