最近在知乎上看到一个话题,说使用爬虫技术获取网易云音乐上的歌曲,甚至还包括付费的歌曲,哥瞬间心动了,这年头,好听的流行音乐或者经典老歌都开始收费了,只能听不能下载,着实很郁闷,现在机会来了,于是开始研究爬虫技术,翻阅各种资料,最终选择网友们一致认为比较好用的webcollector框架来实现。
首先,我们来认识一下webcollector,webcollector是一个无需配置,便于二次开发的爬虫框架,它提供精简的API,只需少量代码即可实现一个功能强大的爬虫,webcollector+hadoop是webcollector的hadoop版本,支持分布式爬取。并且在2.x版本中提供了selenium,可以处理javaScript生成的数据。我们边说便看图,看图说话,便于理解:
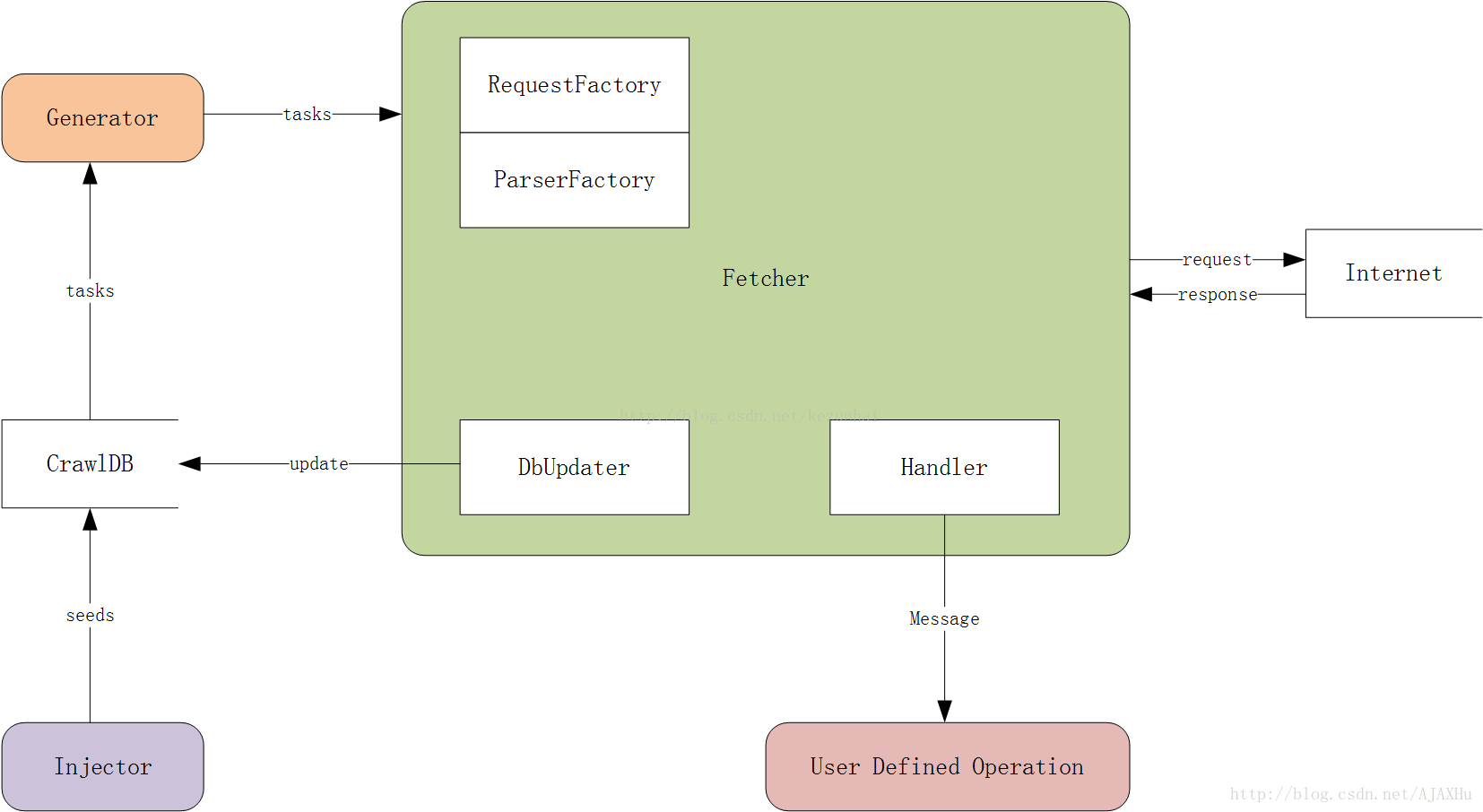
以上就是webcollector的架构图,我们来简单分析一下:
- CrawlDB: 任务数据库,爬虫的爬取任务(类似URL列表)是存放在CrawlDB中的,CrawlDB根据DbUpdater和Generator所选插件不同,可以有多种形式,如文件、Redis、MySQL、MongoDB等。
- Injector: 种子注入器,负责第一轮爬取时,向CrawlDB中提交爬取任务。在断点续爬的时候,不需要通过Injector向CrawlDB注入种子,因为CrawlDB中已有爬取任务。
- Generator: 任务生成器,任务生成器从CrawlDB获取爬取任务,并进行过滤(正则、爬取间隔等),将任务提交给抓取器。
- Fetcher: 抓取器,Fetcher是爬虫最核心的模块,Fetcher负责从Generator中获取爬取任务,用线程池来执行爬取任务,并对爬取的网页进行链接解析,将链接信息更新到CrawlDB中,作为下一轮的爬取任务。在网页被爬取成功/失败的时候,Fetcher会将网页和相关信息以消息的形式,发送到Handler的用户自定义模块,让用户自己处理网页内容(抽取、存储)。
- DbUpdater: 任务更新器,用来更新任务的状态和加入新的任务,网页爬取成功后需要更新CrawlDB中的状态,对网页做解析,发现新的连接,也需要更新CrawlDB。
- Handler: 消息发送/处理器,Fetcher利用Handler把网页信息打包,发送到用户自定义操作模块。
- User Defined Operation: 用户自定义的对网页信息进行处理的模块,例如网页抽取、存储。爬虫二次开发主要就是自定义User Defined Operation这个模块。实际上User Defined Operation也是在Handler里定义的。
- RequestFactory: Http请求生成器,通过RequestFactory来选择不同的插件,来生成Http请求,例如可以通过httpclient插件来使用httpclient作为爬虫的http请求,或者来使用可模拟登陆新浪微博的插件,来发送爬取新浪微博的http请求。
