spark streaming使用Kafka数据源进行数据处理,本文侧重讲述实践使用。
一、基于receiver的方式
在使用receiver的时候,如果receiver和partition分配不当,很容易造成数据倾斜,使个别executor工作繁重,拖累整体处理速度。
receiver线程分配和partition的关系:
假如topic A,分配了3个receiver,topic A有5个partition,一个receiver会对应一个线程,partition 0,1,2,3,4会这样分配
1. partition和receiver的分配计算
1.1.partition 5/receiver 3 = 1;
1.2.partition 5%receiver 3 = 2;
2. receiver分配到的partition
2.1.receiver 1,分配的partition编号为:0,1
2.2.receiver 2,分配的partition编号为:2,3
2.3.receiver 3,分配的partition编号为:4
⚠️由此可见,要想达到数据较均衡处理,设计好receiver线程数很重要,当然还要注意,每个topic消息处理的速度。
要想数据能更好的均衡处理,还要使每个executor分配的receiver线程数尽量均等。最好是receiver的总个数与executor的个数相同。不过在调度资源的时候,如果只是分配到一部分资源,那么等receiver分配好executor后,后期再申请到的资源,也不会有receiver重新分配。
JavaPairReceiverInputDStream<String,byte> messages =
KafkaUtils.createStream(
jssc,
String.class,byte.class,
kafka.serializer.DefaultDecoder.class,
kafka.serializer.DefaultDecoder.class,
kafkaParams,
topicMap,
StorageLevel.MEMORY_AND_DISK());参数解析:
1.jssc:JavaStreamingContext
2.DStream的key类型
3.DStream的值类型
4.Kafka key 解析类型
5.Kafka value 解析类型
6.Kafka参数配置,map类型
1)zookeeper的配置信息kafkaParams.put("zookeeper.connect", "192.168.1.1:2181");
2)groupIDkafkaParams.put("group.id", "group");
3)超时设置kafkaParams.put("zookeeper.connection.timeout.ms", "1000");
7.topic信息为map类型,如:topicMap.put(ga,2),其中ga为topic名称,2 表示为这个topic创建的线程数
8.RDD存储级别
二、基于direct的方式
Note that the typecast to HasOffsetRanges will only succeed if it is done in the first method called on the directKafkaStream, not later down a chain of methods. You can use transform() instead of foreachRDD() as your first method call in order to access offsets, then call further Spark methods. However, be aware that the one-to-one mappingbetween RDD partition and Kafka partition does not remain after any methods that shuffle or repartition, e.g. reduceByKey() or window().
需要注意的是:spark.streaming.kafka.maxRatePerPartition它是配置每个topic所有partition的最大速率,就是说不分topic,所有的消费的partition的最大速率都是一样。在有消息延迟时,我们需要设置这个参数,不然会一上来就冲很大的消息量,导致系统崩溃(这里重点讲述有延迟的处理)。
1.使用direct API可以保证每个topic的所有partition均衡的处理数据(如:topic A的所有partition的offset范围是相同的)。但需要注意的是,它会均衡每个topic的所有partition的offset范围,当有个别partition处理速度慢,它会重新均衡offset范围
2.在延迟消费时,当消费的topic的partition分区相同,但是生产速率不同,会导致消费的消息时间有很大差异
在资源分配不合理情况下:
如:topic A,topic B分别有30个partition,当分配的num-executor 3,executor-cores 5时,同时并行处理的task为15个(或分配cores总数为30),taskID小的那个topic会优先调度,由于spark的任务调度是默认是FIFO,会导致后面处理的topic时间延迟,进而下一批处理的offset偏移范围会相对调小,一直这样循环下去,会使后处理的topic消息量越来越少。
