该图描述了整个数据库的所有结构; 描述了一个T-SQl执行的时候发生的全过程
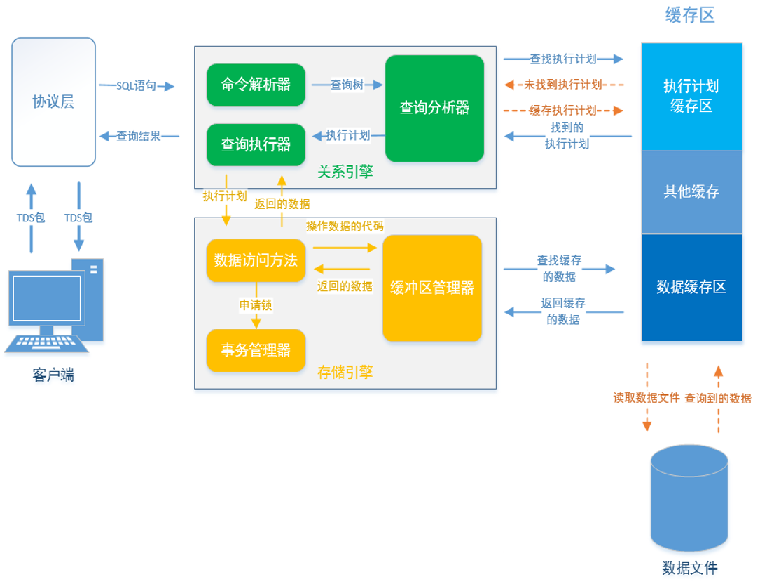
1.客户端
2.协议
3.关系引擎
4.存储引擎(硬盘)
5.缓存区
执行T-SQL的流程
数据库是独立的应用程序,所以客户端和数据库之间肯定需要一层协议,约定以什么样的数据进行交流 ,所以客户端在执行T-SQL的时候会以TDS格式的包,包含在协议层里到关系引擎中,在这里的查询分析器会到缓存区查找执行计划,如果有缓存的则直接用这个执行计划到存储引擎中,否则查询分析器自己生成执行计划(查询优化器还会选择资源占用最小的执行计划),调用数据访问方法,如果同时有多个事务来访问同一个资源的 话,数据访问方法也会向事务管理器申请锁,数据访问方法执行的时候会先到缓冲区管理器来查找数据,有数据的话直接返回,没有的话缓冲区管理器就到数据缓冲区中查找,如果缓冲区也没有,那就到数据库文件中查找数据,可能是全表扫描,也可能是根据索引查找,找到数据之后原路返回到客户端
执行计划缓存方式
(1)存储过程
当存储过程执行一次后,可以将语句缓存,不用像普通sql走遍整个流程
(2)参数化查询
因为使用参数化查询,不仅仅能够防止sql注入,还能够复用执行计划,可以在执行计划缓冲区中找到,不用查询分析器再次生成。
比如下面这种,这样的话查询优化器也能对它做优化:
declare @id int set @id=1 select * from [dbo].[Company] where CreatorId =@id
数据库存储

数据库在存储数据的时候会有生成多个数据页,数据页不是连续摆放的,但是数据页中的数据是连续摆放的,而且数据页的可存储最大空间为8096字节,并且数据不能跨页存储。
8kb/896bit/page 任何一条数据不能跨页存储:数据长度不能超过8096,char varchar max就是8096
文本/图像页
但是对于text这种超过8096字节的可以放到文本/图像页中保存,在数据页中存储的是具体内容在文本/图像页的位置

扩展:每8个数据页(64k)的组合形成扩展区(Extent),简称扩展,也叫盘区。扩展是SQL Server默认的存储分配单位。
堆:全部数据页的组合形成堆(Heap)。
