线程:
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2021/9/5 21:41 # @Author : Lhtester # @Site : # @File : 豆瓣电影.py # @Software: PyCharm """使用串行爬虫爬豆瓣电影top 250""" #导入模块 import requests import time import random from lxml import etree from queue import Queue import threading class DouBanSpider: """爬虫类""" def __init__(self): self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36"} self.base_url = "https://movie.douban.com/top250" #声明队列 self.dataQueue = Queue() self.num = 1 def loadPage(self,url): '''向URL发起请求,获取响应内容''' #设置随机休眠 time.sleep(random.random()) return requests.get(url,headers=self.headers).content def parsePage(self,url): '''根据起始URL提取所有的URL''' #获取URL对应的响应内容 content = self.loadPage(url) #Xpath 处理得到的对应element对象 html = etree.HTML(content) #所有的电影节点 node_list = html.xpath("//div[@class='info']") #遍历 for node in node_list: #获取每部电影标题 title = node.xpath(".//span[@class='title']/text()")[0] #每部电影的评分 score = node.xpath(".//span[@class='rating_num']/text()")[0] #将数据存储到队列中 self.dataQueue.put(score+" "+title) #只有在第一个时获取所有URL组成的列表,其他页就不再获取 if url == self.base_url: return [self.base_url + link for link in html.xpath("//div[@class='paginator']/a/@href")] def startWork(self): """爬虫入口""" #第一个页面的请求,需要返回所有页面链接,并提取第一个的电影信息 link_list = self.parsePage(self.base_url) thread_list =[] #循环发送每个页面的请求,并获取所有的电影信息 for link in link_list: # self.parsePage(link) #循环创建了9个线程,每个线程都执行一个任务 thread = threading.Thread(target=self.parsePage,args=[link]) thread.start() thread_list.append(thread) #父线程等待所有子线程 结束,自己在结束 for thread in thread_list: thread.join() #循环get队列的数据,直到队列为空在退出 while not self.dataQueue.empty(): print(self.num) print(self.dataQueue.get()) self.num+=1 if __name__ == "__main__": #创建爬虫对象 spider =DouBanSpider() #开始时间 start_time = time.time() #开始爬虫 spider.startWork() #结束时间 stop_time = time.time() #result print(" [LOG]:%f secondes..."%(stop_time-start_time))
执行结果:
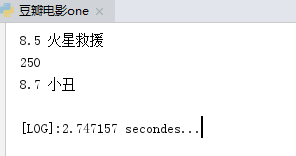
多进程:
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2021/9/5 21:41 # @Author : Lhtester # @Site : # @File : 豆瓣电影.py # @Software: PyCharm """使用串行爬虫爬豆瓣电影top 250""" #导入模块 import requests import time import random from lxml import etree import multiprocessing from multiprocessing import Queue class DouBanSpider: """爬虫类""" def __init__(self): self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36"} self.base_url = "https://movie.douban.com/top250" #声明队列 self.dataQueue = Queue() self.num = 1 def loadPage(self,url): '''向URL发起请求,获取响应内容''' #设置随机休眠 time.sleep(random.random()) return requests.get(url,headers=self.headers).content def parsePage(self,url): '''根据起始URL提取所有的URL''' #获取URL对应的响应内容 content = self.loadPage(url) #Xpath 处理得到的对应element对象 html = etree.HTML(content) #所有的电影节点 node_list = html.xpath("//div[@class='info']") #遍历 for node in node_list: #获取每部电影标题 title = node.xpath(".//span[@class='title']/text()")[0] #每部电影的评分 score = node.xpath(".