一、链表的定义
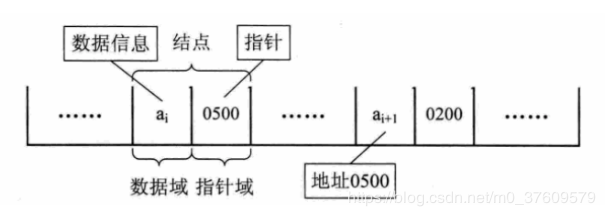
【百度百科】链表(LinikedList)是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。
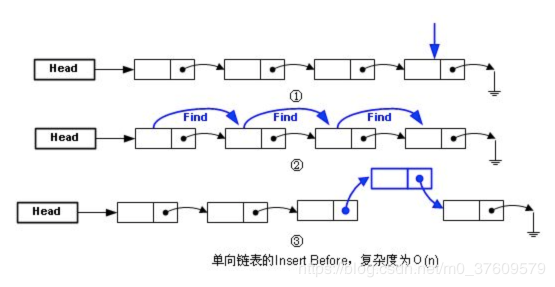
相比于线性表顺序结构,操作复杂。由于不必须按顺序存储,链表在插入的时候可以达到O(1)的复杂度,比另一种线性表顺序表快得多,但是查找一个节点或者访问特定编号的节点则需要O(n)的时间,而线性表和顺序表相应的时间复杂度分别是O(logn)和O(1)。
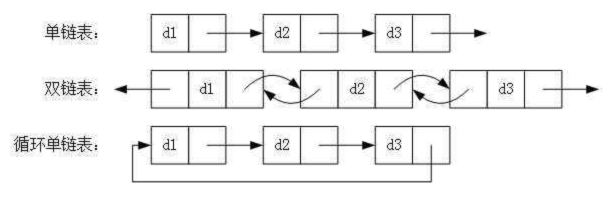
链表最明显的好处就是,常规数组排列关联项目的方式可能不同于这些数据项目在记忆体或磁盘上顺序,数据的存取往往要在不同的排列顺序中转换。链表允许插入和移除表上任意位置上的节点,但是不允许随机存取。链表有很多种不同的类型:单向链表,双向链表以及循环链表。
二、各种链表实现示意图
三、链表的操作
1.单向链表
2.双向链表

3.循环链表
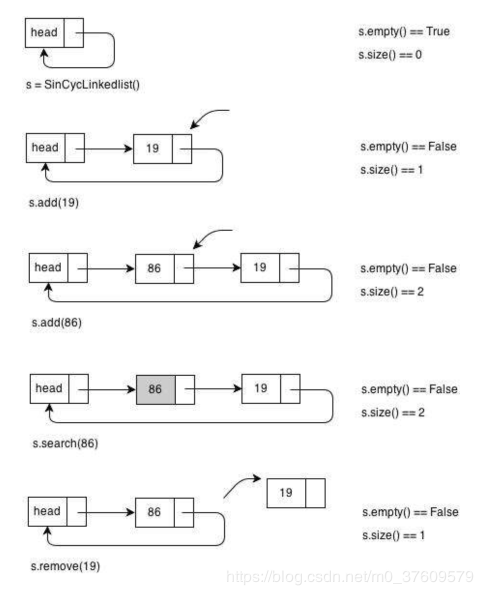
四、约瑟夫环问题实现
n 个人围成一个圆圈,首先第 k个人从 1 开始一个人一个人顺时针报数,报到第 m 个人,令其出列。然后再从下一 个人开始从 1 顺时针报数,报到第 m 个人,再令其出列,…,如此下去,求出列顺序。
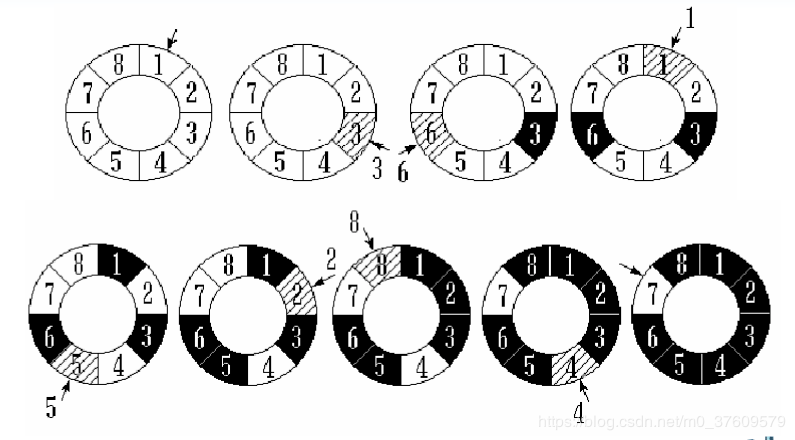
这个问题可以转化成数据结构的循环链表问题。具体抽象为创建循环链表,输出链表,按照题意找到符合要求的那个结点并删除,循环删除的过程,直到循环链表只剩下一个元素,即为最后一个出队的元素。
首页 博客 学院 下载 论坛 APP 问答 商城 活动 VIP会员 专题 招聘 ITeye GitChat 图文课 Python工程师 写博客 消息3 Markdown编辑器 富文本编辑器 查看主页 内容 文章管理 评论管理 分类专栏 博客搬家 收益中心 数据 百度热搜词条 自定义百度统计 设置 博客设置 体验新模版 自定义域名 博客模块管理 CSDN博客交流群 打开手机QQ扫码 或点击这里加入群聊 QQ客服 程序员的进阶课-架构师之路(6)-链表 19/100 文章标签: 数据结构 链表 添加标签 最多添加5个标签 分类专栏: 架构 程序员的进阶课-架构师之路 添加新分类 最多添加3个标签,#为二级分类 资源信息: 请填写资源链接 上传资源 文章类型: * 申请原创将启用(Creative Commons )版权模板,如果不是原创文章,请选择转载或翻译 发布形式: 客服 /** * 总人数n:7 从第几个开始k:3 报数淘汰m:3 * java 环形链表实现约瑟夫(Joseph)问题 */ public class JosephCycle { public static void main(String []args){ CycleLink cl = new CycleLink(); cl.setLen(7); cl.setK(3); cl.setM(3); cl.creatLink(); cl.play(); cl.show(); } } class Node{ int num; Node nextNode = null; public Node(int num){ this.num = num; } } class CycleLink{ int len; int k ; int m ; Node firstNode = null; Node temp = null; public void setLen(int len){ this.len = len; } public void setK(int k){ this.k = k; } public void setM(int m){ this.m =m; } //创建链表 public void creatLink(){ for(int i = 1; i <= len ; i++){ // 处理首节点 if(i==1){ Node nd= new Node(i); firstNode = nd; temp = nd; }else if(i == len){ //处理末节点 Node nd = new Node(i); temp.nextNode = nd; temp = nd; temp.nextNode = firstNode; }else{ Node nd = new Node(i); temp.nextNode = nd; temp = nd; } } } public void play(){ temp = firstNode; // 先找到编号为k的节点 for(int i = 1 ; i < k; i++){ temp = temp.nextNode; } while(this.len !