但当整体都有消息延迟,或突然降低处理量时(或sleep一段时间),两个topic的消息处理量达到一个很低的值后,当重新得到资源时,两个topic的offset范围会重新恢复到均衡的范围。
如图所示:

![]()
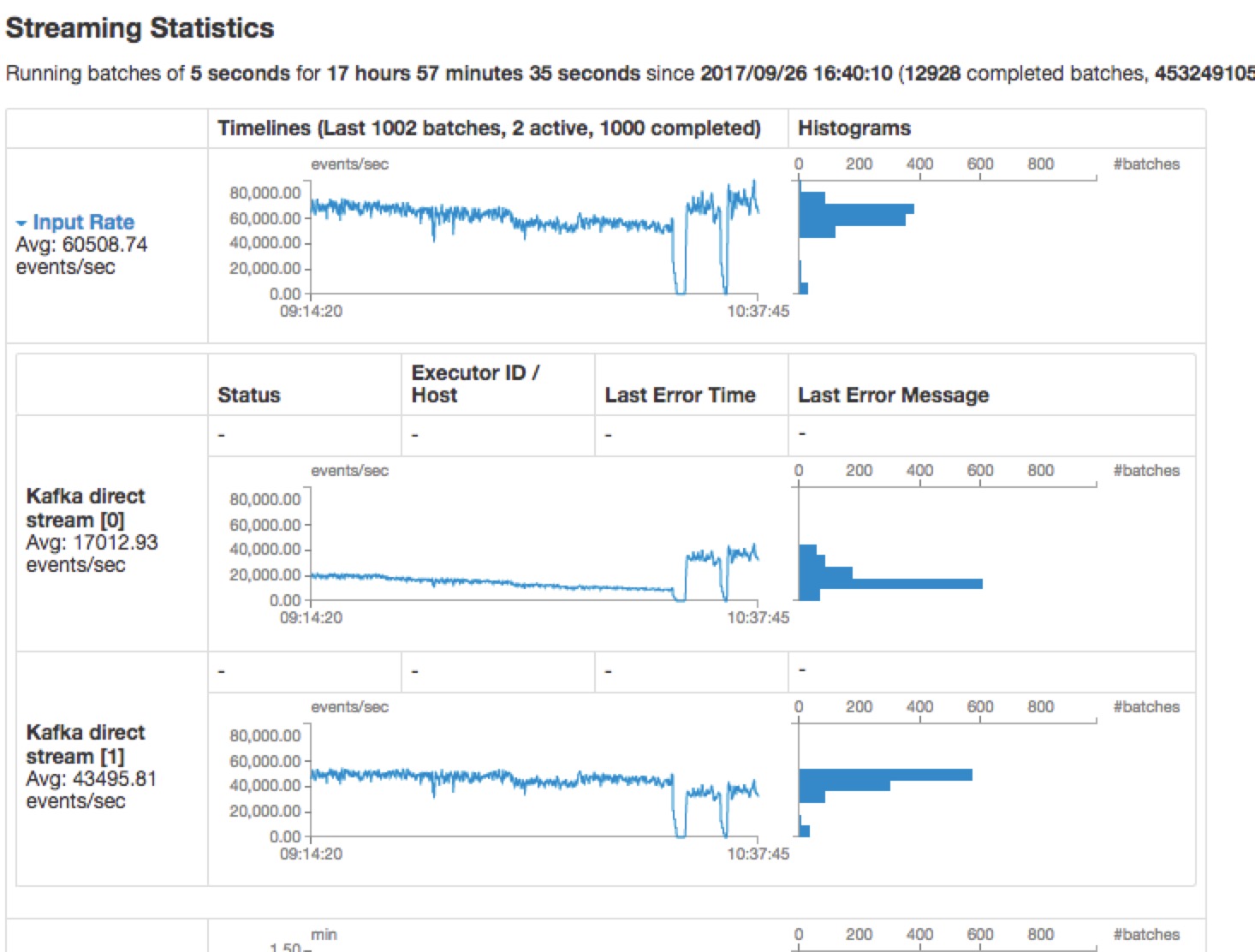
![]()
所以建议,在分配资源的时候,尽量不要被每个topic的partition个数整除,以免发生有的topic处理慢,导致消息处理量一直下降。(列表待整理:待验证)
创建directStream
JavaInputDStream<byte> message = KafkaUtils.createDirectStream(
jssc,
String.class,
byte.class,
StringDecoder.class,
DefaultDecoder.class,
byte.class,
kafkaParams,
fromOffsets,
new Function<MessageAndMetadata<String, byte>, byte>() {
@Override
public byte call(MessageAndMetadata<String, byte> v1) throws Exception {
return v1.message();
}
}
);
参数解析:
1.jssc:JavaStreamingContext
2.Kafka记录中的key的类型
3.Kafka记录中的value的类型
4.key解析类型
5.value解析类型
6.Dstream中的记录类型:定义的DStrem需要返回的类型
7.Kafka参数配置,map类型
1)broker配置信息kafkaParams.put("metadata.broker.list", "192.168.1.1:9092,192.168.1.2:9092");
2)groupIDkafkaParams.put("group.id", "group");
8.fromOffsets
9.messageHandler
从Kafka读取offset信息:
final static int TIMEOUT = 100000;
final static int BUFFERSIZE = 64 * 1024;
public static Map<TopicAndPartition, Long> getLastOffsetsOrEarlist(
String brokers,
List<String> topic,
String groupId,
boolean isLastOffset) {
Map<TopicAndPartition, Long> topicOffsets = new HashMap<TopicAndPartition, Long>();
Map<TopicAndPartition, Broker> topicBroker = findLeaders(brokers, topic);
for (Map.Entry<TopicAndPartition, Broker> tp : topicBroker.entrySet()) {
Broker leader = tp.getValue();
SimpleConsumer sim_consumer = new SimpleConsumer(
leader.host(),
leader.port(),
TIMEOUT, BUFFERSIZE, groupId);
long offset;
if (isLastOffset) {
offset = getLastOffset(sim_consumer, tp.getKey(), groupId);
} else {
offset = getEarliestOffset(sim_consumer, tp.getKey(), groupId);
}
topicOffsets.put(tp.getKey(), offset);
}
return topicOffsets;
}
1.getBrokerMap
private static Map<String, Integer> getBrokderMap(String brokers) {
Map<String, Integer> brokMap = new HashMap<>();
if (brokers != null) {
String brokList = brokers.split(",");
for (String b : brokList) {
String ip_port = b.split(":");
brokMap.put(ip_port[0], Integer.parseInt(ip_port[1]));
}
}
return brokMap;
}2.findleader
// 根据topic查找leader
public static Map<TopicAndPartition, Broker> findLeaders(String brokers, List<String> topic) {
