一、文本处理工具
1、grep工具
grep:在文件中全局查找指定的正则表达式,并打印所有包含该表达式的行
egrep:扩展的egrep,支持更多的正则表达式元字符
fgrep:固定grep(fixed grep),有时也被称作快速(fast grep)按字面解释所有的字符
行过滤工具;用于根据关键字进行过滤
语法:
grep 【选项】 'pattern/关键字' 文件名
常见选项
--color=auto :将找出的关键词加上颜色显示 ^$:匹配空行 key$:以关键字结尾 ^key:以关键字开头 -E:使用扩展正则匹配 -e:使用正则匹配 -L:列出不匹配的文件名 -l:列出匹配的文件名 -C :列出匹配行前后多少行 -B:列出匹配行及前面多少行 -A:显示匹配行及后面多少行 -r:逐层遍历目录查找 -n:显示行号
-i:忽略大小写
返回结果
找到:grep返回的退出状态为0
没找到: 没找到返回为1
找不到指定文件: 2
grep使用的元字符
grep : 使用基本的元字符^,$,.,*,[],[^],<>,(),{}
egrep : 使用扩展字符集 ?,+,{},|,()
注:grep也可以使用扩展集中的元字符,但需要在元字符前置一个反斜杠
2、CUT工具
cut是列截取工具,用于列的截取
语法:
cut 选项 文件名
-c: 以字符为单位进行分隔,截取
-d:自定义分隔符,默认为制表符
-f: 与-d一起使用,指定截取哪个区域
3、sort工具
sort工具用于排序;它将文件的每一行作为一个单位,从首字符后,依次按ASCII码值进行比较,最后按升序输出
语法和选项
-u:去除重复行 -r:降序排列,默认是升序 -o:将排序结果输出到文件中,类似重定向符号> -n:以数字排序,默认是按字符排序 -t:分隔符 -k:第n列 -b:忽略前导空格 -R:随机排序,每次运行的结果均不同
4、uniq工具
去除连续的重复行
-i:忽略大小写 -c:统计重复次数 -d:值显示重复行
5、tee工具
从标准输入读取并写入到标准输出和文件(将输入一部分写在屏幕,一部分写入文件)
选项:
-a 双向追加重定向

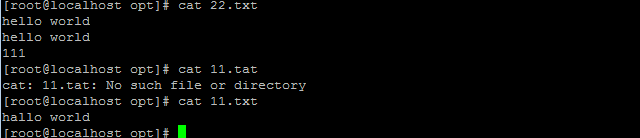
hello world在写到屏幕的同时写入了11.txt
6、diff工具
逐行比较文件的不同
diff描述的是两个文件的不同:怎样改变第一个文件后可以与第二个文件进行匹配
常用选项:
-b 不检查空格 -B 不检查空白行 -i 不检查大小写 -w 忽略所有的空格 -normal 正常格式显示(默认) -c 上下文格式显示 -u 合并格式显示

意思是将第一个文件的1,3行改变才能和第二个文件的第一行进行匹配
上下文模式:
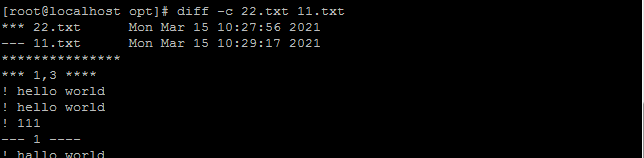
图表表示:三个*表示第一个文件
三个-表示第二个文件
!表示该行需要修改
合并模式:


7、find 工具
i 参数:不区分大小写
主要用来找某些特殊的文件
find命令是不能跟管道来使用的
find 路径 -name "名称"
find 路径 -size
查找大于2k的文件
[root@localhost home]# find ./ -size +2k
./newdisk
./newdisk/lost+found
查找大于2k 小于10k的文件
[root@localhost home]# find ./ -size +2k -size -10k
./newdisk
-type -d/-f/-p/-l/-s/-c/-b 指定搜索的文件类型
f:普通文件
d:目录文件
l:符号链接文件
s: 套接字文件
b:块设备文件
c:字符设备文件
p:管道文件
找出所有的文件,是递归找的
find ./ -type f
-maxdepth 指定搜索的层级
[root@localhost home]# find ./ -maxdepth 1 -type f ./passwd
-exec 当文件搜索好后,要执行命令使用
[root@localhost home]# find ./ -maxdepth 1 -type f -exec ls -l {} ; -rwxrwxrwx. 1 root root 1200 Mar 17 09:26 ./passwd
这里为什么需要{} ;斜杠进行对分号的转义
-ok 和exec功能相似,会有交互
-xargs 将find查找的结果分批进行处理(可结合管道使用)
[root@localhost home]# find ./ -maxdepth 1 -type f | xargs ls -ldh -rwxrwxrwx. 1 root root 1.2K Mar 17 09:26 ./passwd
根据属主、属组搜索
-user USERNAME :查找属主为指定用户的(UID)的文件
-group GRPNAME:查找属组为指定(GID)的文件
-uid UserID : 查找属主为指定的UID号的文件
-gid GroupID : 查找数组为指定GID号的文件
-nouser : 查找没有属主的文件
-nogroup : 查找没有数组的文件
[root@localhost home]# find ./ -maxdepth 1 -user root -type f -ls 53803022 4 -rwxrwxrwx 1 root root 1200 Mar 17 09:26 ./passwd

-o 是或的意思 -a 是并且的意思
-not,!非
-empty 空文件
根据权限查找
find -perm 600 -ls
查找权限为600的文件,为精确匹配
[root@localhost home]# find -perm /600 -ls 50352472 0 drwxr-xr-x 11 root root 144 Mar 17 09:26 .
加/是或者的意思,查找所有权限为6或者 所属组权限为0 或者其他权限为0
[root@localhost home]# find -perm -600 -ls
50352472 0 drwxr-xr-x 11 root root 144 Mar 17 09:26 .
-是包含的意思,所有者包含6权限,所属组包含0权限,其他包含0权限
shell是解释性语言
二、shell语法
bash -x test.sh
可以看出哪行出问题了
bash -n test.sh
可以检查脚本语法错误
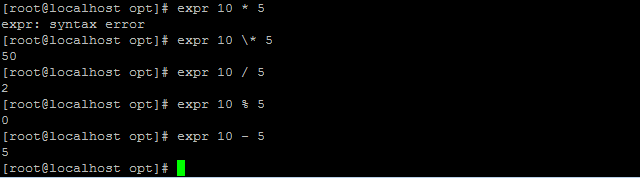
四则运算
加减用( ) 乘除用[ ]
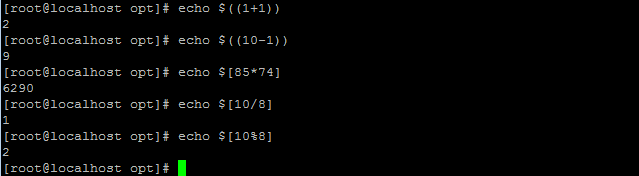
使用expr 注意*要进行转义
四、条件判断语句
格式:
格式1:test条件表达式
格式2:【条件表达式】
格式3:【 【条件表达式】】支持正则=-
man test
列出test的所有选项,并有解释
-e 判断文件是否存在(任何类型文件)
-f 判断文件是否存在并且是一个普通文件
-d 判断文件是否存在并且是一个目录
-L 判断文件是否存在并且是一个软连接
-b 判断文件是否存在并且是一个块设备
-S 判断文件是否存在并且是一个套接字
-c 判断文件是否存在并且是一个字符设备文件
-p 判断文件是否存在并且是一个命名管道文件
-s 判断文件是否存在并且是一个非空文件(有内容)

$?判断上一条命令的执行结果
如果为0就是真,非0就是假

2、判断文件权限
-r 当前用户对其是否可读 -w 当前用户对其是否可写 -x 当前用户对其是否可执行 -u 是否有suid,高级权限冒险位 -g 是否sgid 高级权限强制位 -k 是否有t位 高级权限粘滞位

3、判断文件新旧(指文件的修改时间)
file1 -nt file2 比较file1是否比file2新 file1 -ot file2 比较file1是否比file2旧 file1 -ef file2 比较是否是同一个文件,或者用于判断硬连接,是否指向同一个inode

4、整数的判断
-eq 相等 -ne 不等 -gt 大于 -lt 小于 -ge 大于等于 -le 小于等于
5.判断字符串
-z 判断是否为空字符串,字符串长度为0则成立 -n 判断是否为非空字符串,字符串长度不为0则成立 string1=string2 判断字符串是否相等 string1!=string2 判断字符串是否不等
6、多重条件判断
-a 和 && 【1 -eq 1 -a 1 -ne 0】【1 -eq 1】&& 【1 -ne 0】 -o 和 ||
判断普通用户还是管理员
【id -u】-eq 0
判断【表达式】和【 【表达式】】的区别
加引号的区别

五、流程控制语句
if 结构
if 【condition】;then command command fi
if...else 结构
if【condition】;then command1 else command2 fi
if...elif..else结构
if 【condition1】;then command1 elif 【condition2】;then command2 else command3 fi
六、循环
列表循环:用于将一组命令执行已知的次数
for variable in {list} do command1 command2 done
不带列表循环
不带列表的for循环执行时由用户指定参数和参数的个数
for variable do command command done
七、while循环
while 表达式 do command done
影响shell程序的内置命令
exit 退出整个程序
break 结束当前循环,或跳出本层循环
continue 忽略本次循环剩下的
shift 使位置参数向左移动
八、sudo介绍
给普通用户授权
visudo命令打开文件

九、普通数组定义
数组的分类
普通数组:只能使用整数作为数组索引(元素的下标)
关联数组:可以使用字符串作为数组索引(元素的下标)
普通数组的定义
一次赋予一个值
array[0]=v1 array[0]=v2 array[0]=v3
一次赋予多个值
数组名=(值1 值2 值3)
输出数组的所有元素
echo ${[数组名 [*] ]}
数组切片
获取数组的部分元素
echo ${array[*]:1:2}
获取数组元素的索引下标
[root@localhost opt]# echo ${!array[@]}
0 1 2
[root@localhost opt]#
获取数组里所有元素的个数
[root@localhost opt]# echo ${#array[*]}
3
十、函数
shell中允许将一组命令集合或语句形成一段可用代码,这些代码块称为shell函数
给这段代码起个名字称为函数名,后续可以直接调用该段代码的功能
函数名()
{
函数体(一堆命令的集合,来实现某个功能)
}
function 函数名()
{
函数体
}
函数中的return说明:
1、可以结束一个函数
2、return默认返回函数中最后一个命令的状态值,也可以给定参数值,范围是0-256
3、如果没有return命令,函数将返回最后一个指令的退出状态
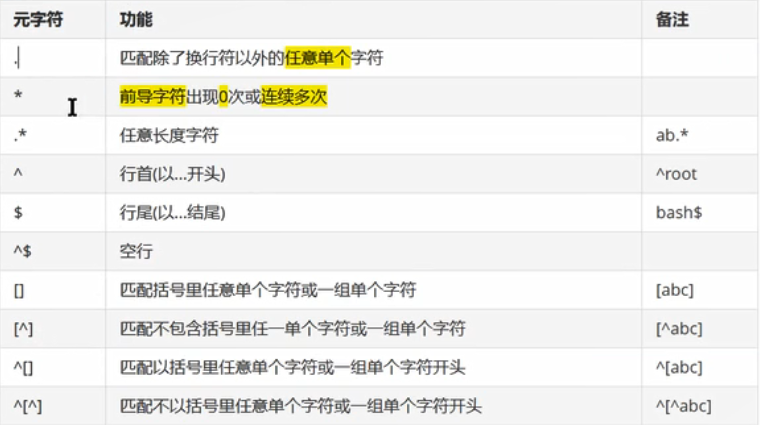
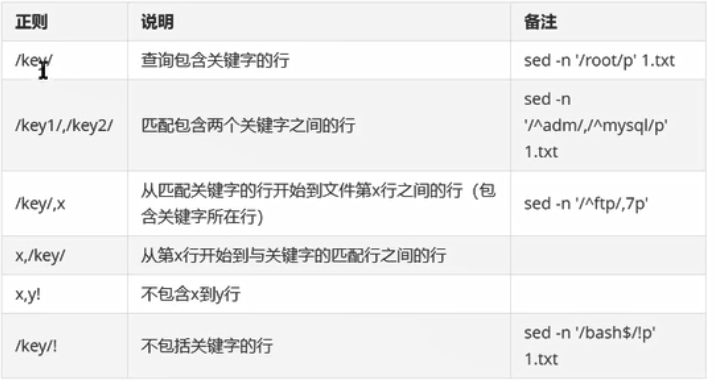
十一、正则表达式
处理文件 grep sed awk
元字符:如点(.)星(*)问号(?)
前导字符 位于元字符前面的字符
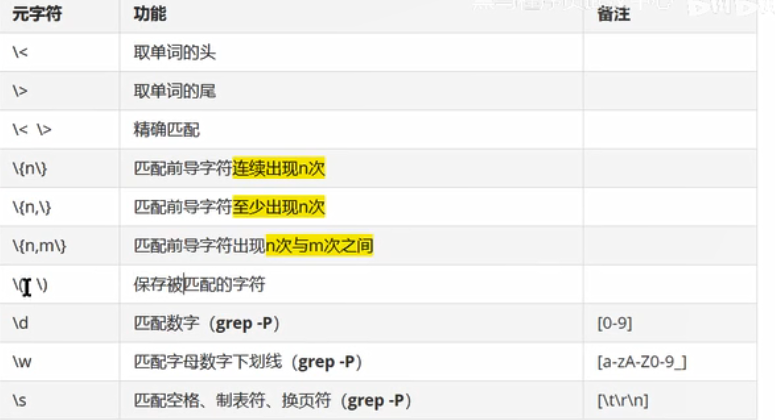
(一)正则中普通常用的元字符
十一、Sed
sed常见的语法格式有两种,一种叫命令模式,另一种叫脚本模式
1.命令行模式
语法格式
sed 【options】‘处理动作’ 文件名
常用选项
-e 进行多项(多次)编辑 -n 取消默认输出(不理解) -r 使用扩展正则表达式 -i 原地编辑(修改源文件) -f 指定sed脚本的文件名
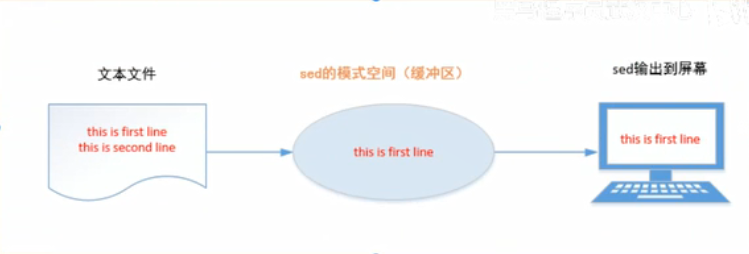
-n就是不输出到屏幕
常见的处理动作:
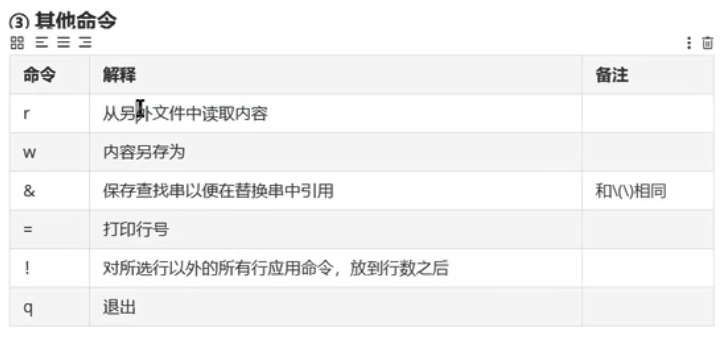
'p' 打印 'i' 在指定行之前插入内容 'a' 在指定行之后插入内容 'c' 替换指定行的所有内容 'd' 删除指定行
对文件进行增、删、改、查操作
sed 选项 ‘定位+命令’ 需要处理的文件

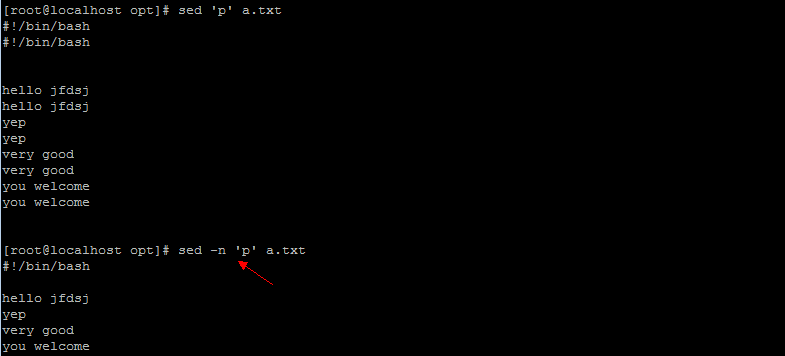
打印1,5
[root@localhost opt]# sed -n '1,5p' a.txt #!/bin/bash hello jfdsj yep very good
打印最后一行
sed -n '$p' a.txt
文件里增加内容
i 上面插入内容
换行插入 [root@localhost opt]# sed '1i hello menlisha' a.txt hello menlisha
a 下面插入内容
[root@localhost opt]# sed '$a999' a.txt #!/bin/bash hello jfdsj yep very good you welcome 999
2,4行插入
[root@localhost opt]# sed '2,4a999' a.txt #!/bin/bash hello jfdsj 999 yep 999 very good 999 you welcome
修改文件内容
-c 修改一整行
[root@localhost opt]# sed '$che' a.txt #!/bin/bash hello jfdsj yep very good you welcome he
根据正则匹配进行替换
先匹配到hello jfdsf 替换成wo
正则匹配写在/ 之间 /
[root@localhost opt]# sed '/^he/cwo' a.txt #!/bin/bash wo yep very good you welcome
删除整行
[root@localhost opt]# sed '2d' a.txt #!/bin/bash yep very good you welcome
对文件进行搜素替换
语法:sed 选项 's/搜索的内容/替换的内容/动作' 需要处理的文件
其中,s表示search搜索 ,斜杠/表示分隔符,可以自己定义 ;动作一般是打印和全局替换g (全局的意思)
[root@localhost opt]# sed 's/ye/ROOT/p' a.txt #!/bin/bash hello jfdsj ROOTp ROOTp very good you welcome
删除#
sed -n ‘s/^#//gp’ a.txt
加注释
[root@localhost opt]# sed -n '1,5s/^/#/gp' a.txt ##!/bin/bash #hello jfdsj #yep #very good #you welcome
常用选项
-e 多项编辑
[root@localhost opt]# sed -e '/^y/d' -e '/^v/d' a.txt #!/bin/bash hello jfdsj
-r 扩展正则
[root@localhost opt]# sed -r '/^y|^v/d' a.txt #!/bin/bash hello jfdsj
-i 修改源文件
[root@localhost opt]# sed -i 's/y/Andy/pg' a.txt
十二、AWK
熟悉awk的命令hangar模式基本语法结构
熟悉awk的相关内部变量
熟悉awk常用的打印函数print
能在awk中匹配正则表达打印相关的行
语法结构
awk 选项 '命令部分' 文件名 特别说明: 引用shell变量需要用双引号引起
常用选项介绍
-F 定义分隔符符号,默认的分隔符符号是空格
-v 定义变量并赋值
命令部分
正则,地址定位

{awk语句1;awk语句2}

脚本模式使用
脚本编写:
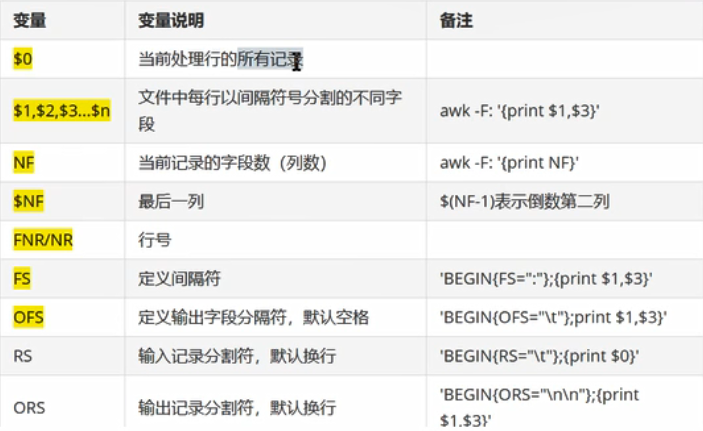
awk常用变量
打印所有行
[root@localhost opt]# awk '{print $0}' 1.txt root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin sync:x:5:0:sync:/sbin:/bin/sync shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown halt:x:7:0:halt:/sbin:/sbin/halt mail:x:8:12:mail:/var/spool/mail:/sbin/nologin operator:x:11:0:operator:/root:/sbin/nologin
打印1-5行
[root@localhost opt]# awk 'NR==1,NR==5{print $0}' 1.txt root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
打印以逗号分隔的第一列和最后一列
[root@localhost opt]# awk -F: '{print $1,$NF}' 1.txt root /bin/bash bin /sbin/nologin daemon /sbin/nologin adm /sbin/nologin lp /sbin/nologin
特殊命令
awk是读一行处理一行
BEGIN{} 行处理前
{} 行处理
END{} 行处理后
[root@localhost home]# awk 'BEGIN{FS=":"} {print $1}' passwd root bin
通常用来定义分隔符