- ParserFactory: 用来选择不同的链接分析器(插件)。爬虫之所以可以从一个网页开始,向多个网页不断地爬取,就是因为它在不断的解析已知网页中的链接,来发现新的未知网页,然后对新的网页进行同样的操作。
爬取逻辑:
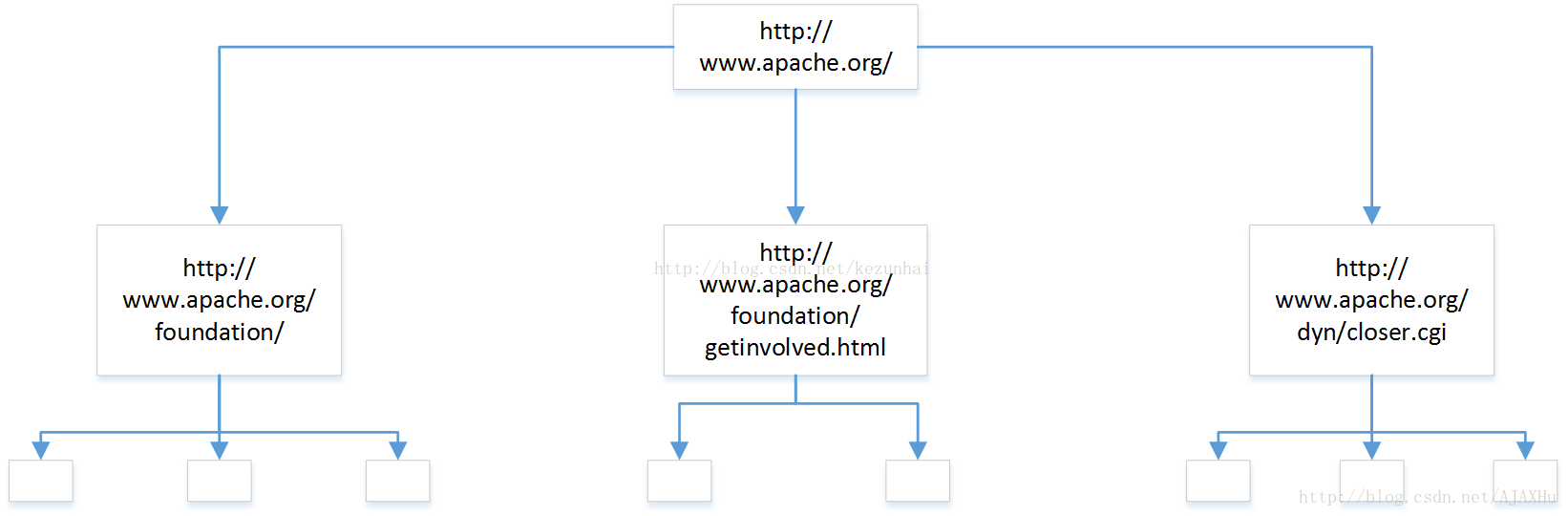
第一层:爬取一个网页,http://www.apache.org/,解析网页,获取3个链接,将3个链接保存到CrawlDB中,设置状态为未爬取。同时将http://www.apache.org/的爬取状态设置为已爬取。结束第一轮。
第二层,找到CrawlDB中状态为未爬取的页面(第一层解析出来的3个链接),分别爬取,并解析网页,一共获得8个链接。和第一层操作一样,将解析出的链接放入CrawlDB,设置为未爬取,并将第二层爬取的三个页面,状态设置为已爬取。
第三层,找到CrawlDB中状态为未爬取的页面(第二层解析出来的8个链接)……………..
每一层都可以作为一个独立的任务去运行,所以可以将一个大型的广度遍历任务,拆分成一个一个小任务。爬虫里有个参数,设置爬取的层数,指的就是这个。
插件机制:
框架图中的 Injector、Generator、Request(由RequestFactory生成)、Parser(由ParserFactory生成)、DbUpdater、Response都是以插件实现的。制作插件往往只需要自定义一个实现相关接口的类,并在相关Factory内指定即可。
WebCollector内置了一套插件(cn.edu.hfut.dmic.webcollector.plugin.redis)。基于这套插件,可以把WebCollector的任务管理放到redis数据库上,这使得WebCollector可以爬取海量的数据(上亿级别)。
对于用户来说,关注的更多的不是爬虫的爬取流程,而是对每个网页要进行什么样的操作。对网页进行抽取、保存还是其他操作,应该是由用户自定义的。
所以我们使用WebCollector来写爬虫不用那么麻烦,只用集成爬虫框架里的BreadthCrawler类并重写visit方法即可,我们先来看下官网爬取知乎的例子:
/*visit函数定制访问每个页面时所需进行的操作*/ @Override public void visit(Page page) { String question_regex="^http://www.zhihu.com/question/[0-9]+"; if(Pattern.matches(question_regex, page.getUrl())){ System.out.println("正在抽取"+page.getUrl()); /*抽取标题*/ String