SSD:Single Shot MultiBox Detector
Intro
SSD是一套one-stage算法实现目标检测的框架,速度很快,在当时速度超过了yolo,精度也可以达到two-stage的精度,可以与faster rcnn媲美,这套算法里用到了与faster rcnn的anchor相似的概念-default box,也解决了多尺度问题对one-stage的影响-对不同大小的feature map进行滑窗分类,使得不同尺度的feature map的分类器对原图目标尺度更加敏感。
one-stage和two-stage的算法区别主要在于,two-stage算法在区域提取的时候做分类是前景和背景,只有两个分类,然后再拿去给第二个专门用来分类的网络去学习分类具体类别;而one-stage算法直接在区域提取的时候给分类结果(这其中其实还设计到训练的时候default boxes 的label与ground truth label匹配的问题),我认为这是最大的不同。
Model
模型的结果其实很容易理解,就是在vgg16后面开始一边对每个feature map直接做分类,一边继续压缩feature map的size,然后继续做分类,以此类推。最后把所有的detection结果做nms。
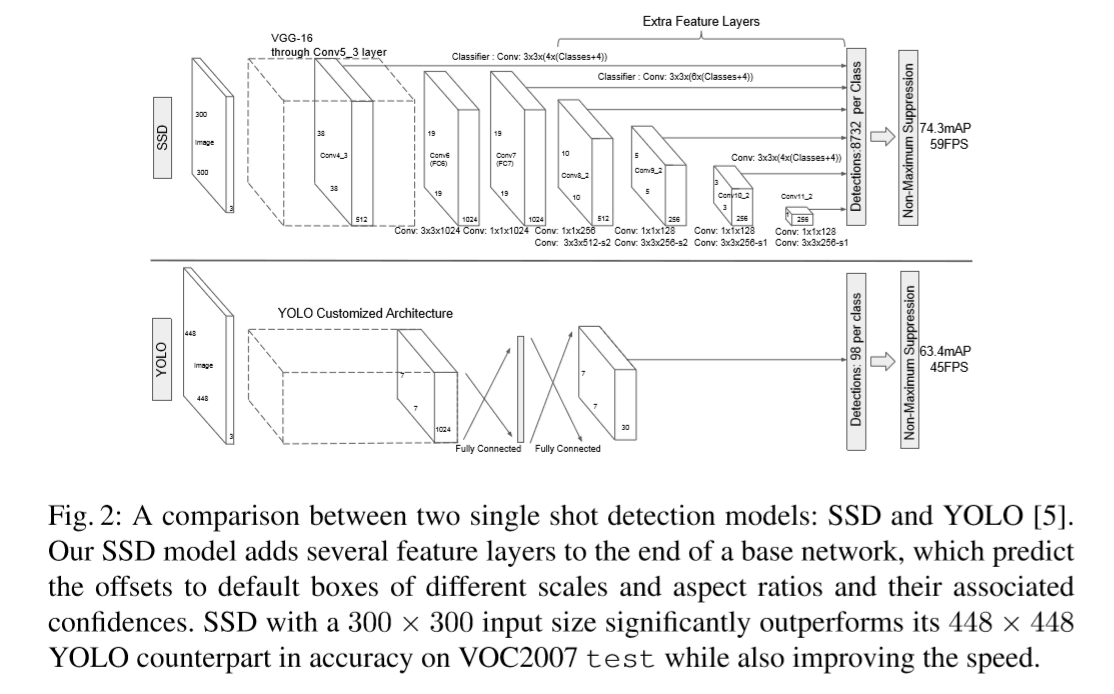
文章先介绍了SSD作为多尺度检测器是通过对feature map的不同尺度进行的,而怎么做这个检测呢?利用类似于anchor的方法,在不同尺度的feature map上用3*3卷积核滑窗,这样每个卷积核作用得到一个结果,而对每个feature map cell,作者又安排了一组对应的default boxes,这些default boxes在size上有所不同,比例是预先设计好的。每个cell安排(c+4)*k个卷积核,c表示类别,4表示offset,k表示default boxes种类,这样,对每个default box而言,有不同的卷积核负责算类别概率、与bounding box的偏移值。因此,对于一个m*n的feature map而言,输出的结果有m*n*k*(c+4)个。作者也说了,他们设计的default boxes其实是类似于anchor boxes的,这点毋庸置疑。
Training
之前说过,训练很重要的一点是label的对应,因此作者在这里首先讲了匹配的策略。先从每个default box开始,把每个default box匹配一个与之重叠度最高的ground truth,这里重叠度用的jaccard算法,其实跟iou是一样的,交集比上并集,然后还没完,又从ground truth出发,让每个ground truth能够对应与之jaccard重叠度大于0.5的default boxes,然后把小于0.5的去除。这样减少了训练的数量,大大简化了训练。举个例子,一套简单题,一个同学在班上分数最高,他肯定就是这个班最强的人了,但是他只有五十分,你说选他还是不选他,菜鸡!当然不选了。
上面建立了从default box到ground truth box在空间上的映射,然后提出loss:

这里又通过p将空间映射在类别上细分。我们知道每个default box的预测有(c+4)个值,所以对于l,只需要说明是第几个参与训练的default box和第m个位置预测,m当然是在那4个中选,至于你安排哪几个预测位置,完全看你自己。两者经过smooth L1函数运算完,再看看类别对应上没有,显然对应上了这个值就应该是1,以此来最小化loss。分类的loss是所有正例分类概率的-log乘上匹配值,显然匹配上了是1,如果每匹配上,就是所有正例概率-log之和,加上负样本预测背景的概率-log,就是全预测0就是背景,即对0的预测概率,显然概率越高loss越小。
然后是hard negative mining,在经过matching之后,其实大多数default box是负样本,这就导致了正负样本极度不均衡,然后就把一些负样本变正呗,把iou高的变正,保证正负样本比例位1:3.
最后是数据增强,增强选项包括:
- 直接用原图
- sample a patch(实在不知道咋翻译但是会意就好了)使得iou是0.1 0.3 0.5 0.7 或者0.9
- 随机sample a patch(不用保证是上面的0.1 0.3 0.5 0.7 0.9)