Data - References
01 - 数据分析与数据挖掘的知识列表
图解

知识列表
| 关注方面 | 初级数据分析师 | 高级数据分析师 | 数据挖掘工程师 |
|---|---|---|---|
| 数学知识 | 了解统计相关基础内容,一定的公式计算能力,了解常用统计模型算法 | 统计模型相关知识,线性代数(矩阵计算) | 统计学算法熟练使用 |
| 分析工具 | Excel(数据透视表和公式)熟练,SQL/VBA是加分,SPSS | SQL/VBA是基本,R/python熟练,其他分析工具视情况而定。 | Excel基础,主要工作由代码来解决 |
| 编程语言 | SQL,Hadoop和Hive查询 | SQL,Python | 熟悉Hadoop,Python/Java,Shell基础 |
| 业务理解 | 基本了解业务,提取数据、展示图表、洞察结论 | 深入了解业务,基于数据提炼有效观点 | 基本了解业务 |
| 逻辑思维 | 目的性,以终为始,知道需要用什么样的途径,达到什么样的目标。 | 框架式分析,关联式分析,因果推导 | 分析业务相关,包括算法逻辑,程序逻辑等 |
| 数据可视化 | 利用Excel和PPT出具图表和报告,清楚展示数据 | 探寻更好的展示方法,使用更有效的工具,出具针对性的数据内容 | 了解工具,出具简洁图表和报告 |
| 协调沟通 | 了解业务、寻找数据、讲解报告,跨部门沟通与协调 | 独立引领、协调、推动项目 | 侧重技术沟通,基本沟通协调能力 |
02 - 一些错觉
03 - Python数据科学速查表
Python数据科学速查表汇总 - 下载地址:https://github.com/anliven/Temporary/tree/master/Python-Data-Science-Cheatsheet
04 - 关于数据科学的几个思维导图
05 - PyData
- https://pydata.org/
- PyData is an educational program of NumFOCUS, a nonprofit charity promoting the use of accessible and reproducible computing in science and technology.
- THE PYTHON OPEN DATA SCIENCE STACK:https://pydata.org/downloads/
06 - Pandas生态环境(Pandas Ecosystem)
- http://pandas.pydata.org/pandas-docs/stable/ecosystem.html
- 一个详尽的基于Pandas构建的项目列表,例如Statsmodels、seaborn等。
07 - 一些中文教程
- NumPy教程:http://www.runoob.com/numpy/numpy-tutorial.html
- Matplotlib教程:http://www.runoob.com/w3cnote/matplotlib-tutorial.html
08 - npz文件格式
- “.npz”是NumPy的数据压缩格式。
- NPZ file is a NumPy Zipped Data. NumPy is the fundamental package for scientific computing in Python.
- The .npz file format is a zipped archive of files named after the variables they contain.
示例:查看“.npz”文件中数据
import pathlib
cwd = str(pathlib.Path.cwd()) + "\" # 当前目录
np_data = np.load(cwd + "sample.npz")
print("np_data keys: ", list(np_data.keys())) # 查看所有的键
print("np_data values: ", list(np_data.values())) # 查看所有的值
print("np_data items: ", list(np_data.items())) # 查看所有的item
09 - 一些网站及工具
- http://stats.blue/index.html : Stats.Blue is a Free, Easy-To-Use, Online Statistical Software Suite.