title=page.getDoc().title(); System.out.println(title); /*抽取提问内容*/ String question=page.getDoc().select("div[id=zh-question-detail]").text(); System.out.println(question); } } /*启动爬虫*/ public static void main(String[] args) throws IOException{ ZhihuCrawler crawler=new ZhihuCrawler(); crawler.addSeed("http://www.zhihu.com/question/21003086"); crawler.addRegex("http://www.zhihu.com/.*"); crawler.start(5); } }
我们来简单分析一下:
-
visit()方法
在整个抓取过程中,只要抓到一个复合的页面,wc都会回调该方法,并传入一个包含了所有页面信息的page对象。
-
addSeed()
添加种子,种子链接会在爬虫启动之前加入到上面所说的抓取信息中并标记为未抓取状态.这个过程称为注入。
-
addRegex
为一个url正则表达式, 过滤不必抓取的链接比如.js .jpg .css等,或者指定抓取链接的规则。比如我使用时有个正则为:http://news.hexun.com/2015-01-16/[0-9]+.html, 那么我的爬虫则只会抓取http://news.hexun.com/2015-01-16/172431075.html,http://news.hexun.com/2015-01-16/172429627.html 等news.hexun.com域名下2015-01-16日期的.html结尾的链接。
-
start()
表示启动爬虫,传入参数5表示抓取5层(深度为5),这个深度为5怎么理解呢,当只添加了一个种子, 抓这个种子链接为第1层, 解析种子链接页面跟据正则过滤想要的链接保存至待抓取记录. 那么第2层就是抓取1层保存的记录并解析保存新记录,依次类推。
至此,我们已经对webcollector有了一个大致的了解,更深入的理论知识我们就不再往下追究,毕竟高端的东西是需要更恒久的毅力和耐心去不断挖掘的,而目前我们只需要掌握简单的应用即可实现一个爬虫。
(一)需求分析:
OK,那我们先来分析一下我们此次的需求,我们要使用webcollector爬虫技术获取网易云音乐全部歌曲,我们先来看下一个网易云音乐的歌曲页面链接:http://music.163.com/#/album?id=2884361,我们会发现这个链接后面带有参数,传不同的id,可以得到不同的歌曲,所以,这就是一个模版,我们可以遍历整个网易云音乐,把其中url与上面类似的网页提取出来就可以得到网易云音乐的所有歌曲了,对吧?
