说实话,老师的书写的确实是不错的,对于基础薄弱的我来说很是适用,基本不需要什么操作系统和内核的知识,也能够把书上的知识掌握。当然,边看边动手这个是不能少的。下面回归正题。
函数调用堆栈
在上一章的学习中我们了解了在调用函数的时候讲使用到堆栈进行临时的地址存储,这里我们将进一步详细分析函数调用堆栈。
简单来说,堆栈在C语言程序运行时的具体作用分为2种:
- 1.记录函数条用框架和路径
- 2.提供参数与变量的存储空间
接下来,我们慢慢了解堆栈是如何实现这些功能的(由于目前能力有限,暂时只分析函数调用堆栈框架的过程)。
堆栈相关的寄存器
- ESP:堆栈指针,即栈顶指针。
- EBP:基址指针,即栈底指针。
在c语言中我们了解到了栈的基本结构,以及它先进后出的结构特点。这里给出在x86体系下的堆栈空间,以方便理解。需要注意的是栈顶为低地址,栈底为高地址。
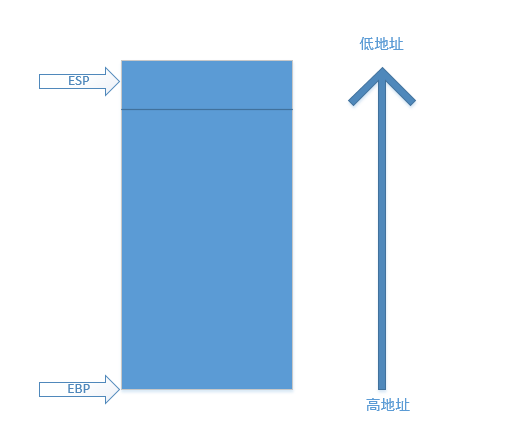
那么,当我们给出了栈的栈顶和栈底指针之后,栈的出入栈操作就非常方便了。
出栈与入栈
- push:栈顶地址减少4个字节(这里的4个字节是根据操作系统的类型进行判断的,在这里使用的为x86体系结构,int型变量为4字节,故减少4个字节以足够存放,空出一个存储单元),将操作数放入栈顶存储单元。
- pop:栈顶地址增加4个字节(理由如上),并将栈顶存储单元的内容放入操作数。
上一章已经对push和pop操作进行了详细的分析,这里我们把这两种操作带入到函数调用中具体分析。
CS与IP
作为x86体系结构中最关键的两个寄存器,CS与IP指示了CPU当前要读取指令的地址。其中CS为代码段寄存器,IP为指令指针寄存器。正如书中所提到的,CS:EIP(这里对于CS:EIP的具体规则是%CS*0x10+%EIP)总是指向下一条的指令地址。而指向下一条的指令分为如下两种:
- 顺序执行:总是指向地址连续的下一条指令。
- 跳转/分支:执行这样的指令时,CS:EIP的值会根据程序要被修改。
分析
简单对call和ret命令的过程进行分析。
call target
这条指令实现了两个效果
- 将CS:EIP中的下一条指令的地址保存在栈顶
- 设置CS:EIP指向被调用程序

执行call命令时,如图中所示,先将cs:eip存入栈顶以方便之后的return命令找到此时的cs:eip值,然后在此基础上进行函数调用堆栈框架的建立。
pushl %ebp
movl %esp, %ebp
依旧如上图所示,先将ebp指向的地址压入栈顶,而后再将ebp指针指向栈顶,这样便构成了一个新的框架,即函数调用框架。

紧接着执行完该函数之后我们需要拆除框架并return。
movl %ebp, %esp
popl %ebp
与建立框架相反,这里的步骤也是反过来的。先将ebp中所指的地址赋给esp指针,即将该框架删除,而后取出栈顶单元赋予栈底指针,此时栈底单元存放的即是最初的ebp栈底指针,则ebp指针回到最初的起点。再使用ret命令取回存放在栈顶的cs:eip值,结束。
至此,简单的函数调用框架就分析到这了,关于函数参数的传递与提供局部变量的空间暂时不讨论,等深入学习之后再进行总结。
借助已开发好的简易linux内核模拟存储程序计算机工作模型
关于C代码中内嵌汇编写法的教程书中已经非常详细了,这里不再进行总结,直接进入主题。
虚拟一个x86CPU硬件平台
sudo apt-get install qemu # install QEMU
sudo ln -s /usr/bin/qemu-system-i386 /usr/bin/qemu
wget https://www.kernel.org/pub/linux/kernel/v3.x/>linux-3.9.4.tar.xz # download Linux Kernel 3.9.4 source code
wget https://raw.github.com/mengning/mykernel/master/>mykernel_for_linux3.9.4sc.patch # download mykernel_for_linux3.9.4sc.patch
xz -d linux-3.9.4.tar.xz
tar -xvf linux-3.9.4.tar
cd linux-3.9.4
patch -p1 < ../mykernel_for_linux3.9.4sc.patch
make allnoconfig
make
qemu -kernel arch/x86/boot/bzImage 从qemu窗口中您可以看到my_start_kernel在执行,同时my_timer_handler时钟中断处理程序周期性执行。
cd mykernel 您可以看到qemu窗口输出的内容的代码mymain.c和myinterrupt.c
make的小插曲
在make的过程中报错,发现缺少compiler-gcc7.h头文件。gcc --version得知当前gcc版本为7.3.0版本。

由于搭建的环境使用的是linux-3.9.4内核版本,故gcc版本没有升级至gcc7的高版本,即该内核文件中没有对gcc7版本进行支持的头文件。
于是从当前系统内核中拷贝一份gcc7的头文件(注意不应该直接拷贝文档,应当将代码拷入新的文件,以解决权限问题),再make即可。
执行上述命令可以看到my_start_kernel和my_timer_handler的内核启动效果。

简单的时间片轮转多道程序
接下来我们使用github中的myinterrupt.c
mymain.c mypcb.h替换mykernel原有的代码,写成一个简单的时间片轮转多道程序内核代码,并重新make,内核启动结果如下

接下来我们依次对三个文件进行简要分析
mypcb.h
#define MAX_TASK_NUM 4
#define KERNEL_STACK_SIZE 1024*2 //定义进程控制块大小,即内核栈为2KB
/* CPU-specific state of this task */
struct Thread {
unsigned long ip;
unsigned long sp;
};
typedef struct PCB{
int pid;
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
unsigned long stack[KERNEL_STACK_SIZE];
/* CPU-specific state of this task */
struct Thread thread;
unsigned long task_entry;
struct PCB *next;
}tPCB;
void my_schedule(void);
其中
- pid表示进程的id
- state表示进程的状态,0为正在运行的进程,-1表示不可运行,大于0则表示进程停止了
- stack表示当前进程的堆栈
- task_entry表示入口
- *next表示链表指针,即使用链表来存储进程模块
- my_schedule此为申明的函数,为调度器
pcb头文件到此。
mymain.c
这里我们仅对关键的内嵌汇编代码进行细致分析。
asm volatile(
"movl %1,%%esp
" /* set task[pid].thread.sp to esp */
"pushl %1
" /* push ebp */
"pushl %0
" /* push task[pid].thread.ip */
"ret
" /* pop task[pid].thread.ip to eip */
:
: "c" (task[pid].thread.ip),"d" (task[pid].thread.sp) /* input c or d mean %ecx/%edx*/
);
以上是启动执行第一个进程的关键汇编代码。
在内嵌式汇编语言中,数字前加%表示的为输入或输出部分,编号按照顺序排列,如上述代码中的%0表示第一个"c" (task[pid].thread.ip)部分,%1表示"d" (task[pid].thread.sp)部分。
- 1.将进程原堆栈栈底的地址,存入ESP中,即将ESP指向进程0的堆栈栈底。
- 2.这里简化了写法,因为此时栈为空栈,所以想要重置栈底指针EBP只需将等同于ESP指针地址的值进行入栈操作即可。至此,ESP与EBP就位,同时指向栈底。
- 3.由于这里只显示了关键内嵌汇编代码部分,此时%0所指向的地址为my_process函数。将%0入栈。
- 4.取走%0,也即my_process函数地址,说明即将执行此函数。

myinterrupt.c
/* switch to next process */
asm volatile(
"pushl %%ebp
" /* save ebp */
"movl %%esp,%0
" /* save esp */
"movl %2,%%esp
" /* restore esp */
"movl $1f,%1
" /* save eip */
"pushl %3
"
"ret
" /* restore eip */
"1: " /* next process start here */
"popl %%ebp
"
: "=m" (prev->thread.sp),"=m" (prev->thread.ip)
: "m" (next->thread.sp),"m" (next->thread.ip)
);
此处是从github上下载的优化之后的代码,删除了if else中的else模块。
上述代码的功能是在两个正在运行的进程之间做进程上下文切换,当然,这里为了简便,我们假设只有两个进程0和1,并假设当前进程为0,我们要切换下一个进程为1。
- 1.首先将当前进程的栈底ebp压栈保存。
- 2.再将当前进程的栈顶esp保存至prev->thread.sp中。
- 3.保存当前进程的ebp和esp值之后,将下一个进程的ip指针寄存器值放入esp中,即告诉内核下一个命令即将跳到另一个进程。
- 4.与3意义一致,将esp和ebp都指向即将运行的进程1。
- 5.将值1f保存至进程0的IP寄存器中,不过话说回来,
movl $1f,%1中的$1f常量让我一头雾水,虽然书中也解释了。本以为是个随意设置的常量,谁知改变其值之后没法make了,于是查阅资料:这是这只是at&t一种语法,局部标号可以用数字,而且可以重复。在以这些标号为目的的转移指令上,标号要带上后缀,b表示向前,f表示向后。 - 6.将进程1的IP寄存器中的值压栈
- 7.取出当前esp所对应的值,即进程1的ip寄存器值,并将其赋给eip,至此,由进程0到进程1的切换完毕

有意思的事
较深入的学习了进程切换之后,发现和c语言中的两值交换很像。其实仔细想来确实如此,对于cpu来说,他永远只能一件事一件事的干,虽然存在中断机制,但依然是无法同时进行两件事(这里说的cpu指的是cpu的一个线程)。在2个值的交换中,为了能够成功交换,我们往往会设置一个中间变量,而在这里也是如此,在myinterrupt.c中我们能看到三次对于进程0的相关值的临时存储:
"pushl %%ebp
" /* save ebp */
"movl %%esp,%0
" /* save esp */
"movl $1f,%1
" /* save eip */
前两者是为了保存内核栈的状态,最后一个则是保存着命令的地址,以方便下一次切换进程的时候能够定位至此。