第二章 数据模型与查询语言
大多数应用程序是通过一层层叠加数据模型来构建的,每层都通关提供一个简洁的数据模型来隐藏下层的复杂性,这些抽象机制使得不同人群可以高效协作。不同的数据模型都有其最佳使用的若干假设,考虑到数据模型对其上的软件应用有着巨大影响,因此需要慎重选择合适的数据模型。
关系模型与文档模型
当前在网上看到的大部分内容很多仍然是由关系数据库所支撑的。
NoSQL的诞生
NoSQL含义已被重新解释为“不仅仅是SQL”
采用NoSQL数据库有这样几个驱动因素:
- 比关系数据库更好的扩展性需求,包括支持超大数据集或超高写入吞吐量。
- 普遍偏爱免费和开源软件而不是商业数据库产品、
- 关系模型不能很好地支持一些特定的查询操作。
- 对关系模式一些限制性感到沮丧,渴望更具动态和表达力的数据模型
关系数据库可能仍将继续与各种非关系数据库存储一起使用,这种思路有时也被称为混合持久化。
对象-关系不匹配
如果数据存储在关系表中,那么应用层代码中的对象与表、行和列的数据库模型之间需要一个笨拙的转换层。模型之间的脱离有时被称为阻抗失谐。
例如在简历中,每个人作为简历表中的一行,但是大多数人在他们的职业中有一个以上的工作,并且可能有多个教育阶段和任意数量的联系信息,用户有这些项目之间存在一对多的关系:
- 传统的SQL模型中是将职业、教育和联系信息放在单独的表中,并使用外键引用。
- 之后的SQL标准增加了对结构化数据类型和XML数据的支持,允许将多值数据存储在单行内,并支持在这些文档中查询和索引。
- 第三个选项是将工作、教育和联系信息编码为JSON或XML文档,将其存储在数据库的文本列中,并由应用程序解释其结构和内容
多对一与多对多的关系
文档模型并不适合表达多对一的关系(许多人生活在同一地区,许多人在同一行业工作)
- 每条记录都要保存一次这样的可读信息。
- 如果信息被改变,则每条副本都需要更新
- 会使数据存在不一致的风险,比如有些副本被更新而其他的未更新。
文档数据库是否在重演历史
层次模型与文档数据库使用的JSON模型有一些显著的相似之处,可以很好地一对多关系,但是它支持多对多关系则有些困难,且不支持联结。
网络模型
在网络模型中,一个记录可能有多个父节点。它们使查询数据变得异常复杂而没有灵活性。
关系模型
在关系数据库中,查询优化器自动决定查询的哪些部分以哪个顺序执行,以及使用哪些索引。
关系数据库的查询优化器是复杂的,已耗费了多年的研究和开发精力 。
与文档数据库对比
文档数据库可以被还原为层次模型。
在表示多对一和多对多的关系时,关系数据库和文档数据库并没有根本的不同 。
关系型数据库与文档数据库在今日的对比
支持文档数据模型的主要论据是架构灵活性,因局部性而拥有更好的性能,以及对于某些应用程序而言更接近于应用程序使用的数据结构。关系模型通过为连接提供更好的支持以及支持多对一和多对多的关系来反击。
哪个数据模型更方便些代码
- 如果应用程序中的数据有类似文档的结构,则使用文档模型更好,关系模型要将文档结构分解成多个表使得代码更加复杂。
- 文档模型不能引用文档中的嵌套项目,而是要根据从外到内的路径访问。
