【知识点回锅】 异步服务与多线程
今天回看了去年学的分布式系统课程,讲的是进程,线程,异步与回调,协程。结合最近的项目经验,感觉对其有更深的理解了。
多进程与多线程
谈到这个,不得不先说最近的项目经验。图像处理五千万像素的图片,用python单线程运行,就需要十余分钟,多浪费时间啊!
作为一台带多核CPU的本本,我不能忍!于是便试着去查找有关优化的方法,除了用GPU进行硬件加速处理外,第二种比较理想的方法是利用多线程或多进程。
在操作系统中,进程是资源分配的基本单位,线程是CPU调度(程序执行)的最小单位。可以这样理解,计算机执行程序必须分配资源(一般是内存,有堆、栈、自由存储区、全局/静态变量区、数据区)。
这样我给一个程序分配资源时按基本单位————进程进行分配。多进程指进程A获得20%资源,进程B获得30%资源…一个多进程的简单例子是Chrome浏览器,可以看到Chrome占用了多个进程。
而线程是程序执行的最小单位,有时称为轻量级进程,是CPU使用的基本单元;它由线程ID、程序计数器、寄存器集合和堆栈组成。它与属于同一进程的其他线程共享其代码段、数据段和其他操作系统资源(如打开文件和信号)。
线程有四种状态:新生状态、可运行状态、被阻塞状态、死亡状态。状态之间的转换如下图所示: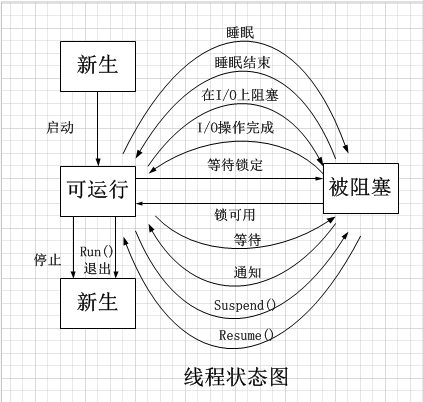
线程与进程的区别?
- 从如何创建的角度:进程是由执行程序后系统进程fork生成的,创建后生成一个PCB;线程是由父进程负责创建的,创建后生成一个TCB
- 从拥有资源的角度:进程拥有内存资源,有独立的地址空间、有独立的数据段、代码段、堆栈段;线程拥有CPU资源,也有自己的局部变量和栈
- 从通信的角度:进程之间的通信只能通过进程通信(共享内存模式、消息传递模式、共享文件模式)进行;同一进程下线程之间的通信是通过共享的数据区进行通信的
- 从执行的角度:进程可以独立执行(通过);但线程必须依附他的父进程执行
另外,不是所有语言都支持多线程多进程的编程。众所周知,Java就是用来做web的多线程多进程的编译型语言。
javascript是单线程引擎,不支持多线程,只能 模拟多线程;python 支持多线程!但每个线程的性能立马给你下降30%-40%(为了保证线程安全,用全局锁管理字典这样复杂的数据结构再所难免)
python 难道不能开发企业级应用? 异步服务英雄上场了, Tornado 开创了这个世界, node.js 们都在学习,甚至做的更好。
有了异步,我们就可以用 单进程单线程 “并发”做爬网页、访问数据库、发邮件等等工作。(注意,异步只能解决 IO 阻塞问题,而web一般就是读写数据存在IO阻塞,请求响应飞快)
异步服务
python异步编程主要有三种方法:回调函数、生成器法、线程大法
其中生成器是python的一个重要成果,下次分析将详细介绍这个。
线程大法很管用,但是如果线程中访问共享变量,就会出现 GIL 问题。
这里有介绍Tornado异步Web服务
回调函数
|
1
2
3
4
5
6
7
|
from tornado.httpclient import AsyncHTTPClient
def asynchronous_fetch(url, callback):
http_client = AsyncHTTPClient()
def handle_response(response):
callback(response.body)
http_client.fetch(url, callback=handle_response)
|
生成器法
|
1
2
3
4
5
6
7
8
9
10
11
|
from tornado import gen
def fetch_coroutine(url):
http_client = AsyncHTTPClient()
response = yield http_client.fetch(url)
# In Python versions prior to 3.3, returning a value from
# a generator is not allowed and you must use
# raise gen.Return(response.body)
# instead.
return response.body
|
线程大法
|
1
2
3
4
5
|
thread_pool = ThreadPoolExecutor(4)
def call_blocking():
yield thread_pool.submit(blocking_func, args)
|
异步总结
使用异步处理可以让我们的应用在长时间的API和数据库请求中免受阻塞之苦,最终更快地提供更多请求。
尽管不是所有的处理都能从异步中受益,并且实际上尝试整个程序非阻塞会迅速使事情变得复杂,但Tornado的非阻塞功能可以非常方便的创建依赖于缓慢查询或外部服务的Web应用。
最后尽管有了异步操作,我们还希望根据实际的应用需求定制优化方案,比如制定缓存服务器存储经常使用的数据,比如采用负载均衡的架构使得分布式系统整体发挥最大性能。