有兴趣的同学可以移步笔者的个人博客 更多博客
Map
Map接口规定了一系列的操作,作为一个总规范它所定义的方法也是最基础,最通用的。
AbstractMap
AbstractMap是HashMap、TreeMap,、ConcurrentHashMap 等类的父类。当我们宏观去理解Map时会发现,其实Map就是一个保存Entry<K,V>的数组,AbstractMap类的设计就是用代码来描述这句话。
AbstractMap的设计思路是将方法的实现都建立在操作Entry<K,V>数组上,从而将对Map所有方法的抽象转变为粒度更小的Entry<K,V>数组对象的抽象,从而不同的Map实现类只需要简单的继承AbstractMap,并且实现entrySet()方法去构造Entry<K,V>数组,便可以实现一个最简单的Map了。
//AbstractMap中唯一的抽象方法
public abstract Set<Entry<K,V>> entrySet();
当通过实现entrySet()方法后,构造出自己的Entry集合后,其它常用操作便已经被AbstractMap去实现好了。
//根据key获取value
public V get(Object key) {
Iterator<Entry<K,V>> i = entrySet().iterator();
if (key==null) {
while (i.hasNext()) {
Entry<K,V> e = i.next();
if (e.getKey()==null)
return e.getValue();
}
} else {
while (i.hasNext()) {
Entry<K,V> e = i.next();
if (key.equals(e.getKey()))
return e.getValue();
}
}
return null;
}
//判断value是否存在
public boolean containsValue(Object value) {
Iterator<Entry<K,V>> i = entrySet().iterator();
if (value==null) {
while (i.hasNext()) {
Entry<K,V> e = i.next();
if (e.getValue()==null)
return true;
}
} else {
while (i.hasNext()) {
Entry<K,V> e = i.next();
if (value.equals(e.getValue()))
return true;
}
}
return false;
}
//判断key是否存在
public boolean containsKey(Object key) {
Iterator<Map.Entry<K,V>> i = entrySet().iterator();
if (key==null) {
while (i.hasNext()) {
Entry<K,V> e = i.next();
if (e.getKey()==null)
return true;
}
} else {
while (i.hasNext()) {
Entry<K,V> e = i.next();
if (key.equals(e.getKey()))
return true;
}
}
return false;
}
AbstractMap作为抽象类的意义就是为了使它将抽象的粒度缩小到最低,低到只对外提供一个抽象方法,而却将应用范围扩大,大到成为基本所有Map实现类的父类。
HashMap概述
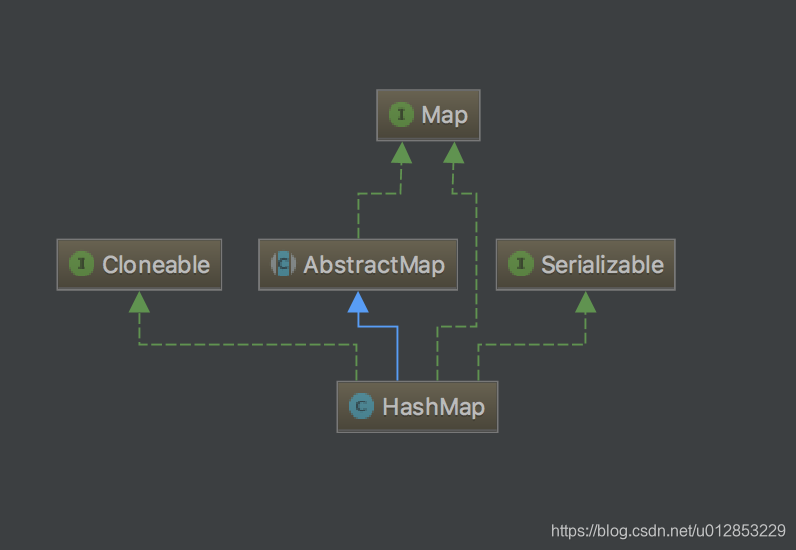
HashMap是Map接口中最常用的一个实现类了,HashMap的主干部分是一个数组,每个数组中存放的都是一个链表,当链表超过一个设定的阈值时,又会转变为一个红黑树。
HashMap的这种数据结构是为了提高hash冲突多后的查找效率,我们如果只考虑功能,而不考虑性能、时间复杂度的情况下,去实现一个存放Key,Value的数据结构其实很容易,直接去定义一个Entry数组即可,这样我们就实现了Map的功能了,而查找的时间复杂度也很容易算出来是O(n),显然这种时间复杂度作为一个优秀编程语言的底层集合容器是不能被接受的,而HashMpa则通过Hash函数直接将Key映射为Value的内存地址,从而在近似O(1)的时间内查询到数据的值。
HashMap中hash函数设计
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
hashMap在hash映射过程中,hashCode的值是一个32位的二进制数,约为40亿,要是直接使用,则需要分配tab的大小为40多亿,这显然是不合理的。
hashMap的容量都是2的n次方,默认值为16,这样的规则就是为了通过hashMap的容量-1去得出低位掩码,如16-1为0000000000000000000000000000001111,通过掩码与hashcode进行与操作,从而将hash值范围固定在hashMap的容量以内,使用(h = key.hashCode()) ^ (h >>> 16)这步操作使key的高位低位都参与到运算,避免低位相同高位不同的hashCode产生碰撞。进过上面处理的hash值将能够尽可能的保证少的碰撞,并且能够将长度与tab的长度一致。