【学习总结】《大话数据结构》- 总
第7章图-代码链接
启示:
-
图

目录
- 7.1 开场白
- 7.2 图的定义
- 7.3 图的抽象数据类型
- 7.4 图的存储结构
- 7.5 图的遍历
- 7.6 最小生成树
- 7.7 最短路径
- 7.8 拓扑排序
- 7.9 关键路径
- 7.10 总结回顾
- 7.11 结尾语
========================================
注:
-
对最小生成树部分的两个算法云里雾里的,暂留。
========================================
7.1 开场白
- 一些可以略过的场面话...
========================================
7.2 图的定义
-
图的定义

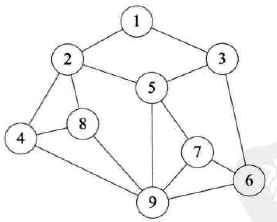
-
1、顶点(Vertex):图中的数据元素称为顶点。
(注:线性表中的数据元素叫元素,树中的数据元素叫结点)
-
2、顶点有穷非空:有空表,空树,但图结构中,不允许没有顶点。
-
3、边:顶点之间的逻辑关系用边表示,任意两个顶点之间都可能有关系
-
注:边集可以为空
-
-
图的其他相关定义
-
无向边、无向图、有向边、有向图:
-

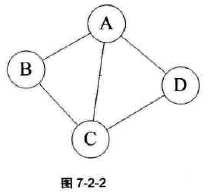

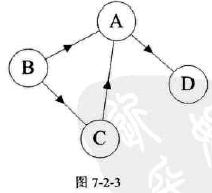

-
简单图:
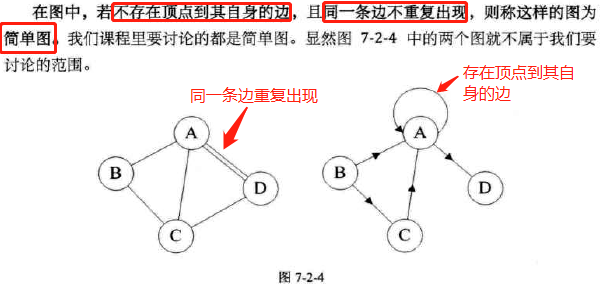
-
无向完全图、有向完全图


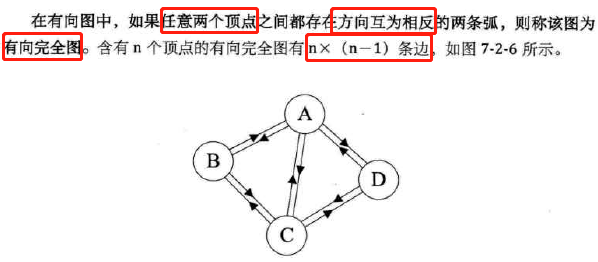

-
稀疏图和稠密图
-
权、网
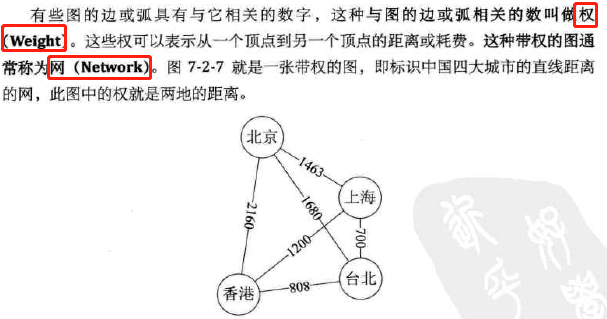
-
子图
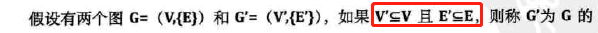
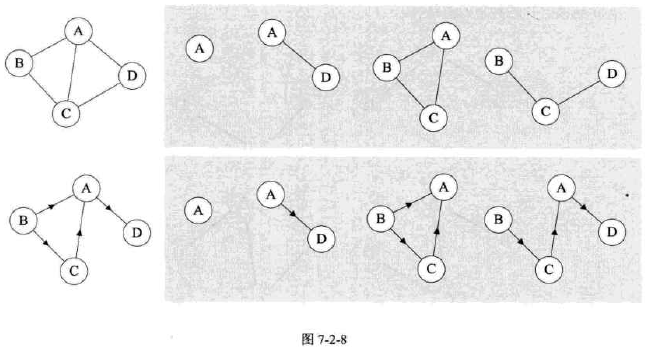
-
图的顶点与边间的关系
-
相邻接、相关联、顶点的度
-

-
邻接到邻接自、相关联、顶点的入度出度

-
顶点到顶点的路径
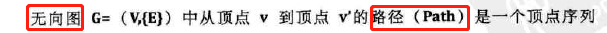
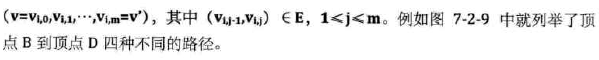
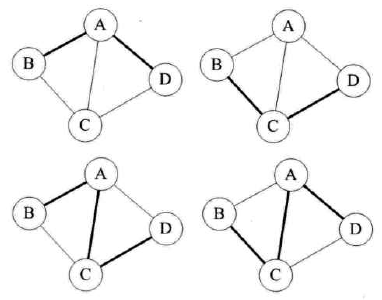
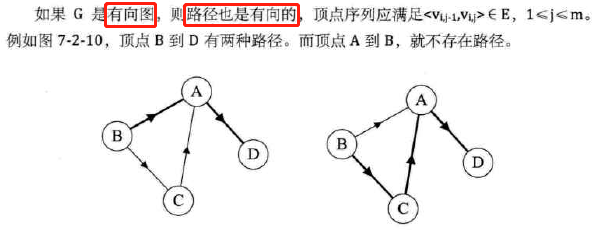
-
路径的长度
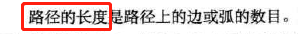
-
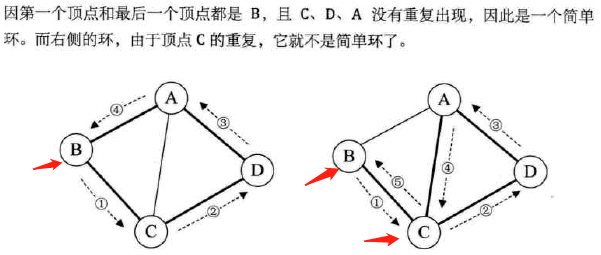
回路或环、简单路径、简单回路或简单环

-
连通图相关术语
-
连通图
-

(注意:连通指的是有路径即可,不一定要直接存在边)
-
连通分量


-
强连通图、强连通分量

-
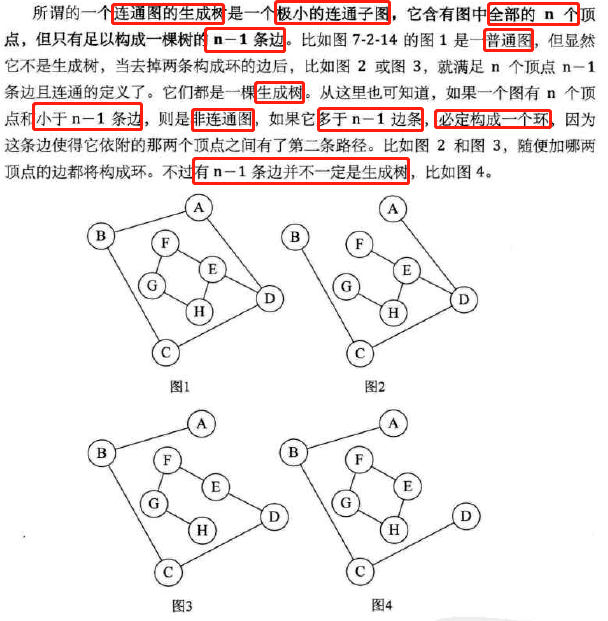
连通图的生成树
-
有向树、有向图的生成森林

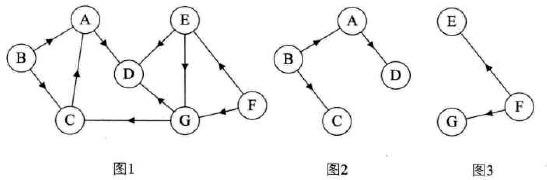
-
图的定义与术语总结

========================================
7.3 图的抽象数据类型

========================================
7.4 图的存储结构
-
引入:
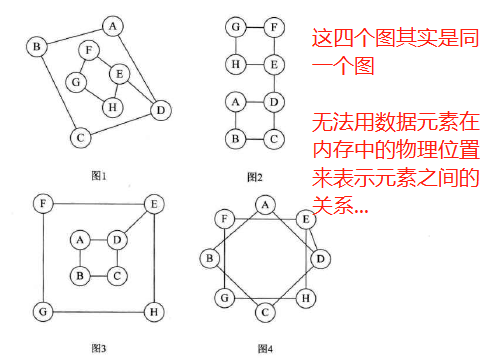
-
为此,前辈们提供了五种不同的存储结构
-
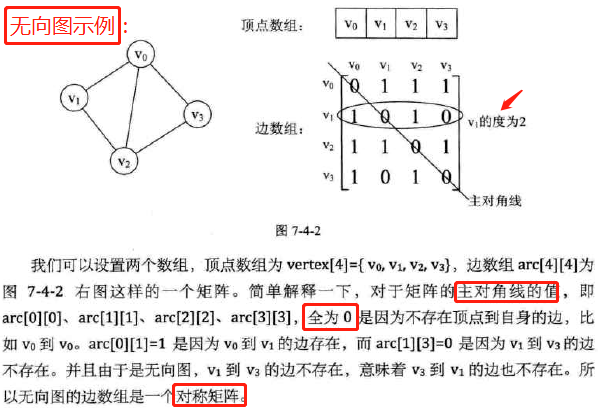
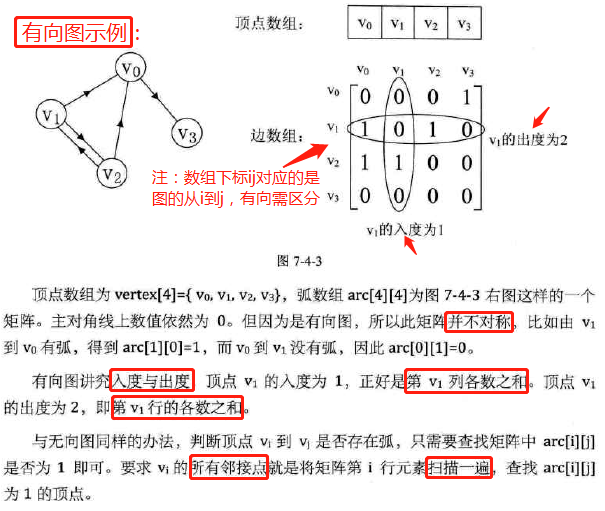
邻接矩阵
-
定义:
-

-
图示:无向图、有向图、网


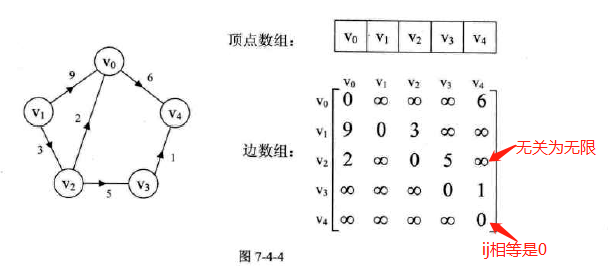
-
代码实现
图的邻接矩阵存储的结构:

### 无向图代码实现:给顶点表和边表输入数据的过程



-
邻接表
-
同顺序存储结构预先分配内存所造成的空间浪费而引入链式存储,也可考虑链式
-
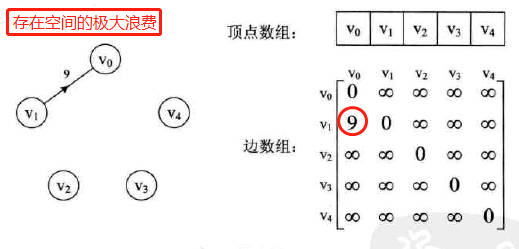
-
定义:数组与链表相结合的存储方法称为邻接表(Adjacency List)

-
图示:
无向图:

### 有向图:
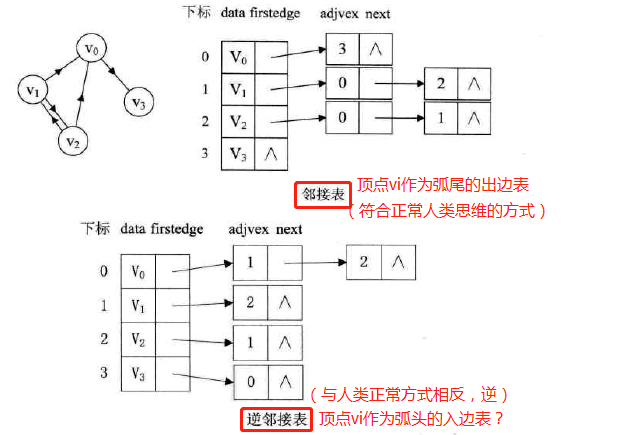
### 网:
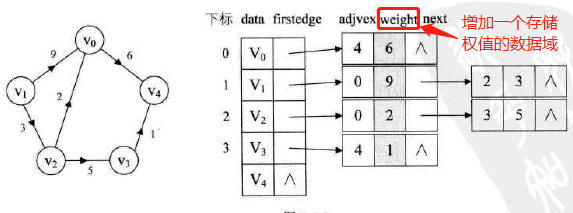
-
代码实现:
结构定义:
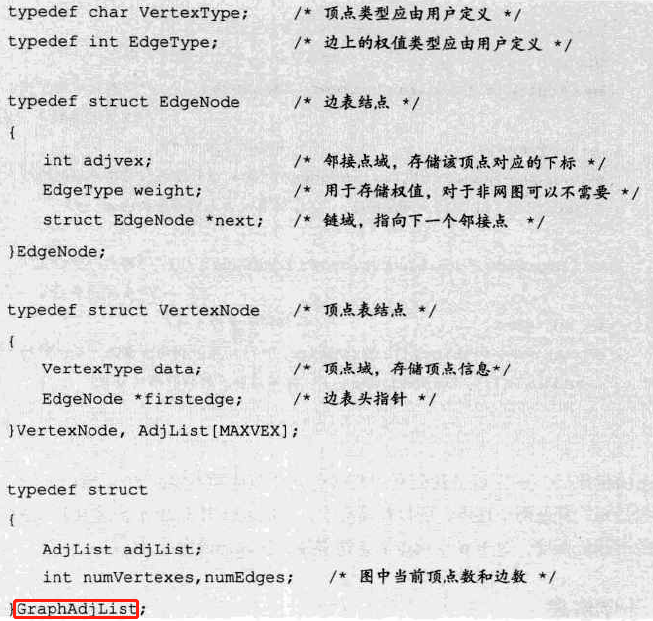
### 代码实现:



-
十字链表(针对有向图中邻接表的缺陷:入度需遍历问题)
-
定义:把邻接表与逆邻接表结合起来的有向图的一种存储方式,Orhtogonal List
-
重新定义顶点表的结点结构:
-
-


- ### 重新定义边表的结点结构


-
图示:(注:可以理解为左侧顶点表和右侧边表没啥必然关系,只是那样摆放了)
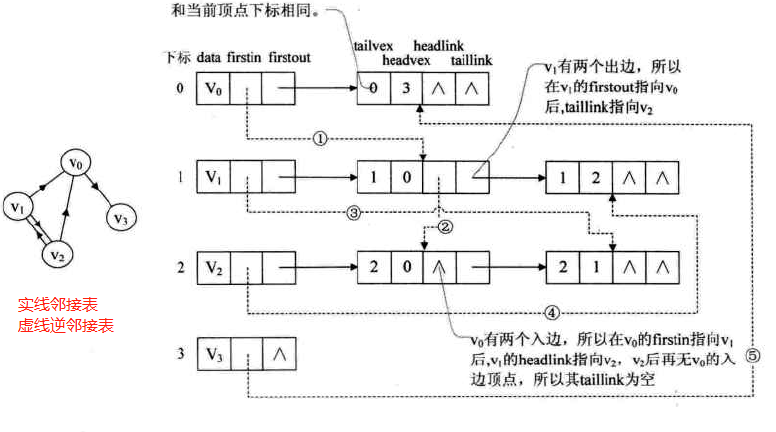


-
复杂度分析:

-
邻接多重表(针对无向图中邻接表的缺陷:删除边需遍历问题)
-
定义:(自己编的.....)针对邻接表在无向图中的缺陷,仿照十字链表进行改进
-
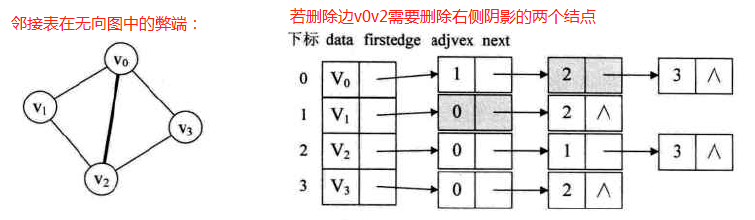
-
重新定义边表结构:


-
图示:
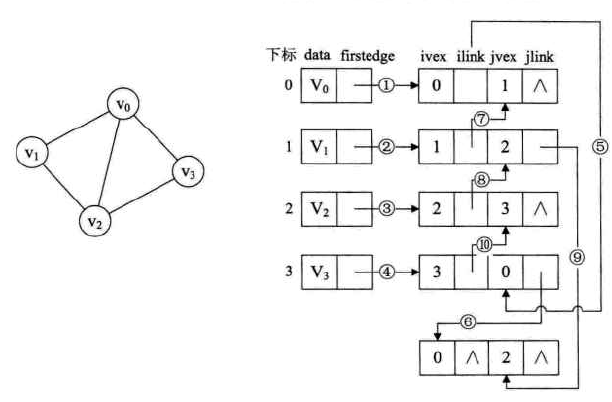


-
优势:

-
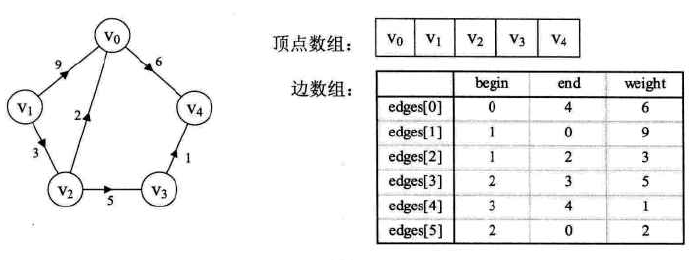
边集数组
-
定义:
-

-
定义边数组结构:


-
图示:
========================================
7.5 图的遍历
-
图的遍历的定义
-
图的遍历(Traversing Graph):
从图中某一顶点出发访遍其余顶点,且使每一个顶点仅被访问一次,这一过程就叫做图的遍历。
-
避免重复访问多次的思路:
设置一个访问数组visited[n],n是图中顶点的个数,初值0,访问后设为1。
-
-
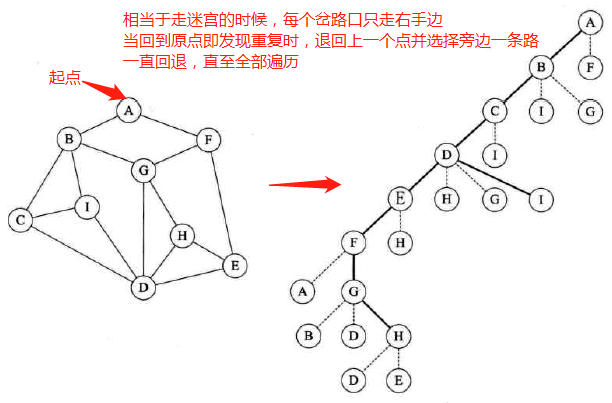
深度优先遍历
-
定义:
深度优先遍历(Depth_First_Search),也称深度优先搜索,简称DFS
对于连通图:从图中某个顶点v出发,访问此顶点,然后从v的未被访问的邻接点出发深度优先遍历图,直至图中所有和v有路径相通的顶点都被访问到。
对于非连通图:对它的连通分量分别进行深度优先遍历,即在先前一个顶点进行一次深度优先遍历后,若有尚未访问到的顶点,则另选图中一个未曾被访问的顶点作为起始点,重复,直至所有顶点被访问。
-
图示:类似一棵树的前序遍历
-
-
代码实现:邻接矩阵和邻接表



(邻接表与邻接矩阵代码几乎相同,只是将数组换成了链表)
-
复杂度分析:

-
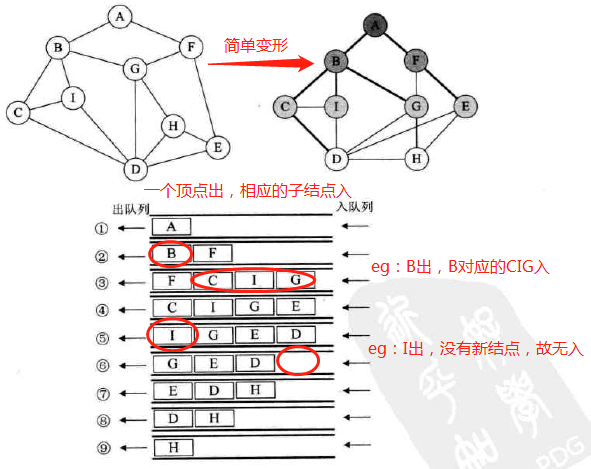
广度优先遍历
-
定义:
广度优先遍历(Breadth_First_Search),又称广度优先搜索,简称BFS
-
图示:类似树的层序遍历
-
-
代码实现:邻接矩阵和邻接表(数组和指针)


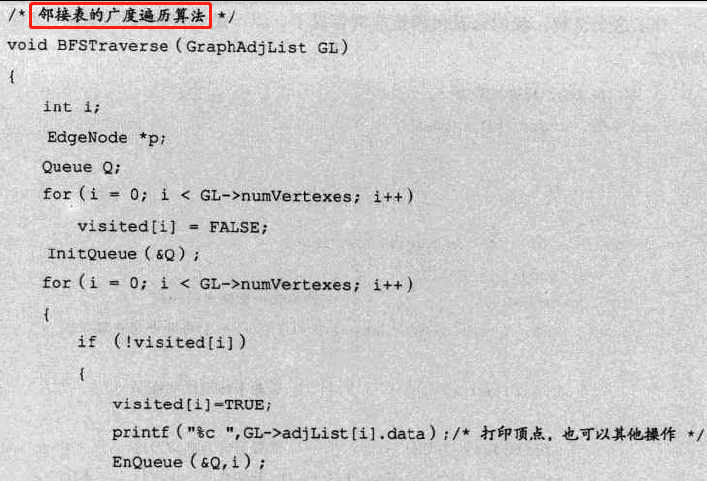

-
深度和广度的复杂度分析:
-
深度优先和广度优先在时间复杂度上是一样的,不同在于对顶点访问的顺序不同
-
两者在全图遍历上没有优劣之分,视不同情况进行选择
-
深度:适合目标明确,以找到目标为主要目的的情况
-
广度:更适合在不断扩大遍历范围时找到相对最优解的情况
-
========================================
7.6 最小生成树
-
定义和分类
-
最小生成树(Mimimum Cost Spanning Tree):构造连通网的最小代价生成树称为最小生成树
-
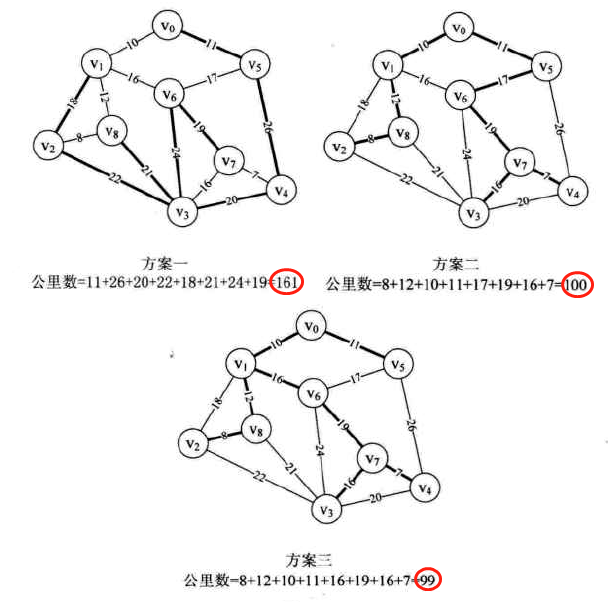
-
找连通网的最小生成树,经典的有两种算法:
-
普里姆算法(Prim)
-
克鲁斯卡尔算法(Kruskal)
-
-
注意:是“树”!!!!!
-
普里姆算法
-
方法:
-

-
理解:
其实就是从任一顶点开始,不断遍历剩余每个顶点与已扫描顶点构成的边并从中取最小权值边保存,然后将最小边对应的新顶点加入已扫描顶点。不断重复以上过程,直到扫描所有顶点为止。这样做,可以找到连接所有顶点的最小权值边。
-
图示:先构造邻接矩阵,后进行遍历等操作
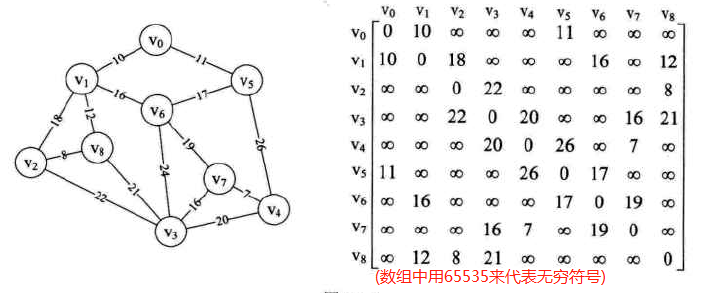
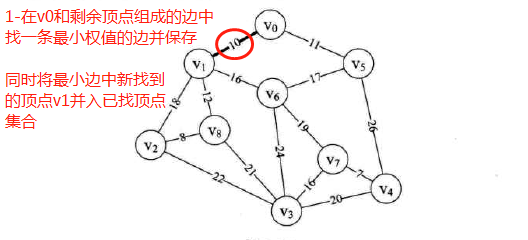
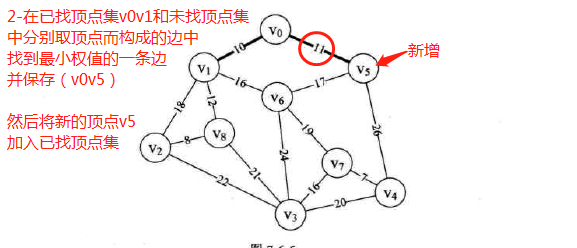
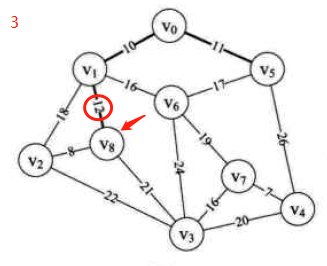
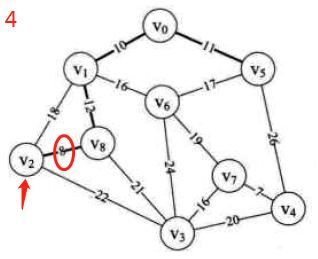
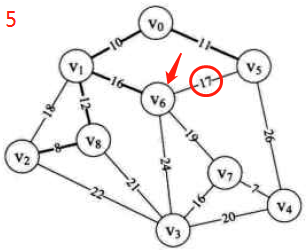
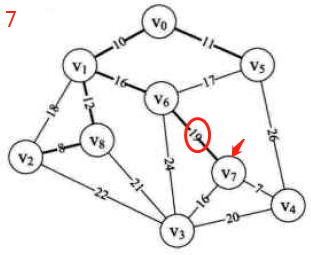
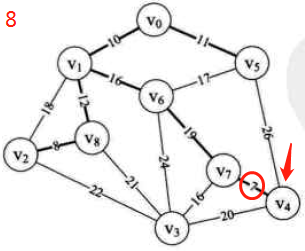
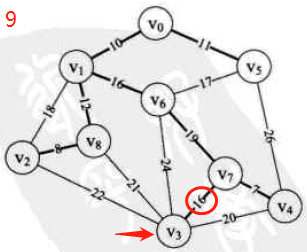
-
代码:(原理懂了,代码没太懂...)




-
代码分析:

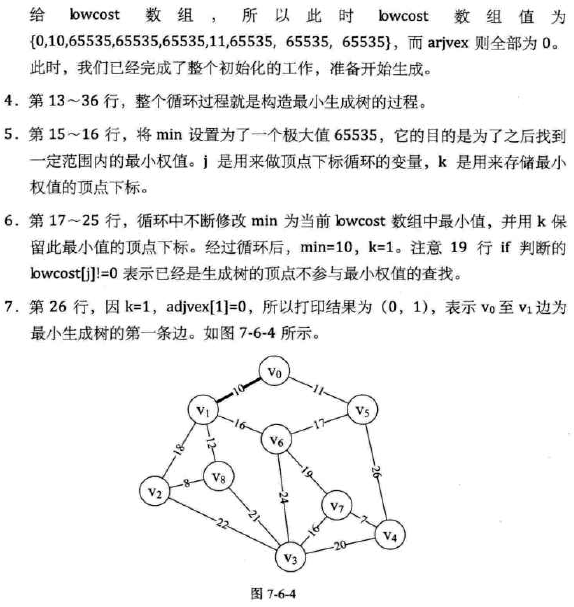

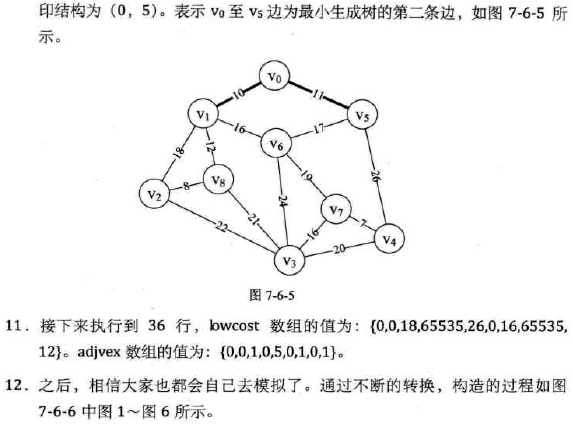

-
复杂度分析:
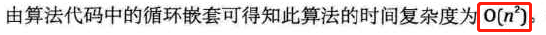
-
克鲁斯卡尔算法与边集数组
-
边集数组的结构定义:
-

-
边集数组图示:
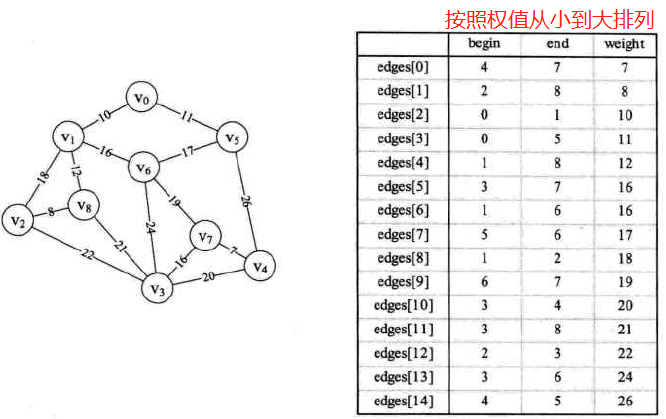
-
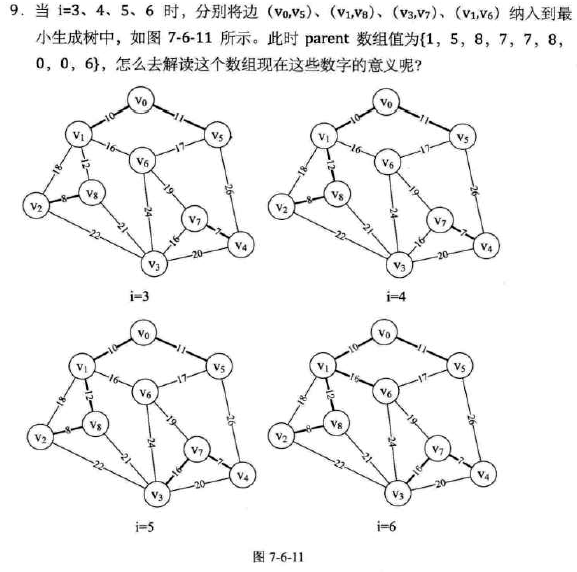
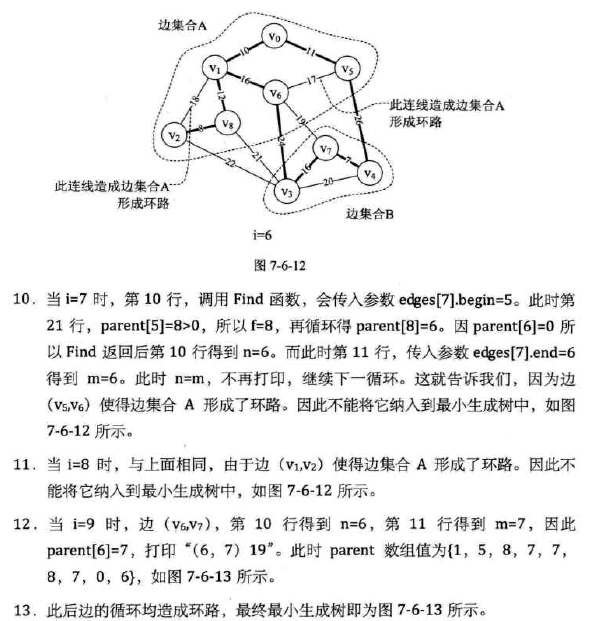
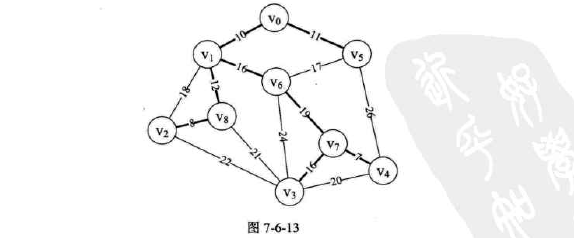
方法:(构建时要考虑是否会形成环路)

-
理解:
没仔细理解,脑壳疼,先直接贴图往下走了。
大概就是从边出发,按权值从小到大进行遍历,在不构成环的情况下取最小(因为是树),仔细实在看不进去,进度已经停滞好久,果断跳过。
-
代码:



-
代码分析:

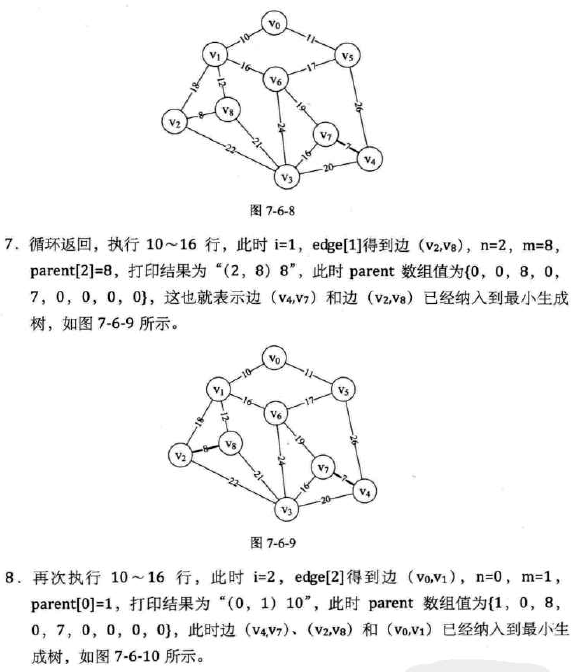
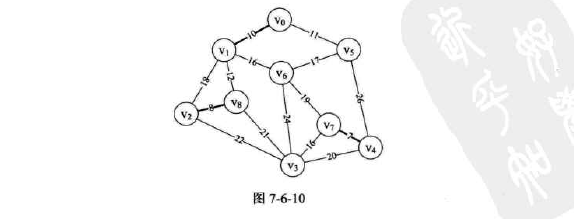

-
复杂度分析:

-
两种算法对比

========================================
7.7 最短路径
-
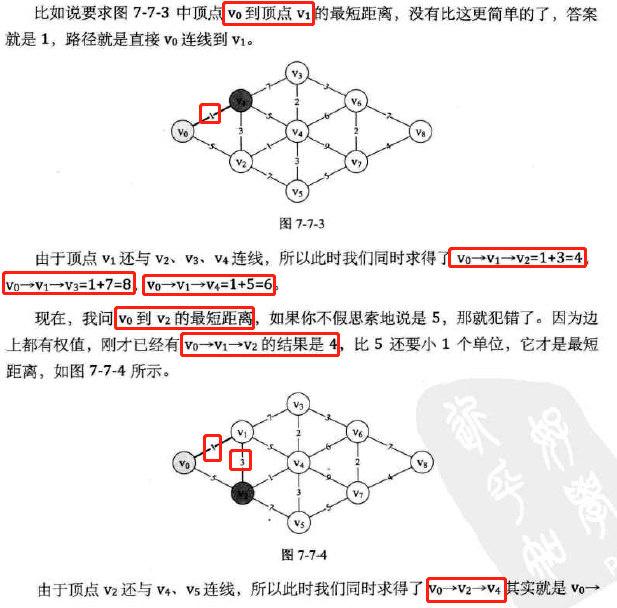
定义:
对于网图来说,最短路径是指两顶点之间经过的边上权值之和最少的路径
并且称路径上的第一个顶点是源点,最后一个顶点是终点。
非网图可以理解为所有边的权值都为1的网。
-
此处介绍两种求最短路径的算法
迪杰斯特拉(Dijkstra)算法 和 弗洛伊德(Floyd)算法
-
迪杰斯特拉(Dijkstra)算法
-
理解:
-
一个按路径长度递增的次序产生最短路径的算法。
-
基于已经求出的最短路径,求得更远顶点的最短路径,一步一步求出源点到终点的最短路径
-
-
图示:
-

-
代码:
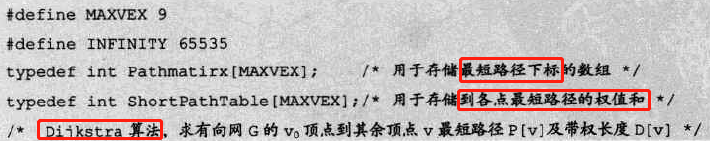



-
代码分析:
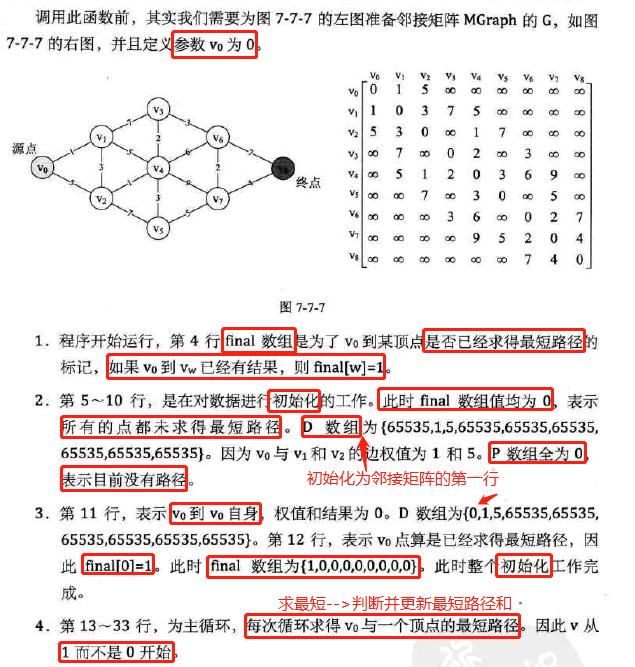

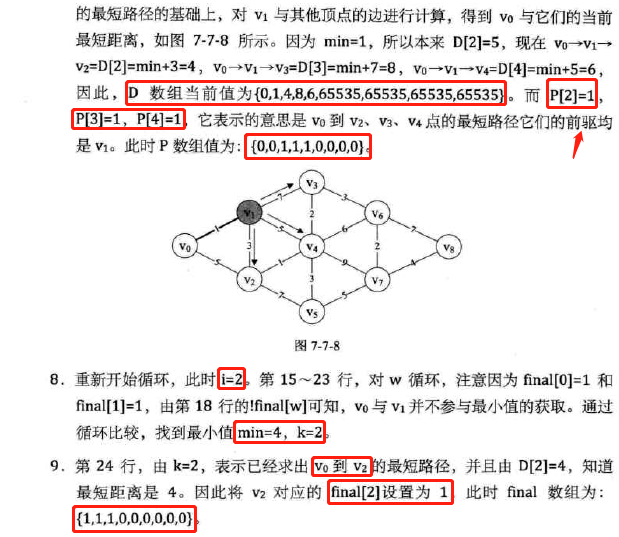
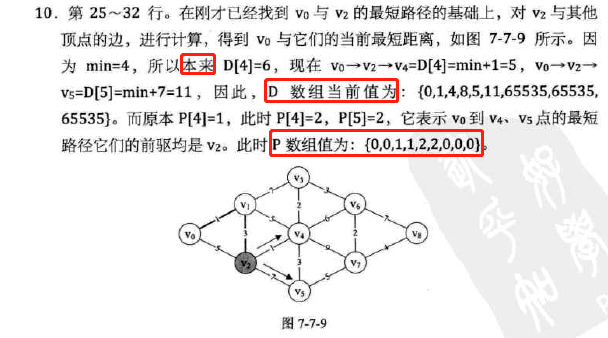
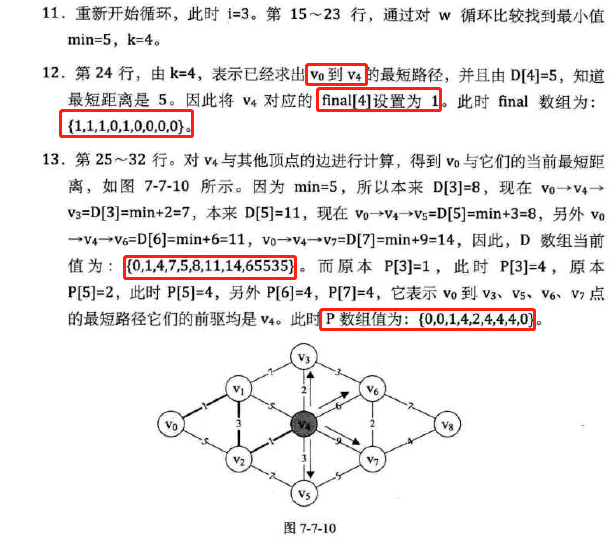

-
复杂度分析:
v0顶点到其他:O(N^2)
其他顶点到别的顶点:再循环一次,变为O(N^3)
-
弗洛伊德(Floyd)算法
-
算法:求所有顶点到所有顶点的最短路径-小例子:
-


-
理解:
求所有顶点到所有顶点的最短,所以用到两个二维数组。思路是遍历中转结点,即某结点从vi中转到另一结点的路径长度并与不中转时的路径长度比较,如果中转更小就更新数组为中转方式。
-
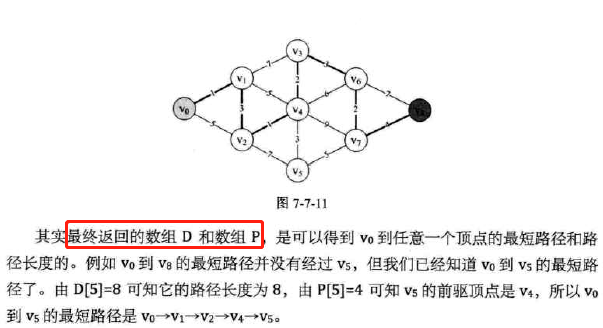
代码图示:

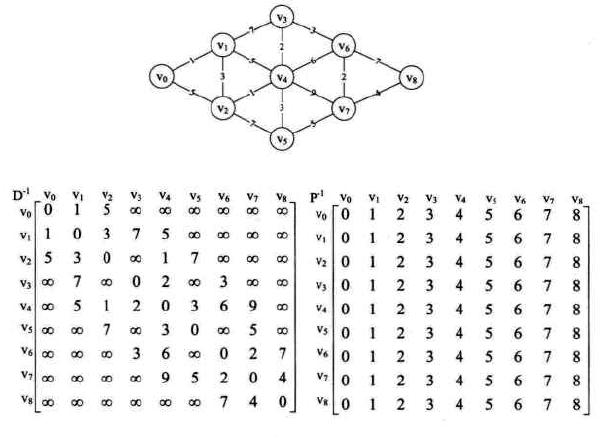
-
代码:二重循环初始化+三重循环权值修正
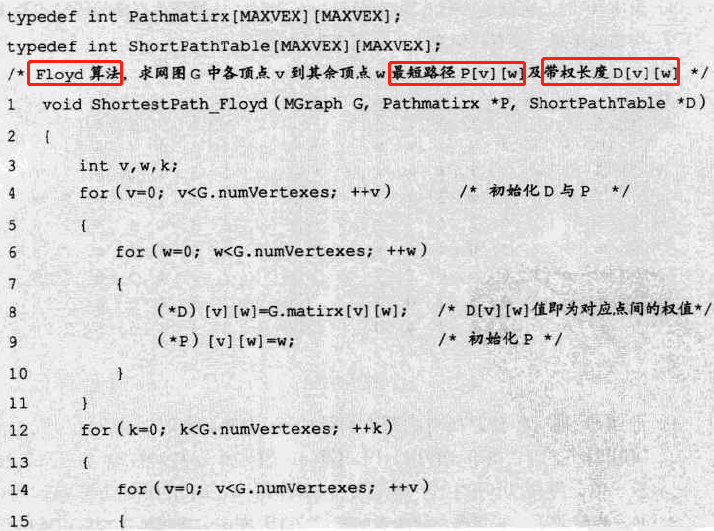


-
代码分析:
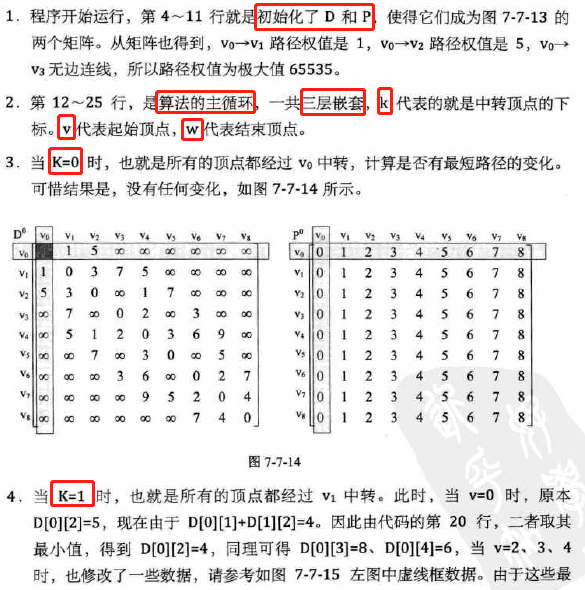
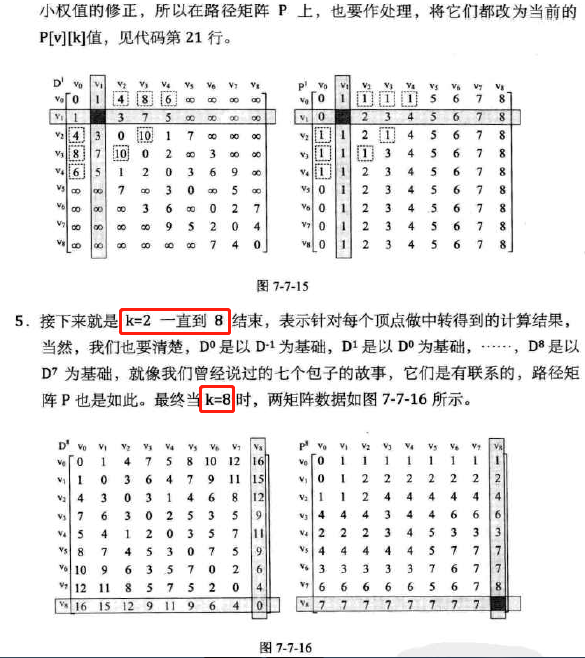

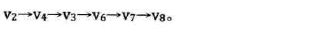
-
复杂度分析:O(N^3)-三重循环
-
适用:求所有顶点到所有顶点的最短路径问题
========================================
7.8 拓扑排序
-
AOV网-有向图的顶点表示活动的网

-
拓扑序列

-
拓扑排序:解决一个工程能否顺利进行的问题

-
拓扑排序算法
-
基本思路:
-

-
数据结构选取:需要删除结点,用邻接表
注:求最小生成树和最短路径用了邻接矩阵。
-
顶点表的结点结构定义:

-
图示:
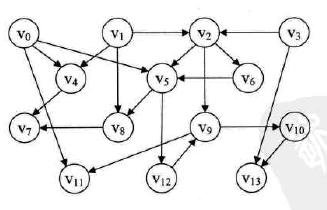
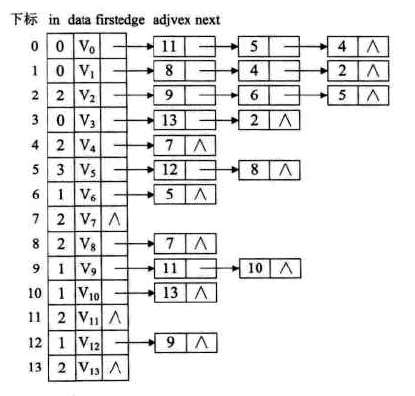
-
拓扑排序的结构代码

-
辅助数据结构:栈
-
用来存储处理过程中入度为0的顶点
-
目的是避免每个查找时都要去遍历顶点表找有没有入度为0的顶点
-
-
代码


-
代码分析


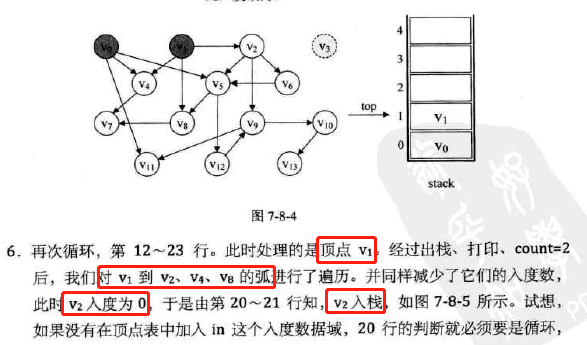
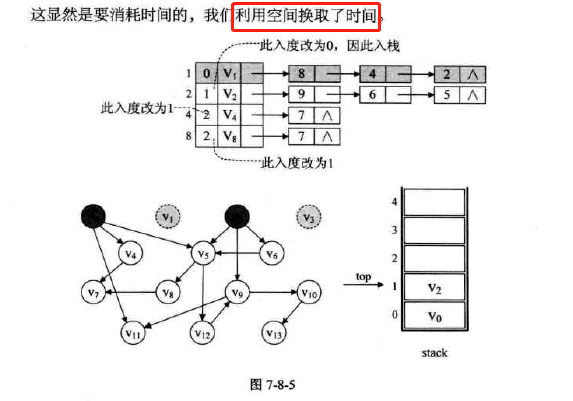
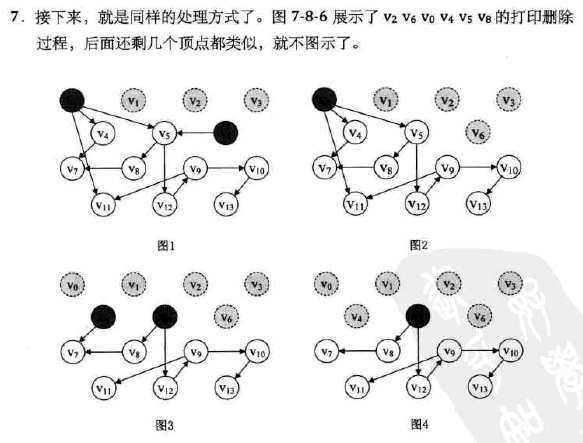
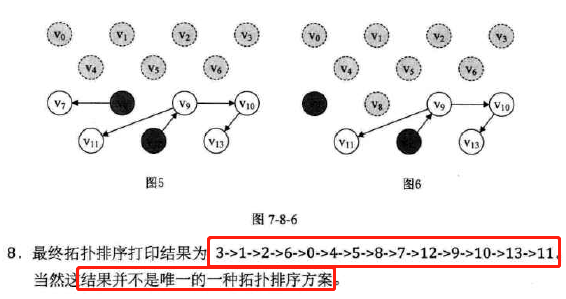
-
复杂度分析