- 文档数据库对连接支持糟糕,但这是不是缺点取决于应用程序,如果应用程序永远不需要多对多的关系,那这就不算缺点。
- 如果应用程序确实需要多对多关系,可以向数据块发送多个请求,在应用程序代码中模拟连接,但这通常比数据库内专用的代码执行连接慢而且增加了应用程序的复杂度,这种情况下不适合文档模型
- 很难说在一般情况下哪个数据模型让应用程序代码更简单;它取决于数据项之间存在的关系种类。对于高度相联的数据,选用文档模型是糟糕的,选用关系模型是可接受的,而选用图形模型(参见“图数据模型”)是最自然的。
文档模型中的架构灵活性
文档数据库被称为无模式,也叫读时模式 (数据的结构是隐含的,只有在数据被读取时才被解释)
相应的关系数据库被称为 写时模式(传统的关系数据库方法中,模式明确,且数据库确保所有的数据都符合其模式)
当数据的模式需要变更时,文档数据库只需要标注变更的时间节点即可,查询时根据时间来判断是使用新模式还是旧模式,而关系数据库需要进行迁移操作。MySQL需要复制整个表,并且在这过程中会需要停运。
因此在下列情况下, 模式的坏处远大于它的帮助,无模式文档可能是一个更加自然的数据模型:
- 存在许多不同类型的对象,将每种类型的对象放在自己的表中是不现实的。
- 数据的结构由外部系统决定。你无法控制外部系统且它随时可能变化。
查询单数据的局部性
文档通常以连续字符串的形式进行存储,如果程序需要访问整个文档,那么存储局部性会带来性能优势。 而如果将数据分割到多个表中,则需要进行多次索引查找,需要更多的磁盘查找并花费更多的时间。
如果只需要文档的一小部分,但数据库通常需要加载整个文档,这对于大型文档来说是很浪费的。
更新文档时,通常需要整个文档重写,而且只有不改变文档大小的修改才可以 容易地原地执行。
因此,通常建议保持相对小的文档,并避免增加文档大小的写入。这些性能限制大大减少了文档数据库的实用场景。
文档和关系数据库的融合
目前越来越多的关系数据库开始支持XML和JSON,而文档数据库也开始支持连接。 关系数据库和文档数据库变得越来越相似 。
数据查询语言
命令式语言告诉计算机以特定顺序执行某些操作。
在声明式查询语言(如SQL或关系代数)中,你只需指定所需数据的模式 - 结果必须符合哪些条件,以及如何将数据转换(例如,排序,分组和集合) - 但不是如何实现这一目标。数据库系统的查询优化器决定使用哪些索引和哪些连接方法,以及以何种顺序执行查询的各个部分。
声明式查询语言的优点:
- 通常比命令式API更加简洁和容易
- 在查询时移动数据会导致命令查询出现问题
- 隐藏了数据库引擎的实现细节,这使得数据库系统可以在无需对查询做任何更改的情况下进行性能提升。
- 更适合并行执行,在多个内核和多个机器时,命令代码必须以特定顺序执行,而声明式语言仅仅指定结果,而不指定算法,数据库可以自由使用查询语言的并行实现
web上的声明式查询
声明式查询语句css使用选择器,为被选中的元素设定相关样式。
而如果使用命令式语句JavaScript来实现这个功能,则需要遍历所有元素,找到有这个属性的元素来更改样式,还要取消原来有这个属性的元素的样式。使用JavaScript代码实现复杂且不易修改、
MapReduce查询