所以尽量不要使用text类型,有的开发项目中甚至在数据库表中存储了图像的base64编码,存储这个的肯定必须要用text类型,这会导致性能变差,尽量不要这样,最好存个图像/文件的地址路径就可以。
数据库存储—管理数据页
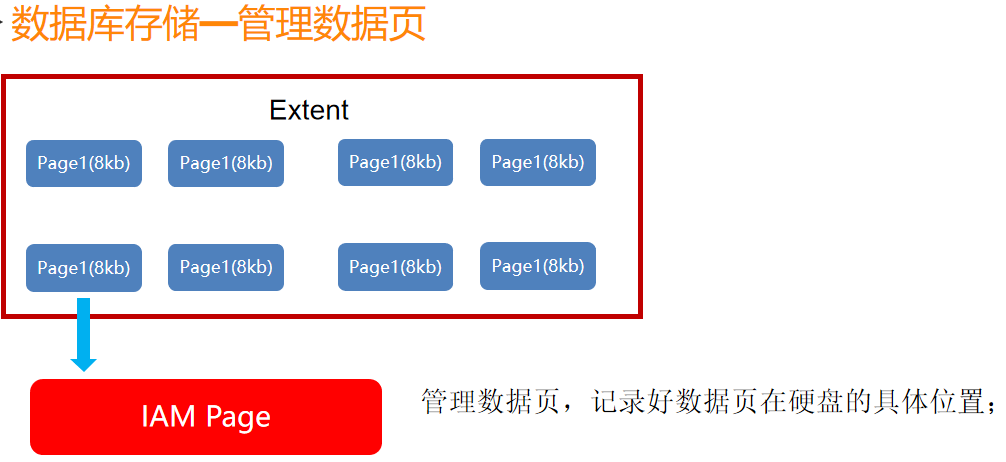
因为数据页是存储在硬盘中的,所以用管理数据页来专门管理数据页的位置的,就跟书籍菜单一个道理。
索引页
(1)索引页里记录的是数据和位置;
(2)索引是一个独立的,重复的存储。
(3)索引体积小,扫描快
没有索引的话,查数据的时候是全表扫描的,从硬盘里一个一个的网后找,但是使用索引的话,首先索引页体积很小,所以查找索引页很快,找到对应的索引话,又可以通过这个索引直接找到目标数据的位置,所以使用索引的效率会提高很多。

索引
索引是通过二叉树的数据结构来描述的,我们可以这么理解聚簇索引:索引的叶节点就是数据节点。而非聚簇索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块。
索引是通过二叉树的数据结构来描述的,聚集索引的二叉树上的节点就是数据节点,使用聚集索引的时候能够直接定位到对应数据页,在对应数据页中查找数据;非聚集索引的叶节点任然是叶节点,只不过这个叶节点中海油一个指针指向对应的数据块,多个通过指针寻找数据页的一步。
1.聚集索引(聚簇索引)
2.把数据有序的摆放,物理排序
4.一般是自增主键/创建时间/价格
5.因为数据物理排序,当然查询快!
适合: 范围查找;SqlServer自增int,默认聚集索引,所以查询不排序就是id排序 ,因为聚集索引都把相似数据放到一起并且排好序了,所以非常适合大于 小于 between 还有order by。
下面情况将不能使用索引
1. 索引不能运算,不能like‘% %’ 索引条件在前 可以Like %”, 使用模糊查询最好使用后置,前置会大大降低效率。
比如:
--不能运算,运算会使得索引失效 select * from [dbo].[Company] where Id+1>10
2.换聚集索引,很耗时,很多硬盘操作,生产环境要谨慎。而且删除一个聚集索引之后如果不再次新建聚集索引,还是会按照之前的顺序排列。