=1){ //报数,找到m的上一个节点 for(int j = 1 ;j < m-1; j++){ temp = temp.nextNode; } //因为少报了 1 ,所以将下一个节点删除,并从下下一个节点重新开始报数 System.out.println("要删除的节点: "+temp.nextNode.num); /** * 如果删除节点是firstNode,则将firstNode更新为下一个节点 * 注意不能用编号判断,因为新的编号对应的节点有可能又被删除 */ if(temp.nextNode==firstNode){ firstNode = temp.nextNode.nextNode; } temp.nextNode = temp.nextNode.nextNode; temp = temp.nextNode; //this.show(); this.len--; } } /** * 遍历链表打印整个链表 */ public void show(){ temp = firstNode; do{ System.out.println(temp.num); temp = temp.nextNode; }while(temp != firstNode); } }
运行结果:
要删除的节点: 5 要删除的节点: 1 要删除的节点: 4 要删除的节点: 2 要删除的节点: 7 要删除的节点: 3 6
五、Java中的链表类
LinkedList类的本质是是一个双向链表,也常可以当作堆栈、队列或这双端队列,所以在随机插入、随机删除时比ArrayList类的效率要高。特别是可以直接对集合的首部和尾部元素进行插入和删除操作,LinkedList提供了专门针对首尾元素的方法,
六、抽象数据类型(ADT)
是指一个数学模型及定义在该模型上的一组操作。它仅取决于其逻辑特征,而与计算机内部如何表示和实现无关。
栈和队列这两种数据结构,我们可以分别使用数组和链表来实现,比如栈,对于使用者只需要知道pop()和push()方法或其它方法的存在以及如何使用即可,使用者不需要知道我们是使用的数组或是链表来实现的。
这在我们Java语言中的接口设计理念是相通的。
七、链表的应用场景
1、单向链接
单向链表适用于只从一端单向访问的场合,这种场合一般来说:
- 删除时,只适合删除第一个元素;
- 添加时,只直接添加到最后一个元素的后面或者添加到第一个元素的前面;
- 属于单向迭代器,只能从一个方向走到头(只支持前进或后退,取决于实现),查找效率极差。不适合大量查询的场合。
这种典型的应用场合是各类缓冲池和栈的实现。
2、双向链表
双向链表相比单向链表,拥有前向和后向两个指针地址,所以适合以下场合:
- 删除时,可以删除任意元素,而只需要极小的开销;
- 添加时,当知道它的前一个或后一个位置的元素时,只需要极小的开销。
- 属于双向迭代器,可以从头走到尾或从尾走到头,但同样查找时需要遍历,效率与单向链表无改善,不适合大量查询的场合。
这种典型的应用场景是各种不需要排序的数据列表管理。
八、总结
上面我们讲了各种链表,每个链表都包括一个LinikedList对象和许多Node对象,LinkedList对象通常包含头和尾节点的引用,分别指向链表的第一个节点和最后一个节点。而每个节点对象通常包含数据部分data,以及对上一个节点的引用prev和下一个节点的引用next,只有下一个节点的引用称为单向链表,两个都有的称为双向链表。next值为null则说明是链表的结尾,如果想找到某个节点,我们必须从第一个节点开始遍历,不断通过next找到下一个节点,直到找到所需要的。栈和队列都是ADT,可以用数组来实现,也可以用链表实现。
我的微信公众号:架构真经(id:gentoo666),分享Java干货,高并发编程,热门技术教程,微服务及分布式技术,架构设计,区块链技术,人工智能,大数据,Java面试题,以及前沿热门资讯等。每日更新哦!

参考文章: