这是由一次面试开始的第一篇Blog
本次面试方向为Java架构方向,涉及到Java新的应用场景,相当于打开了Java的另一扇大门。由此开始了我的第一篇博客,对相关知识点和内容进行总结和实践。
其中包括如下知识点:
- Java中的hashCode()方法及相关应用
- ==和equal()的细节问题
- jvm虚拟机内存结构
- IO拥塞及5种IO模型
- 数据库分表分库
- Redis缓存数据库
- MyCat中间件
- 快捷目录
Java中的hashCode()方法及相关应用
Java中的Object类为所有类的父类,在Object下面包含了很多基础方法,譬如equals()、getClass()、hashCode()、toString()等。
hashCode()作为基础方法中重要的一员,用于返回对象的hash值,其返回值为int类型。
但是仅仅返回对象的hash值有什么意义吗?要想真正理解hashCode()方法的作用,必须要从hash散列和Java集合说起。
-
hash散列:把任意长度的输入,通过散列算法变换成固定长度的输出,该输出就是散列值。通过散列计算地址来存储数据,再使用hash散列函数访问数据,能使对一个数据序列的访问过程更加迅速有效,数据元素将被更快地定位。hash算法会尽量选择更好的方案来减少碰撞,但在某些情况下,hash散列也会得出相同的值,此时便需要根据实际需要进行冲突的解决,因此,相同的hash值并不意味着目标对象是相同的。
-
Java集合:在Java中,HashMap是使用非常多的集合,它是基于哈希表的 Map 接口的实现,以key-value的形式存在,而HashSet仅存储对象,同时HashSet中不允许有重复的元素。当向一个Set集合中添加元素时,先调用这个元素的hashCode()方法,就能直接确定该元素的物理地址,当这个位置上没有元素,它就可以直接存储在这个位置上,不用再进行任何比较;但是如果这个位置上已经有元素,就需要调用它的equals()方法与新元素进行比较,相同的话就不再存储,不相同就散列其它的地址。可以发现,在以上过程中涉及到equals()方法和hashCode()方法性能上的差距,Set集合在添加元素时,并没有直接通过equals()方法全权负责,而是先由hashCode()方法进行判断,再根据结果选择性调用equlas()方法。相关源代码如下:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}public boolean add(E e) {
return map.put(e, PRESENT)==null;
}由此,可以总结如下:
- 相同的对象具有相同的hash值
- equals()相等的对象一定具有相同的hash值
- hashCode()相同的对象不一定equals()相等
- 在比较场景下,hashCode()方法性能较equals()方法性能较好(一个用值来比较,一个用对象来比较)
- hashCode()与equals()的重写问题:若重写了equals()方法,则有必要重写hashCode()方法(此处可以深入探讨)
==和equal()的细节问题
equals()是java.lang.Object类的方法,要想说明==和equals()的区别,还要从代码开始:
String str1, str2, str3 = "abc", str4 = "abc";
str1 = new String("abc");
str2 = new String("abc");
StringBuffer strb1 = new StringBuffer("abc");
StringBuffer strb2 = new StringBuffer("abc");
System.out.println(str1==str2);
System.out.println(str1.equals(str2));
System.out.println(str3==str4);
System.out.println(str3.equals(str4));
System.out.println(strb1==strb2);
System.out.println(strb1.equals(strb2));控制台打印结果如下:
false
true
true
true
false
false可是为什么会造成这样的结果呢,这就设计到==和equals()的一些细节问题。
经过查阅资料和源代码得知,==和equals()在比较上存在以下区别:
- “==”比较两个字符串变量本身的值,即两个对象在内存中的首地址
- equals()比较字符串中所包含的内容是否相同,因为在String类中重写了equals()方法,比较的是字符串的内容而不是其地址,涉及到的源代码如下:
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}- StringBuffer类中没有重新定义equals这个方法,因此这个方法就来自Object类,而Object类中的equals方法是用来比较地址的,所以等于false
- 对于str3和str4是由字符串生成的变量,因此所存放的内存地址是相同的
下面再来测试一段代码:
int i1 = 1, i2 = 2, i3 = 1;
System.out.println(i1==i2);
System.out.println(i1==i3);控制台输出结果如下:
false
true由以上结论,可知==比较的是对象在内存中的首地址。这样以来可以说明jvm编译机制:int类型常量会根据大小区分指令,0~5一段,-128~127一段,-32768-32767一段,其余会作为常量放入常量池。其常量池的地址是相同的。
接下来再尝试下Integer类的情况:
Integer ig1 = new Integer(123);
Integer ig2 = new Integer(123);
Integer ig3 = new Integer(321);
int i4 = ig3;
System.out.println(ig1==ig2);
System.out.println(ig1==ig3);
System.out.println(ig1.equals(ig2));
System.out.println(ig1.equals(ig3));
System.out.println(ig3==i4);
System.out.println(ig3.equals(i4));控制台输出显示如下:
false
false
true
false
true
true可以发现,在Integer的实例下,==是比较地址的,而equals()是比较内容的。仔细查看源代码:
public boolean equals(Object obj) {
if (obj instanceof Integer) {
return value == ((Integer)obj).intValue();
}
return false;
}可见,Integer类重写了equals()方法,并且自动拆箱是调用Integer.valueOf()方法。
jvm虚拟机内存结构
由第二部分可知java代码在编译过程中涉及到内存机制问题,在这里简单设计下jvm虚拟机的内存结构。
借用下《深入理解Java虚拟机(第二版)》中的描述:
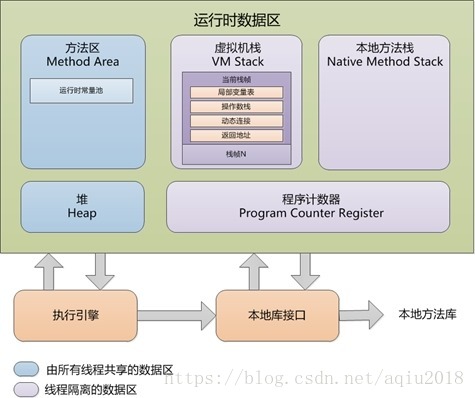
这里暂时作为参考和总结,具体细节比较复杂,在之后再做深入讨论。
IO拥塞及5种IO模型
I/O:Input/Output 输入/输出
大致可分为内存IO、网络IO、磁盘IO
5种IO模型分别是阻塞IO模型、非阻塞IO模型、IO复用模型、信号驱动的IO模型、异步IO模型;前4种为同步IO操作,只有异步IO模型是异步IO操作。
此处参考大牛博客,对于消息同步异步以及IO模型进行了清晰和详细的阐述:
数据库分表分库
数据库分表分库思想,其英文名为Sharding,意为“分片”。
此处参考大牛博客,其全面的总结和中间件的汇总,让人十分受益:
Redis缓存数据库
Redis 是一个高性能的key-value数据库。
Redis 与其他 key - value 缓存产品有以下三个特点:
Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用
Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储
Redis支持数据的备份,即master-slave模式的数据备份
Redis与其他key-value存储有什么不同?
Redis有着更为复杂的数据结构并且提供对他们的原子性操作,这是一个不同于其他数据库的进化路径。Redis的数据类型都是基于基本数据结构的同时对程序员透明,无需进行额外的抽象
Redis运行在内存中但是可以持久化到磁盘,所以在对不同数据集进行高速读写时需要权衡内存,因为数据量不能大于硬件内存。在内存数据库方面的另一个优点是,相比在磁盘上相同的复杂的数据结构,在内存中操作起来非常简单,这样Redis可以做很多内部复杂性很强的事情。同时,在磁盘格式方面他们是紧凑的以追加的方式产生的,因为他们并不需要进行随机访问
MyCat中间件
正如百度百科定义,MyCat是代替昂贵的oracle的MySQL集群中间件。
Mycat的原理并不复杂,复杂的是代码,如果代码也不复杂,那么早就成为一个传说了
Mycat的原理中最重要的一个动词是“拦截”,它拦截了用户发送过来的SQL语句,首先对SQL语句做了一些特定的分析:如分片分析、路由分析、读写分离分析、缓存分析等,然后将此SQL发往后端的真实数据库,并将返回的结果做适当的处理,最终再返回给用户
参考相关博客:
其中内容有详有略,有些部分还需要不断地学习,先做引用之后会不断深入。记第一篇博客,加油!