3.聚集索引只有一个,但是可以有多个字段,物理的排序规则按照排在第一列的字段,比如Id,Remark作为一个聚集索引,实际上表中的数据还是以Id为优先排序,比如:
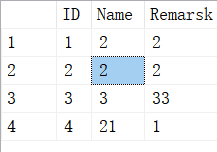
需要特别注意的是:聚集索引查询并不能具体定位到某一条记录,而是定位到数据页,即PageID。数据库会把所有的数据页都加载到内存中,在内存中的一个数据页中查找一条记录,这个是很快的,几乎可以忽略不记 。使用了聚集索引的列类似字典按照拼音字母查汉字,相似的放一起,只在相似数据范围内查,避免了全表扫描,所以快。
一种索引,该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同。 非聚簇索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块
用法:适合经常查询的字段,名称/账号 查询频繁
注意
1.非聚集索引不能运算,不能like'% %',索引条件在前,最好后置
唯一索引能够限制当前列的值是不重复的,而且允许存在null值,主键也是限制值唯一,不是允许null值存在。
建立索引的建议
1.主键是必须建立索引的(推荐数值主键(int),性能最高)
2.外键列也要索引
3.经常查询的建立索引
4.经常在where里面(经常作为查询条件的)
5. order by / group by /distinct
6.聚合运算/where条件时,先索引字段 如果使用int数据迁移频繁;考虑通过程序来生成int
不推荐建立索引
1.基本不怎么查询
2.重复值比较多的不要索引(sex/state)
3. text/image 不要索引
4.索引不要太多了
执行计划
提交的数据库查询优化器,经过分析生成多个数据库可以识别的高效执行查询方式。然后优化器会在众多执行计划中找出一个资源使用最少,而不是最快的执行方案,给你展示出来,可以是xml格式,文本格式,也可以是图形化的执行方案。
(1) Table Scan 全表扫描 性能最差 ---没有任何索引,包括聚集索引
sql:
SELECT * FROM [TEST].[dbo].[User]

可以看到没有任何索引的表 为Table Scan全表扫描