Map<String, Integer> brokMap = getBrokderMap(brokers);
Map<TopicAndPartition, Broker> topicBroker = new HashMap<>();
String client_name = "client_" + topic.get(0) + "_" + System.currentTimeMillis();
for (String b : brokMap.keySet()) {
SimpleConsumer sim_consumer = null;
try {
sim_consumer = new SimpleConsumer(b, brokMap.get(b), TIMEOUT, BUFFERSIZE, client_name);
TopicMetadataRequest request = new TopicMetadataRequest(topic);
TopicMetadataResponse response = sim_consumer.send(request);
List<TopicMetadata> metadata = response.topicsMetadata();
for (TopicMetadata t : metadata) {
for (PartitionMetadata p : t.partitionsMetadata()) {
TopicAndPartition topicAndPartition = new TopicAndPartition(t.topic(), p.partitionId());
topicBroker.put(topicAndPartition, p.leader());
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (sim_consumer != null) {
sim_consumer.close();
}
}
}
return topicBroker;
}
3.getLasetOffset或getEarliestOffset
// 根据topicAndPartition得到offset值
private static Long getLastOffset(
SimpleConsumer consumer, TopicAndPartition tp, String clientName) {
Map<TopicAndPartition, PartitionOffsetRequestInfo> requestInfo = new HashMap<>();
requestInfo.put(tp, new PartitionOffsetRequestInfo(kafka.api.OffsetRequest.LatestTime(), 1));
OffsetRequest request = new OffsetRequest(requestInfo, kafka.api.OffsetRequest.CurrentVersion(), clientName);
OffsetResponse response = consumer.getOffsetsBefore(request);
if (response.hasError()) {
System.out.println("Error fetching data Offset Data the Broker. Reason: "
+ response.errorCode(tp.topic(), tp.partition()));
}
long offsets = response.offsets(tp.topic(), tp.partition());
return offsets[0];
}private static Long getEarliestOffset(
SimpleConsumer consumer,
TopicAndPartition tp,
String clientName) {
Map<TopicAndPartition, PartitionOffsetRequestInfo> requestInfo = new HashMap<>();
requestInfo.put(tp, new PartitionOffsetRequestInfo(kafka.api.OffsetRequest.EarliestTime(), 1));
OffsetRequest request = new OffsetRequest(requestInfo, kafka.api.OffsetRequest.CurrentVersion(), clientName);
OffsetResponse response = consumer.getOffsetsBefore(request);
if (response.hasError()) {
System.out.println("Error fetching data Offset Data the Broker. Reason: "
+ response.errorCode(tp.topic(), tp.partition()));
}
long offsets = response.offsets(tp.topic(), tp.partition());
return offsets[0];
}