那么,第二个问题,我们如何获取音乐的真实地址呢?这个通常是要用到抓包工具的,通过抓包工具获取HTTP请求下的头信息,从而得到请求的真实路径,我们通过抓包分析得到网易云音乐有一个api接口,可以得到歌曲的真实地址,api地址:http://music.163.com/api/song/detail,我们发现这个接口有几个参数:
-
id 传入上面得到的歌曲的id
-
ids ids是由id拼接而成的,ids = '%5B+' + id + '%5D'(这里的%5B...%5d是js传参的时候防止乱码加的,这个在之前的项目里有遇到过)
然后我们可以把上面的API复制进浏览器,我们会得到一段json,里面有歌曲的音频源地址。

好了,经过分析,我们已经准备好了我们需要的东西,接下来就可以开始动手操作了。
(二)开发
开发就相对很简单,没有太多的类,只是普通的Java工程,引入相应的jar包即可。
1.进入WebCollector官方网站下载最新版本所需jar包。最新版本的jar包放在webcollector-version-bin.zip中。
2.打开Eclipse,选择File->New->Java Project,按照正常步骤新建一个Java项目。
在工程根目录下新建一个文件夹lib,将刚下载的webcollector-version-bin.zip解压后得到的所有jar包放到lib文件夹下。将jar包引入到build path中。
3、新建一个类继承BreadthCrawler,重写visit方法进行url的正则匹配,抽取出url,歌曲Id,歌曲名称,演唱者,url。以及真实路径。过程很简单,我们直接看代码:
package com.ax.myBug; import java.io.ByteArrayOutputStream; import java.io.FileNotFoundException; import java.io.IOException; import java.io.InputStream; import java.net.HttpURLConnection; import java.net.URL; import java.nio.charset.Charset; import java.util.regex.Matcher; import java.util.regex.Pattern; import com.csvreader.CsvWriter; import cn.edu.hfut.dmic.webcollector.model.CrawlDatums; import cn.edu.hfut.dmic.webcollector.model.Page; import cn.edu.hfut.dmic.webcollector.plugin.berkeley.BreadthCrawler; import org.json.*; /** * 获取网易云音乐所有歌曲写入csv文件 * @author AoXiang */ public class GetAllSongs extends BreadthCrawler { private CsvWriter r = null; public void closeCsv() { this.r.close(); } /** * 转换字节流 * @param instream * @return * @throws IOException */ public static byte[] readInputStream(InputStream instream) throws IOException { ByteArrayOutputStream outStream = new ByteArrayOutputStream(); byte[] buffer = new byte[1204]; int len = 0; while ((len = instream.read(buffer)) != -1){ outStream.write(buffer,0,len); } instream.close(); return outStream.toByteArray(); } /** * 根据URL获得网页源码 * @param url 传入的URL * @return String * @throws IOException */ public static String getURLSource(URL url) throws IOException { HttpURLConnection conn = (HttpURLConnection)url.openConnection(); conn.setRequestMethod("GET"); conn.setConnectTimeout(500000);//时间可以设置的久一点,如果控制台经常提示read time out InputStream inStream = conn.getInputStream(); byte[] data = readInputStream(inStream); String htmlSource = new String(data); return htmlSource; } /** * 重写构造函数 * @param crawlPath 爬虫路径 * @param autoParse 是否自动解析 */ public GetAllSongs(String crawlPath, boolean autoParse) throws FileNotFoundException { super(crawlPath, autoParse); // 逗号进行分割,字符编码为GBK this.r = new CsvWriter("songId.csv", ',', Charset.forName("GBK")); } @Override public void visit(Page page, CrawlDatums next) { // 继承覆盖visit方法,该方法表示在每个页面进行的操作 // 参数page和next分别表示当前页面和下个URL对象的地址 // 生成文件songId.csv,第一列为歌曲id,第二列为歌曲名字,第三列为演唱者,第四列为歌曲信息的URL // 网易云音乐song页面URL地址正则 String song_regex = "^http://music.163.com/song\?id=[0-9]+"; // 创建Pattern对象 http://music.163.com/#/song?id=110411 Pattern songIdPattern = Pattern.compile("^http://music.163.com/song\?id=([0-9]+)"); Pattern songInfoPattern = Pattern.compile("(.