MapReduce既不是一个声明式的查询语言,也不是一个完全命令式的查询API,而是处于两者之间。
图数据模型
一个图由两种对象组成:顶点(vertices)(也称为节点(nodes) 或实体(entities)),和边(edges)( 也称为关系(relationships)或弧 (arcs) )
图提供了一种一致的方式,用来在单个数据存储中存储完全不同类型的对象 。
属性图
在属性图模型中,每个顶点(vertex)包括:
- 唯一的标识符
- 一组 出边(outgoing edges)
- 一组 入边(ingoing edges)
- 一组属性(键值对)
每条 边(edge) 包括:
- 唯一标识符
- 边的起点/尾部顶点(tail vertex)
- 边的终点/头部顶点(head vertex)
- 描述两个顶点之间关系类型的标签
- 一组属性(键值对)
Cypher查询语言
Cypher是属性图的声明式查询语言。
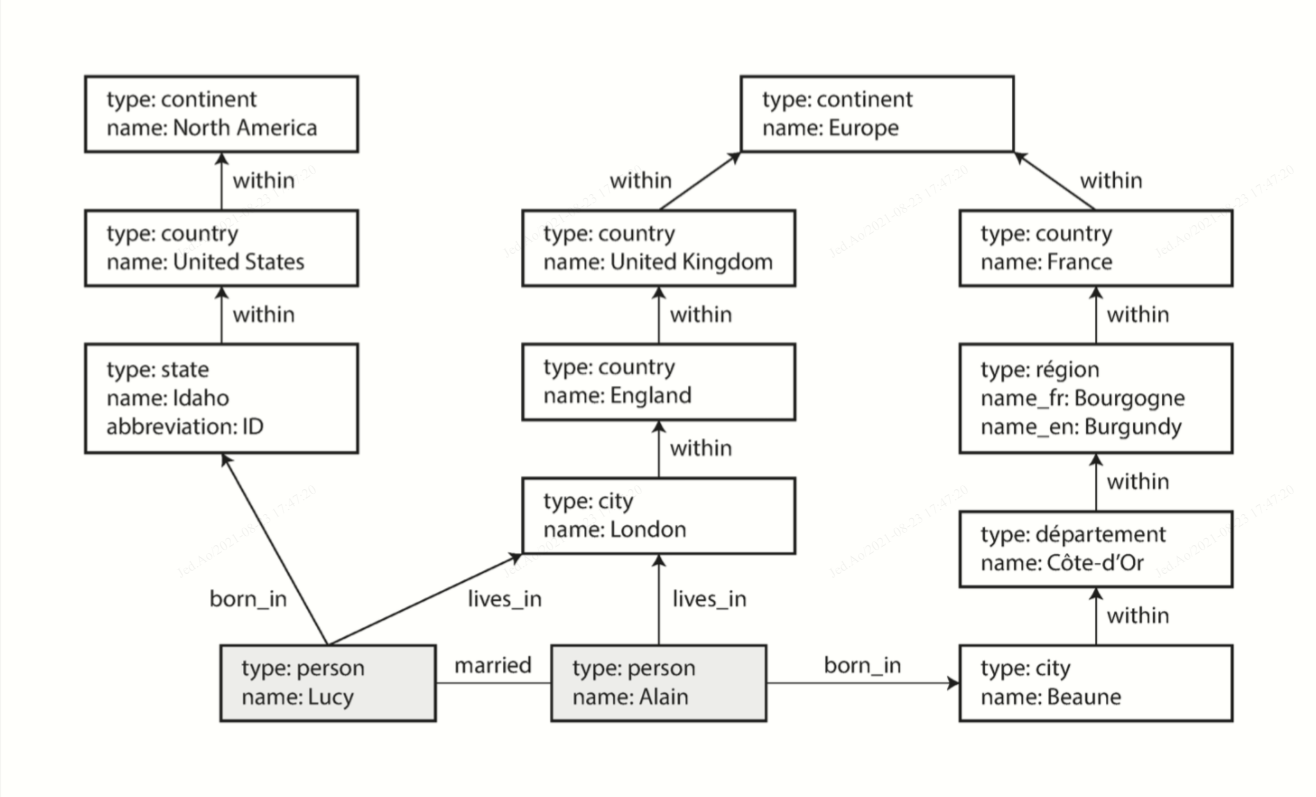
图形数据库的Cypher查询例子:查找所有从美国移民到欧洲的人
MATCH
(person) -[:BORN_IN]-> () -[:WITHIN*0..]-> (us:Location {name:'United States'}),
(person) -[:LIVES_IN]-> () -[:WITHIN*0..]-> (eu:Location {name:'Europe'})
RETURN person.name这条查询可以是扫描数据库中的所有人,检查每个人的出生地和居住地,然后只返回符合条件的那些人。
也可以从两个Location顶点开始反向地查找,查找出那些可以由BORN_IN或LIVES_IN入边到那些位置顶点的人。
通常对于声明式查询语言来说,在编写查询语句时,不需要指定执行细节:查询优化程序会自动选择预测效率最高的策略,因此你可以继续编写应用程序的其他部分。
SQL中的图查询
查询可变长度遍历路径的思想可以使用称为递归公用表表达式(WITH RECURSIVE语法)的东西来表示。在SQL使用这种技术(PostgreSQL,IBM DB2,Oracle和SQL Server均支持)来表述。但是,与Cypher相比,其语法非常笨拙。
不同的数据模型是为不同的应用场景而设计的。选择适合应用程序的数据模型非常重要。
三元组存储和SPARQL
三元组存储模式大体上与属性图模型相同,用不同的词来描述相同的想法。不过仍然值得讨论,因为三元组存储有很多现成的工具和语言,这些工具和语言对于构建应用程序的工具箱可能是宝贵的补充。
在三元组存储中,所有信息都以非常简单的三部分表示形式存储(主语,谓语,宾语)。例如,三元组 (吉姆, 喜欢 ,香蕉) 中,吉姆 是主语,喜欢 是谓语(动词),香蕉 是对象。
当谓语表示边时,该宾语是一个顶点,如_:idaho :within _:usa.。当谓语是一个属性时,该宾语是一个字符串,如_:usa :name "United States"
语义网络
