Flink中支持的BLOB文件类型
-
jar包
被user classloader使用的jar包 -
高负荷RPC消息
1. RPC消息长度超出了akka.framesize的大小 2. 在HA摸式中,利用底层分布式文件系统分发单个高负荷RPC消息,比如: TaskDeploymentDescriptor,给多个接受对象。 3. 失败导致重新部署过程中复用RPC消息 -
TaskManager的日志文件
为了在web ui上展示taskmanager的日志
按存储特性又分为两类
-
PERMANENT_BLOB
生命周期和job的生命周期一致,并且是可恢复的。会上传到BlobStore分布式文件系统中。 -
TRANSIENT_BLOB
生命周期由用户自行管理,并且是不可恢复的。不会上传到BlobStore分布式文件系统中。
架构图
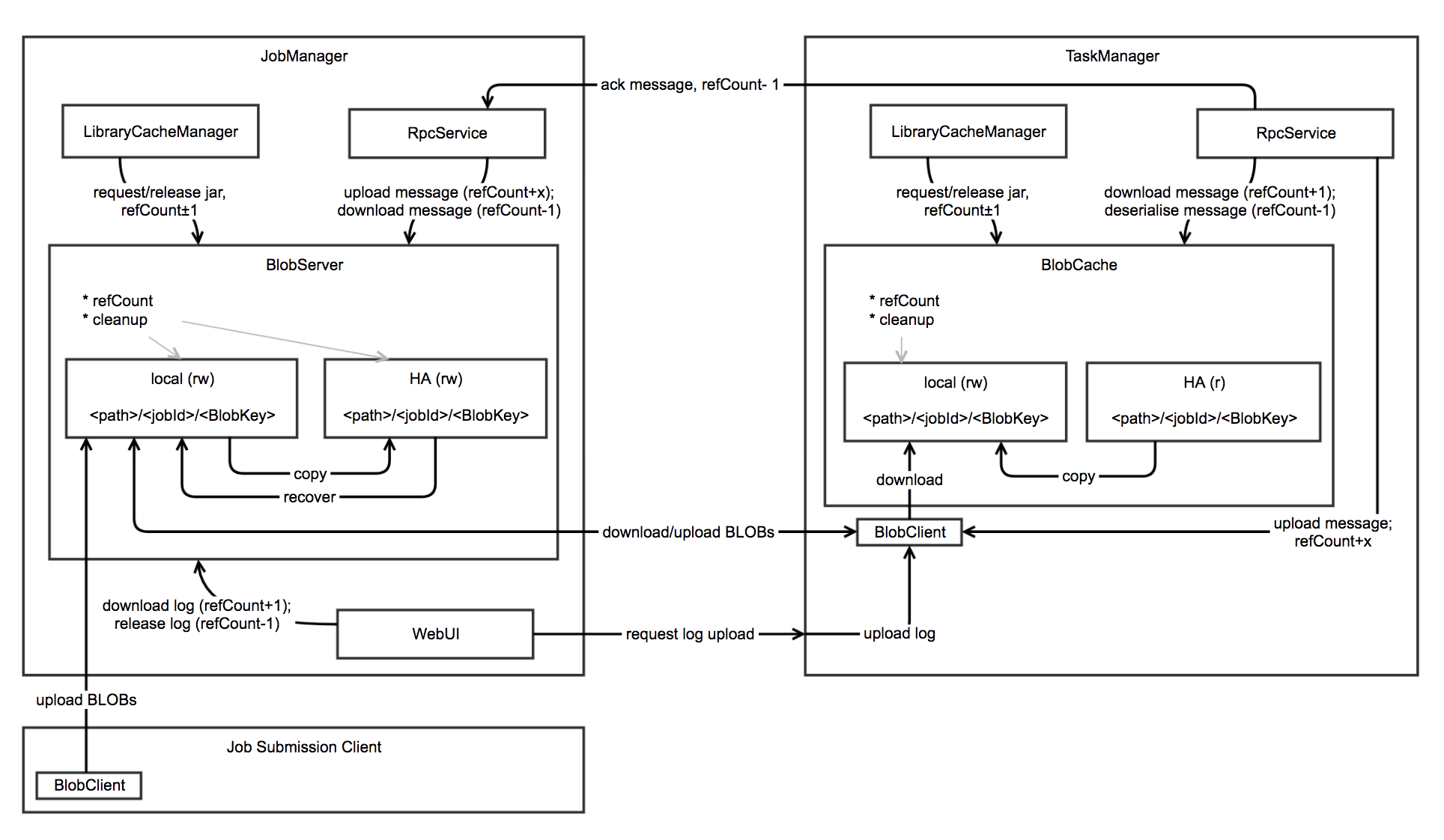
BlobStore
BLOB底层存储,支持多种实现`HDFS`,`S3`,`FTP`等,HA中使用BlobStore进行文件的恢复。
BlobServer
* 提供了基于jobId和BlobKey进行文件上传和下载的方法
* 本地文件系统的读写,基于`<path>/<jobId>/<BlobKey>`目录结构
* HA 分布式文件系统的读写,基于`<path>/<jobId>/<BlobKey>`目录结构
* 负责本地文件系统和分布式文件系统的清理工作
* 先存储到本地文件系统中,然后如果需要的话再存储到分布式文件系统中
* 下载请求优先使用本地文件系统中的文件
* 进行HA恢复中,下载分布式系统中的文件到本地文件系统中
BlobClient
* 基于jobId和BlobKey对BlobServer中的文件进行本地文件缓存
* 本地文件的读写,基于`<path>/<jobId>/<BlobKey>`目录结构
* 优先使用本地文件系统中的文件,然后尝试从HA分布式文件中获取,最后才尝试从BlobServer中下载
* 负责本地文件系统的清理工作
LibraryCacheManager
桥接task的classloader和缓存的库文件,其`registerJob`,`registerTask`会构建并缓存job,task运行需要的classloader
示例解析:standalone模式中的jar包管理
JobManager会创建BlobStore、BlobServer、BlobLibraryCacheManager具体过程见JobManager的createJobManagerComponents方法
try {
blobServer = new BlobServer(configuration, blobStore)
blobServer.start()
instanceManager = new InstanceManager()
scheduler = new FlinkScheduler(ExecutionContext.fromExecutor(futureExecutor))
libraryCacheManager =
new BlobLibraryCacheManager(
blobServer,
ResolveOrder.fromString(classLoaderResolveOrder),
alwaysParentFirstLoaderPatterns)
instanceManager.addInstanceListener(scheduler)
}
TaskManager注册到Jobmanager后会创建BlobCacheService、BlobLibraryCacheManager具体过程见TaskManager的associateWithJobManager方法
try {
val blobcache = new BlobCacheService(
address,
config.getConfiguration(),
highAvailabilityServices.createBlobStore())
blobCache = Option(blobcache)
libraryCacheManager = Some(
new BlobLibraryCacheManager(
blobcache.getPermanentBlobService,
config.getClassLoaderResolveOrder(),
config.getAlwaysParentFirstLoaderPatterns))
}
JobClient在向集群提交job的过程中会调用JobSubmissionClientActor的tryToSubmitJob方法进而调用JobGraph对象的uploadUserJars方法
try {
jobGraph.uploadUserJars(blobServerAddress, clientConfig);
} catch (IOException exception) {
getSelf().tell(
decorateMessage(new JobManagerMessages.JobResultFailure(
new SerializedThrowable(
new JobSubmissionException(
jobGraph.getJobID(),
"Could not upload the jar files to the job manager.",
exception)
)
)),
ActorRef.noSender());
return null;
}
LOG.info("Submit job to the job manager {}.", jobManager.path());
jobManager.tell(
