#《语义网与知识图谱》期末复习(二)
之前总结的链接:
考试题型
选择题(1*15)-单选、多选随机混合
填空题(1*20)-据说不好填
判断题(1*10)
简答、问答:
- 写SPARQL语句和结果(书上),根据RDF图写
- 根据属性图写SPQRQL查询语句
- 根据句子描述写描述逻辑
- 画三元组的图
- 根据句子写OWL的XML格式片段
- 图里面去补充节点信息
基本
- 语义web的组成:语义web信息的开放标准、从web描述信息中进一步获取语义的方法。
- 本体:本体是一种形式化的,对共享概念体系的明确而又详细的说明。提供一种共享词表。核心是分类体系。
- RDF使用有向图作为数据类型。
- 语义网和语义网络的区别:语义网是未来发展的趋势,是web3.0的特征;而语义网络是一种知识表示方法,仅仅是一个方法。
- 知识图谱:学术角度上讲,知识图谱本质上是一种揭示实体之间关系的语义网络,可以对现实世界的事物及其相互关系进行形式化地描述。
- 知识图谱的技术流程:知识表示、知识获取、知识融合、知识推理、知识检索、知识分析
- Datalog的基本语法包含:原子、规则、事实。
- 知识图谱的存储:关系型数据库、三元组库、图数据库
- 知识图谱的应用:推荐系统、知识问答等
- 逻辑语义包含:模型论和证明论
- 知识谱图的表示:符号表示、向量表示。
- 描述逻辑的基本概念:个体、类、属性。
RDF-Literals
即文本或者说是字符串,在rdf图种用方框表示。
RDF表示
一个三元组包含
- 主语:URIs和空节点
- 谓语:URIs(通常被成为属性)
- 宾语:URIs、空节点或者文字
Turtle
Turtle需要注意:
- URIs放在<>中
- 文字用双引号
- 三元组用.结束
- 忽略空格
- @prefix描述前缀。eg. @prefix ex: <http://xx.com>.
- 三元组的主语一样可以简化缩写。
XML-based RDF
<rdf:description rdf:about="xx">
</rdf:description>
利用rdf:description表示是一个节点,rdf:about表述节点名或者说是URI
通过xml 的包含结构来描述主谓关系。
literal有两种写法
- 直接写
- 省略写法.eg: <ex:name="aoru">等价于<ex:name>aoru</ex:name>
空节点在xml中有下列的写法:
- 指定rdf:nodeId,然后再下面引用
- 缩写,利用rdf:parseType = "Resource"表示空节点
空节点再turtle中对应为:
- _ 用下划线表示空节点前缀
- 或者下面缩写,[]用方括号表示空节点,在方括号中写谓语和宾语。
RDFS
在类和实例上对RDF拓展。
A rdf:type B 表示A是B的实例。
隐式推理:
- a type A, A subclassOf B,则a type B
- A subclassOf B,B subClassOf C,则A subClassOf C。
- A subclassOf B,B subClassOf A,则A、B等价。
属性约束:
rdfs:domain定义域
rdfs:range值域
语义
主要考虑语义概念的逻辑维度。
逻辑语义包括:模型论和证明论。
OWL
基本元素:
Class、rdfs:subClassOf
所有的类都继承自owl:Thing
定义一个类
<owl:Class rdf:ID="A">
</owl:Class>
定义一个实例化个体
<A rdf:ID="a">
</A>
属性:
<owl:ObjectProperty rdf:ID="makeFrom">
<rdf:range rdf:resource="a"></rdf:range>
<rdf:domain rdf:resource="b"></rdf:domain>
</owl:ObjectProperty>
本体映射:
<owl:Class rdf:ID="a">
<owl:intersectionOf rdf:parseType="Collection">
<rdf:Class rdf:ID="b"></rdf:Class>
<rdf:Class rdf:ID="c"></rdf:Class>
</owl:intersectionOf>
</owl:Class>
owl:intersectionOf 交运算
owl:unionOf 并运算
owl:disjointOf 不相交类
描述逻辑
描述逻辑的基本概念包含:个体(URIs)、类(URIs)、属性(URIs)。
描述逻辑的体系结构包括:表示概念和关系的构造集、Tbox术语集、Abox断言集、Tbox和Abox上的推理机制。
Abox:上面那种is关系,类与对象的关系属于Abox。
Tbox:上面那种类与类之间的关系。比如包含关系。
如何利用DL构造一个类.
ALC的构造算子:合取、析取、非、存在量词、全称量词。
一个ALC的例子:
Happy Father概念
下面是存在量词和全程量词的符号解释:
 那么根据这个解释,我们可以对上面HappyFather这么理解:
HappyFather首先是一个Man,然后第二个条件怎么理解呢?存在一个个体满足hasChild的关系,且在hasChild的值域中,并且这个个体是Male的子集,那么满足这样关系的hasChild的定义域集合就是结果。同样地,hasChild.Famale也可以这么理解。最后一行,理解为,任意一个个体满足hasChild的关系,这个个体在hasChild的值域中,并且这个个体是医生或者律师的集合中的元素,那么这样的关系对(hasChild)中的定义域即为结果。
那么根据这个解释,我们可以对上面HappyFather这么理解:
HappyFather首先是一个Man,然后第二个条件怎么理解呢?存在一个个体满足hasChild的关系,且在hasChild的值域中,并且这个个体是Male的子集,那么满足这样关系的hasChild的定义域集合就是结果。同样地,hasChild.Famale也可以这么理解。最后一行,理解为,任意一个个体满足hasChild的关系,这个个体在hasChild的值域中,并且这个个体是医生或者律师的集合中的元素,那么这样的关系对(hasChild)中的定义域即为结果。
注意这里HappyFather也是个类,所以不能用个体来描述。 用自然语言描述为:快乐的父亲等价于 (他们是男人) 并且 (他们有至少一个孩子,这个孩子是男的,就是他们有儿子的意思) 并且 (他们有至少一个孩子,这个孩子是女的,就是他们有女儿的意思) 并且 (他们所有的孩子都要么是医生要么是律师)
SROIQ
原文:
The extension of ALC with transitive roles is traditionally denoted by the letter S. Some other letters used in DL names hint at a particular constructor, such as inverse roles I, nominals O, qualified number restrictions Q.The letter R most commonly refers to the presence of role inclusions, local reflexivity Self
S:传递关系
R:自反关系
I:可逆关系
O:集合关系封闭
Q:表示集合有基数限制
可判定性:如果一个问题的结果最终能够收敛到一个稳定的值,不管能不能直接得到解,都称这个问题是可判定的。
半判定:算法在有限时间能解决的问题是半判定问题。
存在同时是半判定和非判定的问题。
一种描述逻辑如果其”蕴含公理“是可判定的,则这种描述逻辑是可判定的。
大多数的描述逻辑是可判定的,可判定行是判断一种”好的“描述逻辑标准。
什么是知识图谱
学术角度上讲,知识图谱本质上是一种揭示实体之间关系的语义网络,可以对现实世界的事物及其相互关系进行形式化地描述。
知识图谱的”图谱“不是图像而是图模型。
知识图谱不仅关心知识如何用图表达,还关注图谱如何获取、融合、更新和推理等问题。
知识图谱的技术流程
数据->知识表示->知识获取->知识融合->知识推理->知识检索->知识分析->应用
知识图谱与数据库
- RDF三元组库,使用SPARQL查询
- 图数据库,使用Cypher(开源图数据库Neo4j)、Gremlin、PGOL和G-Core
知识图谱与推荐系统
推荐系统的问题:冷启动,最开始没得数据推荐。
使用知识图谱解决:知识图谱可以提供先验知识,帮助缓解数据稀疏问题,提高模型性能。
推荐系统:
- 基于协同过滤
- 基于内容
引入知识图谱:
- 基于知识图谱中元路径的推荐模型
- 基于概率逻辑程序的推荐模型
- 基于知识图谱表示学习技术的推荐模型
知识图谱小结
知识图谱的终极目标:将非结构、无显式关联的粗糙数据逐步提炼为结构化、高度关联的高质量知识。