- https://towardsdatascience.com/ : Sharing concepts, ideas, and codes
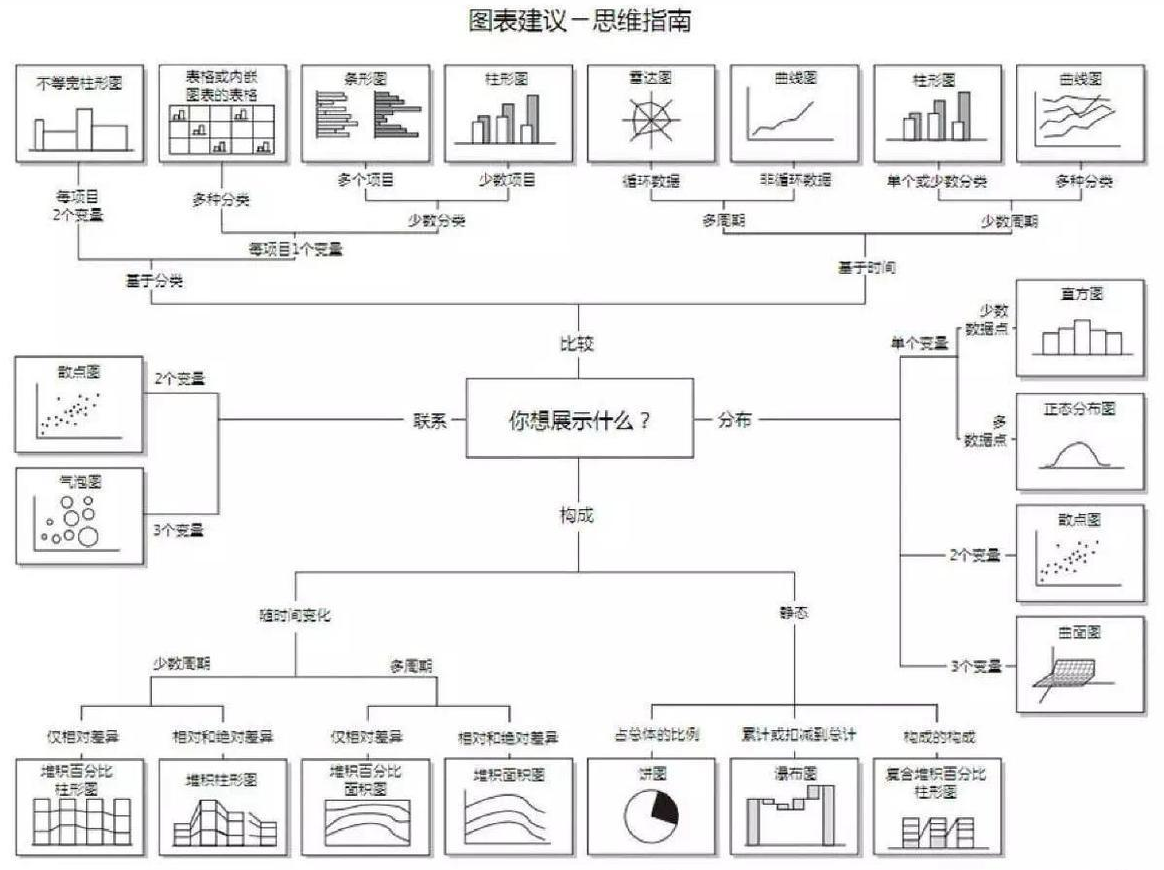
10 - 数据可视化的图表建议
11 - Data Science all-in-one table

12 - 概率分布曲线
想准确地预测变量,那么首先要了解目标变量的基本行为。
- 确定目标变量可能输出的结果,以及这个可能的输出结果是离散值(孤立值)还是连续值(无限值)。
- 为事件(值)分配概率:如果一个值不会出现,则概率为 0%。概率越高,事件发生的可能性就越大。
大量重复一个实验,并记录检索到的变量值,根据这些值作图,就可以得到一个概率分布曲线。
这个图表明目标变量得到一个值的概率,也就是该变量的概率分布。
理解了值的分布方式后,就可以开始估计事件的概率了,甚至可以使用公式(概率分布函数)。
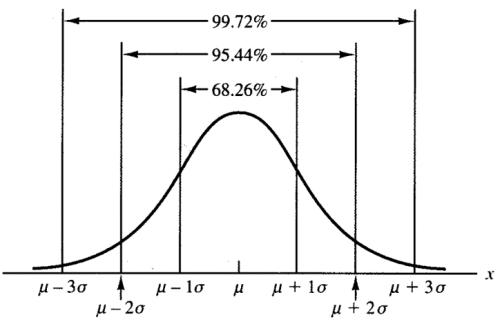
13 - 正态分布(Normal distribution)
也称为正态概率分布、“常态分布”、高斯分布(以著名数学家高斯的名字命名),是最常用的概率分布。
正态分布是只依赖数据集中两个参数的分布
- 平均值:样本中所有点的平均值。
- 标准差:表示数据集与样本均值的偏离程度。
如果对概率分布作图,将得到一条倒钟形曲线,样本的平均值、众数以及中位数是相等的,那么该变量就是正态分布的。
也就是说,只要用平均值和标准差就可以解释整个分布,因此预测任何呈正态分布的变量准确率通常都很高。
自然界和日常工作生活中的大部分变量都呈置信度为 x% 的正态分布(x<100),也就是说差不多都能用高斯分布描述。
14 - 大数定律
在随机试验中,每次出现的结果不同,但是大量重复试验出现的结果的平均值却几乎总是接近于某个确定的值。
其原因是,在大量的观察试验中,个别的、偶然的因素影响而产生的差异将会相互抵消,从而使现象的必然规律性显示出来。