decorateMessage(
new JobManagerMessages.SubmitJob(
jobGraph,
ListeningBehaviour.EXECUTION_RESULT_AND_STATE_CHANGES)),
getSelf());
public void uploadUserJars(
InetSocketAddress blobServerAddress,
Configuration blobClientConfig) throws IOException {
if (!userJars.isEmpty()) {
List<PermanentBlobKey> blobKeys = BlobClient.uploadJarFiles(
blobServerAddress, blobClientConfig, jobID, userJars);
for (PermanentBlobKey blobKey : blobKeys) {
if (!userJarBlobKeys.contains(blobKey)) {
userJarBlobKeys.add(blobKey);
}
}
}
}
然后在JobManager的submitJob方法中会调用BlobLibraryCacheManager的registerJob创建并缓存该job的classloader
try {
libraryCacheManager.registerJob(
jobGraph.getJobID, jobGraph.getUserJarBlobKeys, jobGraph.getClasspaths)
}
catch {
case t: Throwable =>
throw new JobSubmissionException(jobId,
"Cannot set up the user code libraries: " + t.getMessage, t)
}
val userCodeLoader = libraryCacheManager.getClassLoader(jobGraph.getJobID)
TaskManager在执行Task时,首先会调用LibraryCacheManager的registerTask从BlobServer下载相应的jar包并创建classloader
blobService.getPermanentBlobService().registerJob(jobId);
// first of all, get a user-code classloader
// this may involve downloading the job's JAR files and/or classes
LOG.info("Loading JAR files for task {}.", this);
userCodeClassLoader = createUserCodeClassloader();
private ClassLoader createUserCodeClassloader() throws Exception {
long startDownloadTime = System.currentTimeMillis();
// triggers the download of all missing jar files from the job manager
libraryCache.registerTask(jobId, executionId, requiredJarFiles, requiredClasspaths);
LOG.debug("Getting user code class loader for task {} at library cache manager took {} milliseconds",
executionId, System.currentTimeMillis() - startDownloadTime);
ClassLoader userCodeClassLoader = libraryCache.getClassLoader(jobId);
if (userCodeClassLoader == null) {
throw new Exception("No user code classloader available.");
}
return userCodeClassLoader;
}
涉及到的相关配置
| 参数 | 默认值 | 描述 |
|---|---|---|
| high-availability.storageDir | 无 | HA BlobStore根目录 |
| blob.storage.directory | <java.io.tmpdir> | BlobServer 本地文件根目录 |
| blob.fetch.num-concurrent | 50 | BlobServer fetch文件的最大并行度 |
| blob.fetch.backlog | 1000 | 允许最大的排队等待链接数 |
| blob.service.cleanup.interval | 3600 | BlobServer cleanup 线程运行的间隔 |
| blob.fetch.retries | 5 | 从BlobServer下载文件错误重试次数 |
| blob.server.port | 0 | BlobServer端口范围 |
| blob.offload.minsize | 1024 * 1024 | 运行通过BlobServer传递的最小消息大小 |
| classloader.resolve-order | child-first | classloader类加载顺序 |