从本质上讲语义网是一个简单且合理的想法:网站已经将信息发布为文字和图片供人类阅读,为什么不将信息作为机器可读的数据也发布给计算机呢?资源描述框架(RDF)的目的是作为不同网站以一致的格式发布数据的一种机制,允许来自不同网站的数据自动合并成一个数据网络 - 一种互联网范围内的“关于一切的数据库“。
RDF数据模型
用RDF/XML语法表示数据
<rdf:RDF xmlns="urn:example:"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<Location rdf:nodeID="idaho">
<name>Idaho</name>
<type>state</type>
<within>
<Location rdf:nodeID="usa">
<name>United States</name>
<type>country</type>
<within>
<Location rdf:nodeID="namerica">
<name>North America</name>
<type>continent</type>
</Location>
</within>
</Location>
</within>
</Location>
<Person rdf:nodeID="lucy">
<name>Lucy</name>
<bornIn rdf:nodeID="idaho"/>
</Person>
</rdf:RDF>RDF有一些奇怪之处,因为它是为了在互联网上交换数据而设计的。三元组的主语,谓语和宾语通常是URI。
这个设计背后的原因为了让你能够把你的数据和其他人的数据结合起来,如果他们赋予单词不同的含义,两者也不会冲突,
SPARQL查询语言
SPARQL是一种用于三元组存储的面向RDF数据模型的查询语言。
用SPARQL表示示例的查询语句
PREFIX : <urn:example:>
SELECT ?personName WHERE {
?person :name ?personName.
?person :bornIn / :within* / :name "United States".
?person :livesIn / :within* / :name "Europe".
}SPARQL是一种很好的查询语言——哪怕语义网从未实现,它仍然可以成为一种应用程序内部使用的强大工具。
基础:Datalog
Datalog的数据模型类似于三元组模式,但进行了一点泛化。把三元组写成谓语(主语,宾语),而不是写三元语(主语,谓语,宾语)。
Cypher和SPARQL使用SELECT立即跳转,但是Datalog一次只进行一小步。我们定义规则,以将新谓语告诉数据库:在这里,我们定义了两个新的谓语。这些谓语不是存储在数据库中的三元组中,而是它们是从数据或其他规则派生而来的。规则可以引用其他规则,就像函数可以调用其他函数或者递归地调用自己一样。像这样,复杂的查询可以一次构建其中的一小块。
相对于本章讨论的其他查询语言,我们需要采取不同的思维方式来思考Datalog方法,但这是一种非常强大的方法,因为规则可以在不同的查询中进行组合和重用。虽然对于简单的一次性查询,显得不太方便,但是它可以更好地处理数据很复杂的情况。