####
目录

面试的时候问你基础概念和工作流程,看看你对这个框架是否熟悉
#####
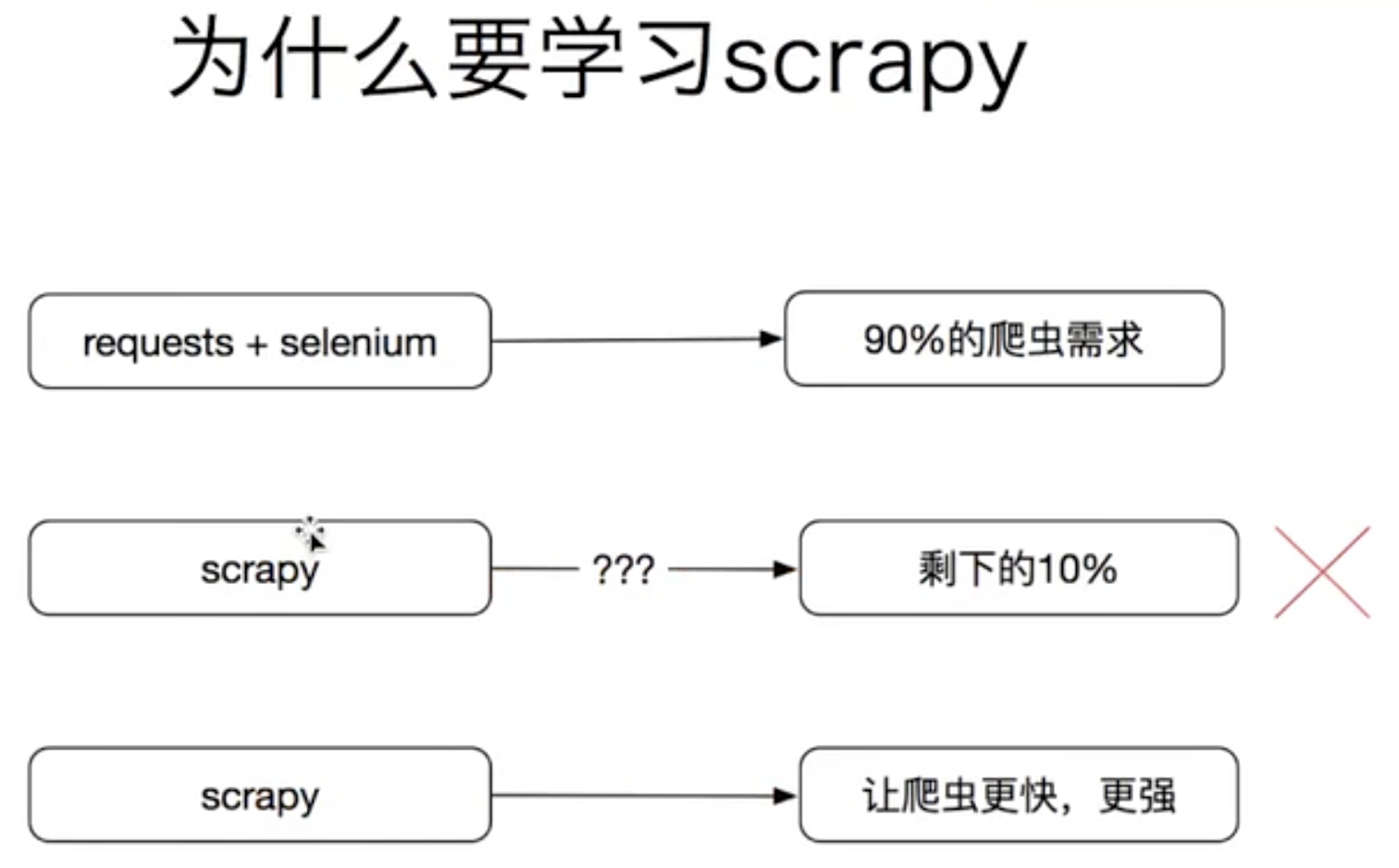
其实使用requests+selenium就可以解决90%的爬虫需求了,但是为什么还需要学习scrapy?