========================================
7.9 关键路径
-
关键路径:解决工程完成需要的最短时间问题。

-
AOE网-有向图的边表示活动的网
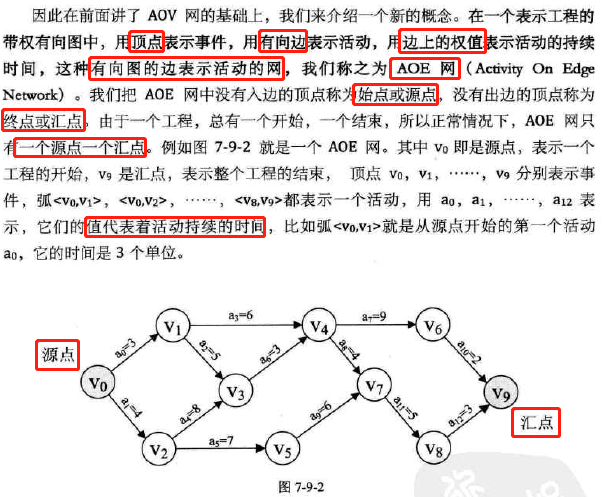
-
AOE网和AOV网的对比
-
AOV网:顶点表示活动的网,只描述活动之间的制约关系
-
AOE网:用边表示活动的网,边上的权值表示活动持续的时间
-
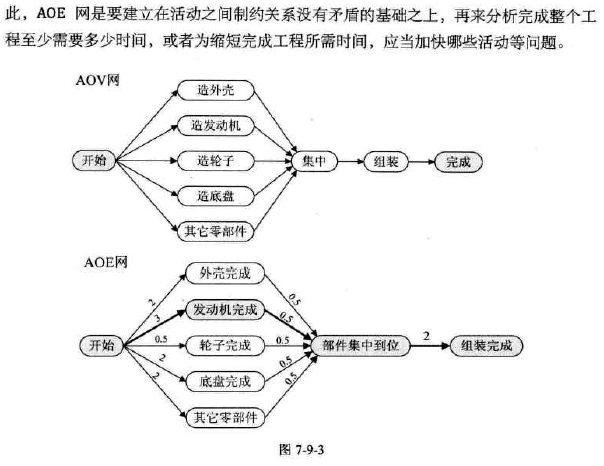
-
路径长度,关键路径,关键活动



-
定义几个参数


-
图示

-
准备
-
求最早发生时间etv的过程,就是从头至尾找拓扑序列的过程
-
因此在求关键路径前,需要先调用一次拓扑序列算法来计算etv和拓扑序列列表
-
-
改进的求拓扑序列算法
-
代码
-




-
代码分析

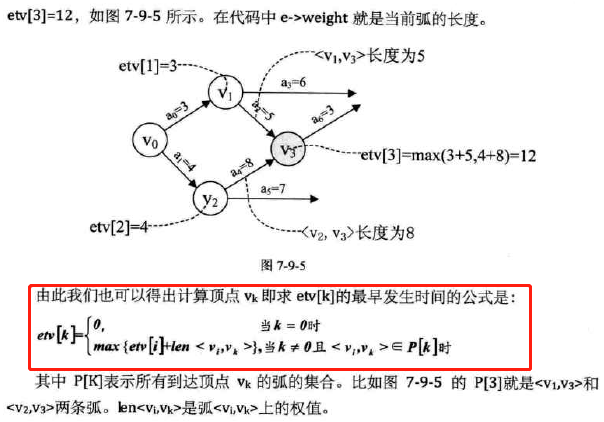
-
关键路径算法代码


-
关键路径算法代码分析
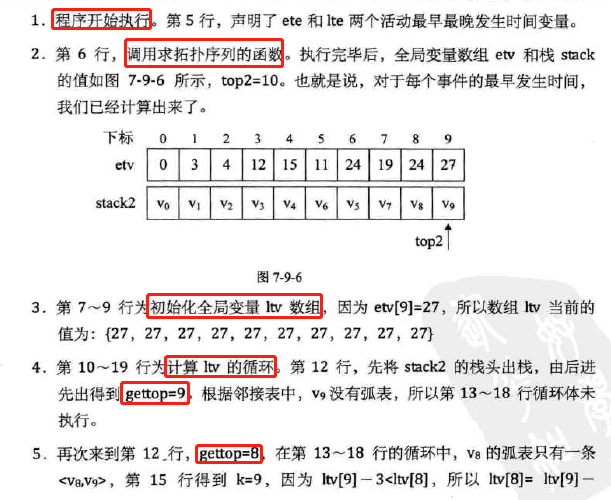
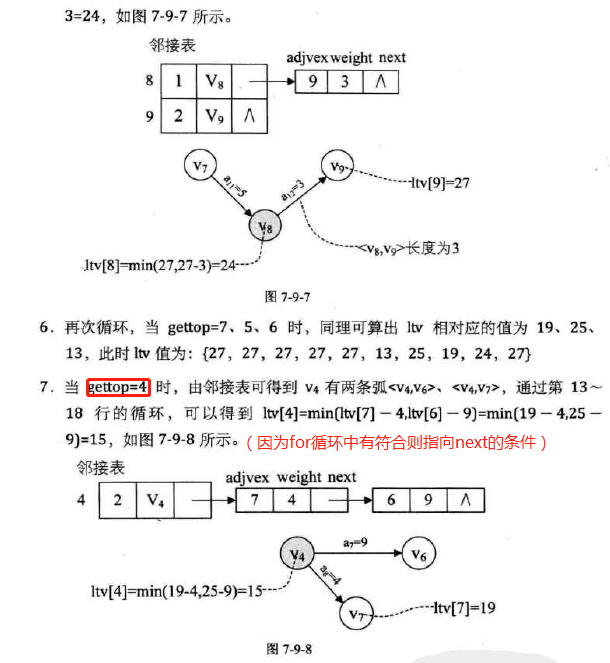

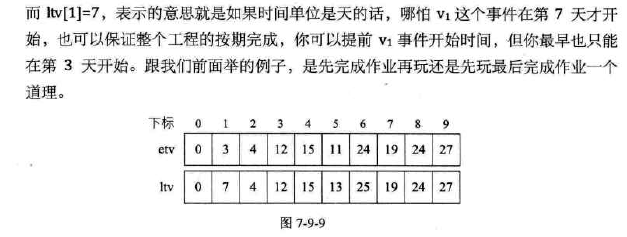

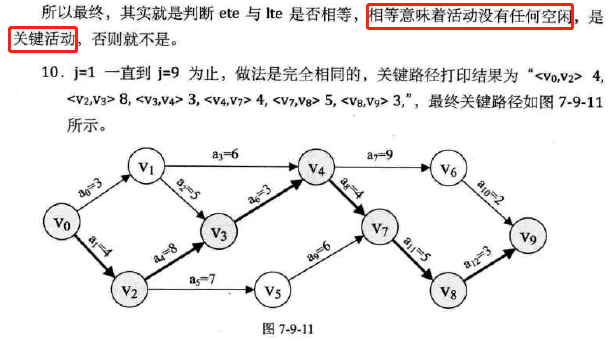
-
关键路径算法的复杂度分析

-
多条关键路径时缩短工期

========================================
7.10 总结回顾
-
图的存储结构:

-
图的遍历:深度、广度
-
图的应用:
-
最小生成树:普里姆、克鲁斯卡尔
-
最短路径:迪杰斯特拉、弗洛伊德
-
有向无环图的应用:拓扑排序、关键路径算法
-
========================================