知识图谱涉及:知识表示、关系抽取、图数据存储、数据融合、推理补全、语义搜索、知识问答、自动推理、知识驱动等。
关系型数据库:不强调语义逻辑、数据量大、实用
传统知识库:以逻辑为基础,强调语义、数据量小、不实用
知识图谱:弱语义,弱逻辑、大量实例、实用
知识表示
知识表示:用易于计算机处理的方式来描述人脑的知识。
数据与知识的区别:知识可以推理。
知识图谱是知识表示的一种方法。
霍恩子句、霍恩逻辑
霍恩子句:文字的析取,最多有一个肯定文字。也就是说,霍恩子句中最多只能存在一个肯定的句子,其他皆为否定。
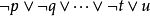
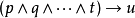
如上图所示,据说这样的表示能够在计算机上非常高效。
框架系统
框架系统的基本思想:认为人们对现实世界中事物的认识都是以一种类似于框架的结构存储在记忆中。当面临新事物的时候,就从记忆中找出一个合适的框架,并根据实际情况对细节加以修改、补充,从而形成对当前事物的认识。
框架:是一种描述对象的属性的数据结构。
一个框架系统由若干个槽组成。每个槽又分为若干侧面/
槽:描述对象某一方面的属性。
侧面:描述属性的一个方面。
SPARQL
是rdf数据库的查询语言。
用三元组形式查询。
例子:
prefix exp: <http://aa.com>
SELECT ?student ?email
WHERE {
?student exp:studies exp:English.
OPTIONAL {
?student foaf:mbox ?email.
FILTER(?age >5).
}
}
- 变量前面要加?
- OPTIONAL是带选项的查询,表示里面的选项是查询可选的。
- FILTER是过滤算子,如果OPTIONAL满足,则就要过滤掉age大于5的结果。
| 语法 | 含义 |
|---|---|
| PREFIX | 地址前缀,跟turtle里一样 |
| OPTIONAL | 可选过滤的条件 |
| FILTER(REGEX(?name,"jack")) | 对结果过滤 |
| UNION | 两个结果的并集 |
| ORDER BY | 结果排序规则 |
| LIMIT 10 | 限制结果数量 |
| OFFSET 10 | 略过前十条 |
例子:
prefix exp: <http://example.com>
SELECT ?a ?b
WHERE{
{
{?a exp:has ?b.} UNION {FILTER(?b > 50).}
}
OPTIONAL {
?a exp:is ?b.
}
} LIMIT 10 OFFSET 5
知识图谱嵌入
嵌入就是映射到高维的向量空间,知识谱图的嵌入一般可以通过深度学习等方法把系欸但转化为向量,然后映射到高维空间处理。
知识图谱中可以用类比推理做知识图谱的补全。
知识图谱的存储
专门存储RDF数据的三元组库、图数据库、传统关系型数据库
Cypher
图数据库的查询语言,neo4j中使用的查询语言就是Cypher。
Cypher是一种声明式查询语言,一个简单的查询例子为:
MATCH (P:程序员)
return p
TableAux
基本思想:通过一系列规则构建Abox,检测可满足性,或者检测某一实体是否存在于某概念。
后记
考完了,选择填空其实不是最难的我感觉,选择题第一个是问语义网的创始人是谁,一脸懵逼。填空题基本上告诉你一个概念的解释让你说出这个概念的名字,然后SPARQL查询语句的题特别多,但分值不是很高,然后是画图的送分题(我好像画错了),就是平时作业的唯一一道画图题,然后我感觉那描述逻辑的题挺难的,就是给你写一句话,让你用SROIQ语句表示出来,比如说,A和B至少同时参加了一个小组类似的这样的。这部分上课听不太懂,如果有同学选了这个课要考的话最好还是查一些英文原版资料尽量写一些配套的题,不然这里会坑(我也不知道自己写没写对,没得底),然后最后一题好像是平时作业里的送分题。难点主要在SROIQ语句,基础点主要在SPQRQL查询语句。后记完。