(2)Cluster Index Scan(聚集索引扫描) 性能最差,和上面性能差不多,同上 虽然有聚集索引,其实也是全表扫描 ;Cluster :美[ˈklʌstərd]
比如下面sql,没有加任何查询条件,但是设置了主键为聚集索引:
SELECT TOP 1000 [ID] ,[Name] ,[Remarsk] FROM [TEST].[dbo].[TEST]
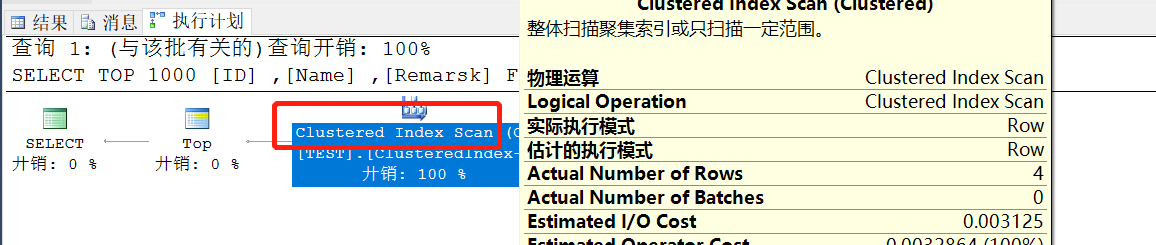
这是加了索引,但是没有用,没有使用任何查询条件,所以走的还是全表扫描
(3)Index Seek(非聚集索引查找) 性能非常高
下面OdID为非聚集索引:
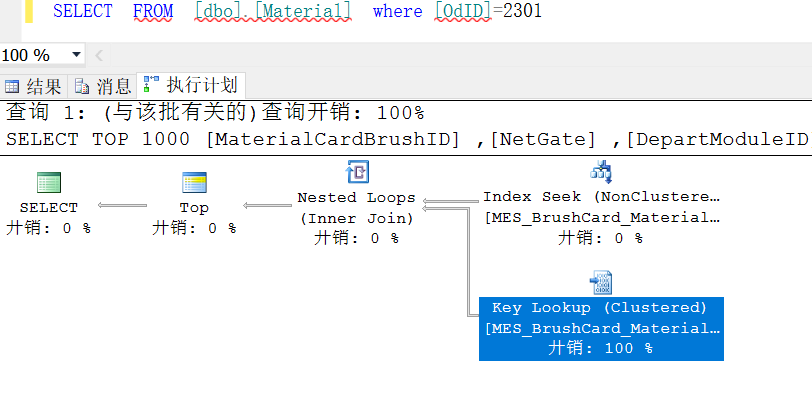
其中还存在Key Lookup(键值查找),这是因为当你查找的列没有完全被非聚集索引包含,就需要使用键值查找在聚集索引上查找非聚集索引不包含的列。
看sql:
SELECT [OdID] FROM [dbo].[Material] where [OdID]=2301
结果:
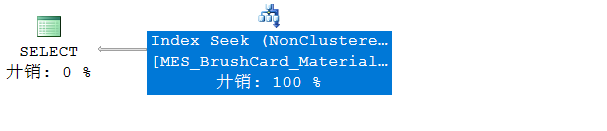
因为现在查找的列只有一个odid列,并且是非聚集索引列,所以只有Index Seek。
(4)Index Scan (非聚集索引扫描) 先索引,再扫描
可强制指定只用哪个索引 with(index= NonClusteredIndex),索引为多个的时候选择其中一个索引名称
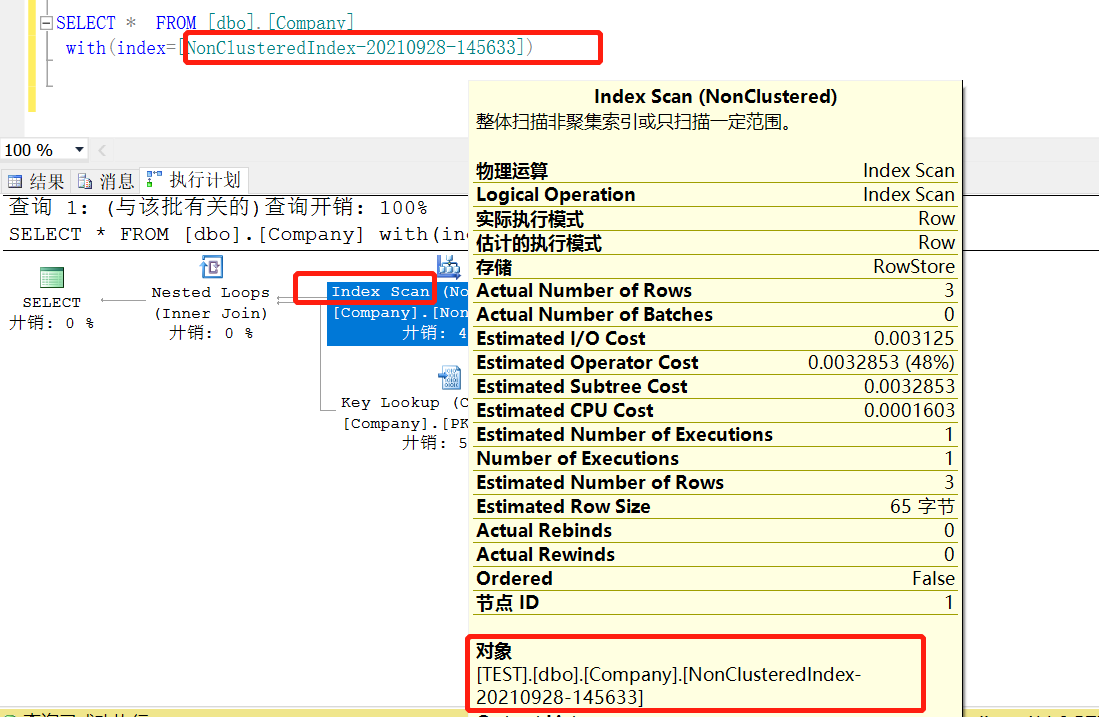
(5)Clustered Index Seek(聚集索引) 性能最高 数据库里有多个索引,我们可以强制指定数据库使用哪个索引
常规的优化建议
(1)尽量避免对列的计算
(2)In查询和or查询会使索引失效,如果非要用or这种,可以用union all代替or
(3)In 换exists
(4)not in 不要用,不走索引
(5)is null和is not null 都不走索引;尽量不要搞null ,索引会失效
(6)<> 也不走索引 ;可以拆分成> 和<
(7)join时,链接越少性能越高,因为join少了,数据库做的事情也少了。