*?)-(.*?)-"); // 对页面进行正则判断,如果有的话,将歌曲的id和网页标题提取出来,否则不进行任何操作 if (Pattern.matches(song_regex, page.getUrl())) { // 将网页的URL和网页标题提取出来,网页标题格式:歌曲名字-歌手-网易云音乐 String url = page.getUrl(); @SuppressWarnings("deprecation") String title = page.getDoc().title(); String songName = null; String songSinger = null; String songId = null; String infoUrl = null; String mp3Url = null; // 对标题进行歌曲名字、歌手解析 Matcher infoMatcher = songInfoPattern.matcher(title); if (infoMatcher.find()) { songName = infoMatcher.group(1); songSinger = infoMatcher.group(2); } System.out.println("正在抽取:" + url); // 创建Matcher对象,使用正则找出歌曲对应id Matcher idMatcher = songIdPattern.matcher(url); if (idMatcher.find()) { songId = idMatcher.group(1); } System.out.println("歌曲:" + songName); System.out.println("演唱者:" + songSinger); System.out.println("ID:" + songId); infoUrl = "http://music.163.com/api/song/detail/?id=" + songId + "&ids=%5B+" + songId + "%5D"; try { URL urlObject = new URL(infoUrl); // 获取json源码 String urlsource = getURLSource(urlObject); JSONObject j = new JSONObject(urlsource); JSONArray a = (JSONArray) j.get("songs"); JSONObject aa = (JSONObject) a.get(0); mp3Url = aa.get("mp3Url").toString(); } catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } String[] contents = {songId, songName, songSinger, url, mp3Url}; try { this.r.writeRecord(contents); this.r.flush(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } } /** * 歌曲id爬虫开始 * @param args * @throws Exception */ public static void main(String[] args) throws Exception { URL url = new URL("http://music.163.com/api/song/detail/?id=110411&ids=%5B110411%5D"); String urlsource = getURLSource(url); System.out.println(urlsource); JSONObject j = new JSONObject(urlsource); JSONArray a = (JSONArray) j.get("songs"); JSONObject aa = (JSONObject) a.get(0); System.out.println(aa.get("mp3Url")); GetAllSongs crawler = new GetAllSongs("crawler", true); // 添加初始种子页面http://music.163.com crawler.addSeed("http://music.163.com/#/album?id=604667405"); // 设置采集规则为所有类型的网页 crawler.addRegex("http://music.163.com/.*"); // 设置爬取URL数量的上限 crawler.setTopN(500000000); // 设置线程数 crawler.setThreads(30); // 设置断点采集 crawler.setResumable(false); // 设置爬虫深度 crawler.start(5); } }
(三)测试
直接运行Java程序,查看控制台

然后去到我们的workSpace,我们会发现提取出的歌曲信息已经写入了csv文件,

我们打开文件,可以看到里面已经拿到了我们想要的数据

OK,经过一番折腾,我们已经大功告成了,是不是很简单呢?当然,学习的过程也是很曲折的,有了这个技术,我们不仅可以爬取网易云音乐,还可以爬取各类新闻网站,拿到他们的数据来为我们自己所用,当然,现在的很多网站在安全方面都做的相当不错,或者比较抠门,不愿意资源共享,采用了反爬机制,所以,我们要做的就是更深入的更全面的了解爬虫技术,掌握其中的要领和精髓,灵活运用,那么,我相信再密不透风的网站我们也能爬的进去。因为我们的目标是星辰大海!
附上项目源码以及已经爬取的17万多的网易云音乐歌曲Excel:https://git.oschina.net/AuSiang/myBug/attach_files