//span[@class='rating_num']/text()")[0] #将数据存储到队列中 self.dataQueue.put(score+" "+title) #只有在第一个时获取所有URL组成的列表,其他页就不再获取 if url == self.base_url: return [self.base_url + link for link in html.xpath("//div[@class='paginator']/a/@href")] def startWork(self): """爬虫入口""" #第一个页面的请求,需要返回所有页面链接,并提取第一个的电影信息 link_list = self.parsePage(self.base_url) process_list =[] #循环发送每个页面的请求,并获取所有的电影信息 for link in link_list: # self.parsePage(link) #循环创建了9个进程,每个线程都执行一个任务 process = multiprocessing.Process(target=self.parsePage,args=[link]) process.start() process_list.append(process) #父线程等待所有子线程 结束,自己在结束 for process in process_list: process.join() #循环get队列的数据,直到队列为空在退出 while not self.dataQueue.empty(): print(self.num) print(self.dataQueue.get()) self.num+=1 if __name__ == "__main__": #创建爬虫对象 spider =DouBanSpider() #开始时间 start_time = time.time() #开始爬虫 spider.startWork() #结束时间 stop_time = time.time() #result print(" [LOG]:%f secondes..."%(stop_time-start_time))
结果:

注释:因本地服务器只有一个CPU,运行时间比单一进程执行多线程慢了3倍
协程:
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2021/9/5 21:41 # @Author : Lhtester # @Site : # @File : 豆瓣电影.py # @Software: PyCharm """使用串行爬虫爬豆瓣电影top 250""" #导入模块 import gevent from gevent import monkey #gevent 可以按同步的方式来写异步程序 #monkey.patch_all()会在python程序执行时动态地将网络库(socket,select,thread) #替换掉,变成异步的库,让程序可以以异步的方式处理网络相关的任务 monkey.patch_all() #为什么gevent、monkey、monkey.patch_all()要放在导入的最前面? import time import requests import random from lxml import etree from queue import Queue # import sys # sys.setrecursionlimit(10000) class DouBanSpider: """爬虫类""" def __init__(self): self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36"} self.base_url = "https://movie.douban.com/top250" #声明队列 self.dataQueue = Queue() self.num = 1 def loadPage(self,url): '''向URL发起请求,获取响应内容''' #设置随机休眠 time.sleep(random.random()) return requests.get(url,headers=self.headers).content def parsePage(self,url): '''根据起始URL提取所有的URL''' #获取URL对应的响应内容 content = self.loadPage(url) #Xpath 处理得到的对应element对象 html = etree.HTML(content) #所有的电影节点 node_list = html.xpath("//div[@class='info']") #遍历 for node in node_list: #获取每部电影标题 title = node.xpath(".//span[@class='title']/text()")[0] #每部电影的评分 score = node.xpath(".//span[@class='rating_num']/text()")[0] #将数据存储到队列中 self.dataQueue.put(score+" "+title) #只有在第一个时获取所有URL组成的列表,其他页就不再获取 if url == self.base_url: return [self.base_url + link for link in html.xpath("//div[@class='paginator']/a/@href")] def startWork(self): """爬虫入口""" #第一个页面的请求,需要返回所有页面链接,并提取第一个的电影信息 link_list = self.parsePage(self.base_url) #spawn创建协程任务,并加入任务队列中 jobs=[gevent.spawn(self.parsePage,link) for link in link_list] #父线程阻塞,等待所有任务结束后继续执行 gevent.joinall(jobs) #循环get队列的数据,直到队列为空在退出 while not self.dataQueue.empty(): print(self.num) print(self.dataQueue.get()) self.num+=1 if __name__ == "__main__": #创建爬虫对象 spider =DouBanSpider() #开始时间 start_time = time.time() #开始爬虫 spider.startWork() #结束时间 stop_time = time.time() #result print(" [LOG]:%f secondes..."%(stop_time-start_time))
结果:
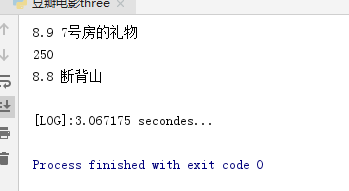
疑问:
#为什么gevent、monkey、monkey.patch_all()要放在导入的最前面?不然会报错: MonkeyPatchWarning: Monkey-patching ssl after ssl has already been imported may lead to errors