一、explain
explain select * from t_order

执行后会打印type:all
type有 all(全表扫描) index(索引全扫描) range(索引范围扫描) ref(非唯一索引扫描或唯一索引的前缀扫描) eq_ref(唯一索引扫描) const,system(主键或唯一索引unique index查询) null(mysql不用访问表就能得到结果 select 1 from dual where 1)
从左往后 性能由最差到最好;下面以索引失效的场景为例分析索引命中
1、创建普通索引CREATE INDEX idx_userid ON t_order(user_id);
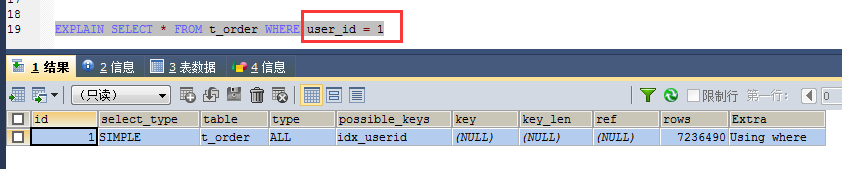

由于user_id是varchar类型,所以当user_id作为搜索条件时,需要带上双引号,不带的话会导致索引失效
2、通配符Like查询%最左侧导致索引失效


3、使用!=、>、<导致索引失效


4、对于组合索引,OR查询将会失效;删除之前创建的索引,添加个组合索引CREATE INDEX idx_u_p ON t_order(user_id,pay_mode); 其中pay_mode是tinyint类型

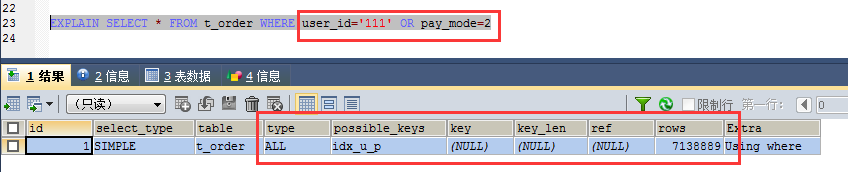
使用OR之后索引变失效了,要想同时用OR查询和索引失效,需要单独创建user_id和pay_mode索引
5、对于组合索引,不是使用的第一部分则不会使用索引(需参考场景4中创建索引的语句,user_id在pay_mode之前)
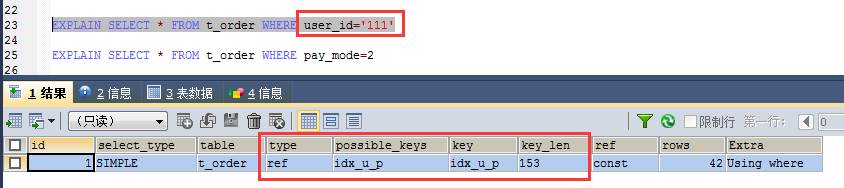
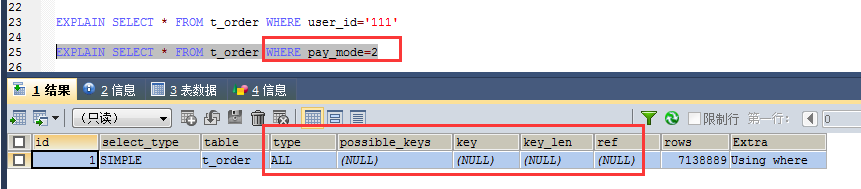
由图可知,user_id触发了索引,但是pay_mode没有触发索引
二、profile
1.查看profile和开启
2.通过profile查看不同存储引擎执行sql的差别以及每个线程消耗的时间,假设查询的id=7
set @query_id :=7;
select state,sum(duration) as Total_R, ROUND( 100 * SUM(duration) / (select sum(duration) from INFORMATION__SCHEMA.PROFILING WHERE QUERY_ID = @query_id ),2) as Pct_R, count(*) as Calls, sum(DURATION) / COUNT(*) as "r/Call" FROM INFORMATION_SCHEMA.PROFILING where query_id = @query_id group by state order by Total_R desc;
InnoDB存储引擎下存在Sending data,有访问数据的过程
MyIsam下在executing之后直接结束查询,完全不需要访问数据
三、通过trace分析优化器如何选择执行计划
1.开启trace 设置格式为JSON
2.设置trace最大能够使用的内存大小,避免解析过程中因为默认内存过小而不能够完整显示
3.执行sql语句 查看mysql是如何执行sql
四、索引问题
1.索引的存储分类,索引是在存储引擎层中实现的
①B-Tree索引:最常见的索引类型,大部分引擎都支持B树索引
②HASH索引:只有memory引擎支持,使用场景简单
③R-Tree索引(空间索引):是MyISAM的一个特殊索引类型,主要用于地理空间数据类型,使用较少
④Full-text(全文索引):是MyISAM的一个特殊索引类型,主要用于全文索引,InnoDB从MYSQL5.6开始提供对全文索引的支持
2.索引的典型场景 索引m(列a,列b,列c)
①匹配全值 a=1 and b=1 and c=1 用到了索引m 类型为const
②匹配值的范围查询 c>=1 and c<100 没有用到索引m 类型为range
③匹配最左前缀 b=1 and c=1 不会用到索引m;a=1 and c=1 会用到索引m
④仅仅对索引进行查询(Index only query),当查询的列都在索引的字段中时,查询的效率更高 select a from table where a=1 类型为ref
⑤匹配列前缀 仅仅使用索引中的第一列,并且只包含索引第一列的开头一部分进行查找
create index idx_title_desc_part on filem_text(title(10),description(20))
select title from film_text where title like 'AFRICAN% '
3.存在索引但不能使用索引的典型场景
①以%开头的like查询不能使用B-Tree索引
五、数据备份
mysqldump -uroot -p -l -F sakila(库名) > /usr/local/mysql/backup/sakila-20170730.sql(备份后的文件地址)