scrapy是为了让爬虫更快,更强,解决抓取效率慢,解决爬虫的效率和速度的问题,
#####

框架和模块的区别是什么?
requests是模块,
框架能解决特定需求的所有的功能,包含了很多的模块,
框架是大而全的东西,而模块只是实现了一个特定的功能,
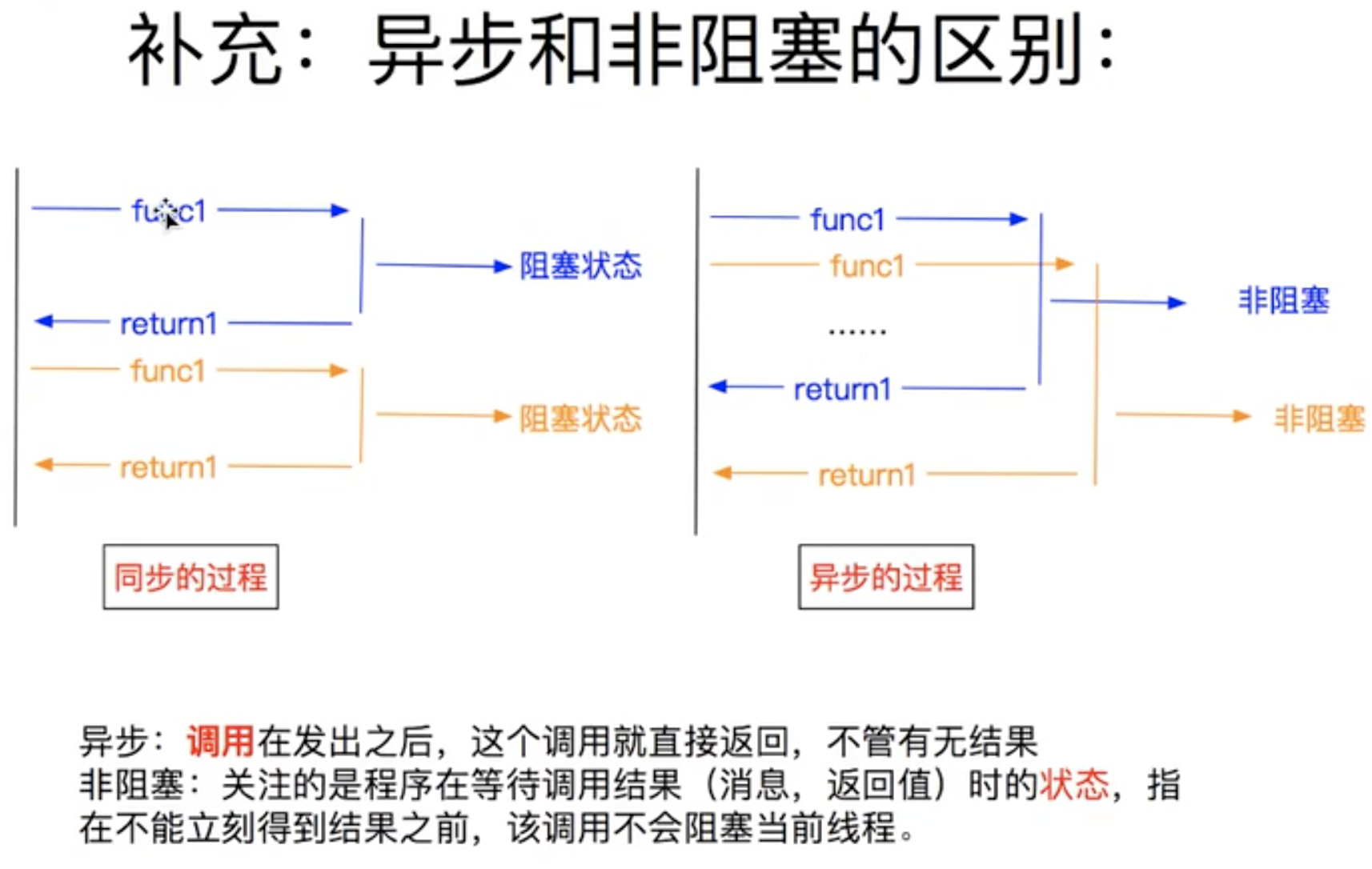
twisted异步框架,扭曲的意思,
####
用做菜煮饭的例子非常的形象
####

####

####
####
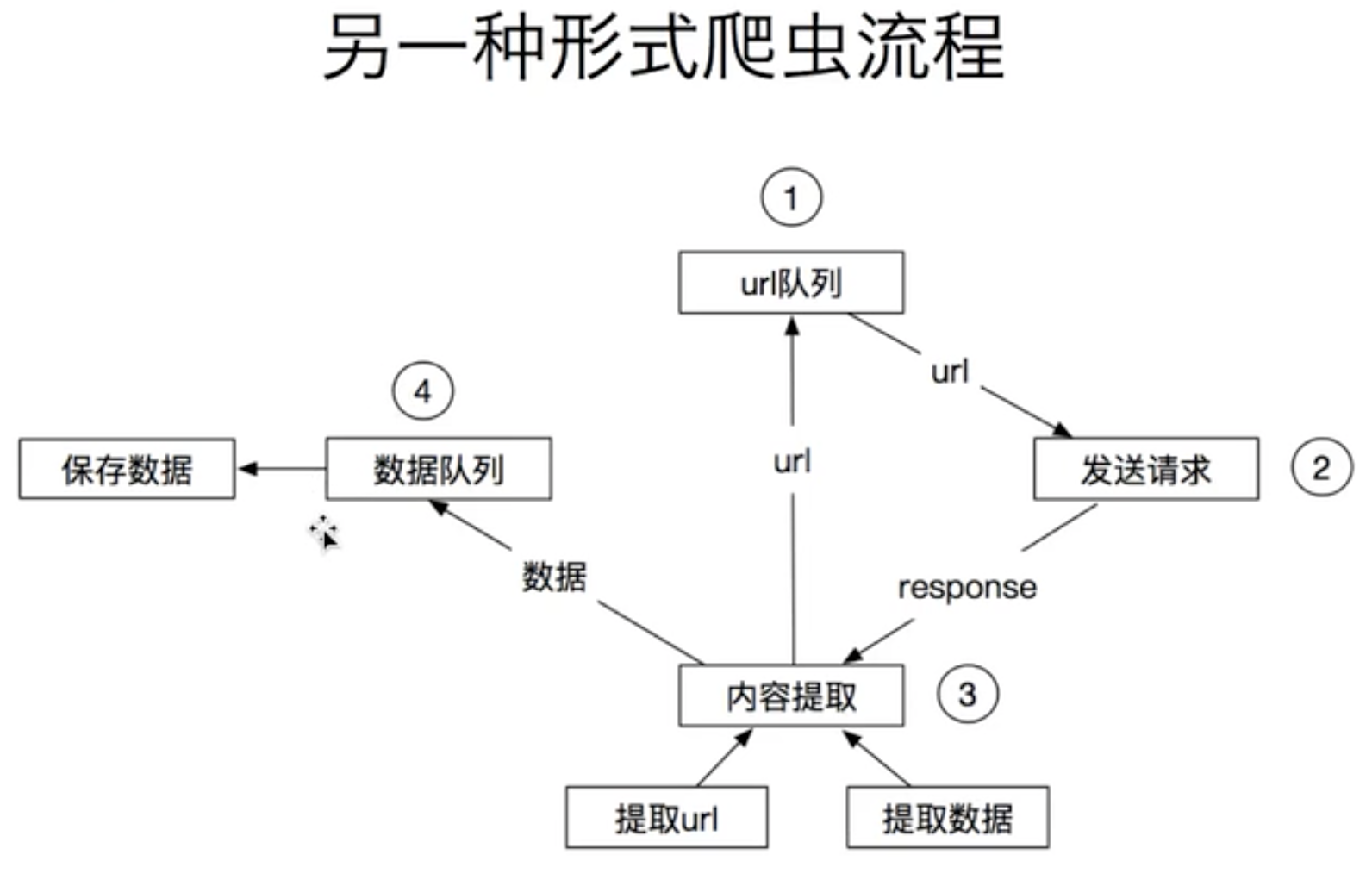
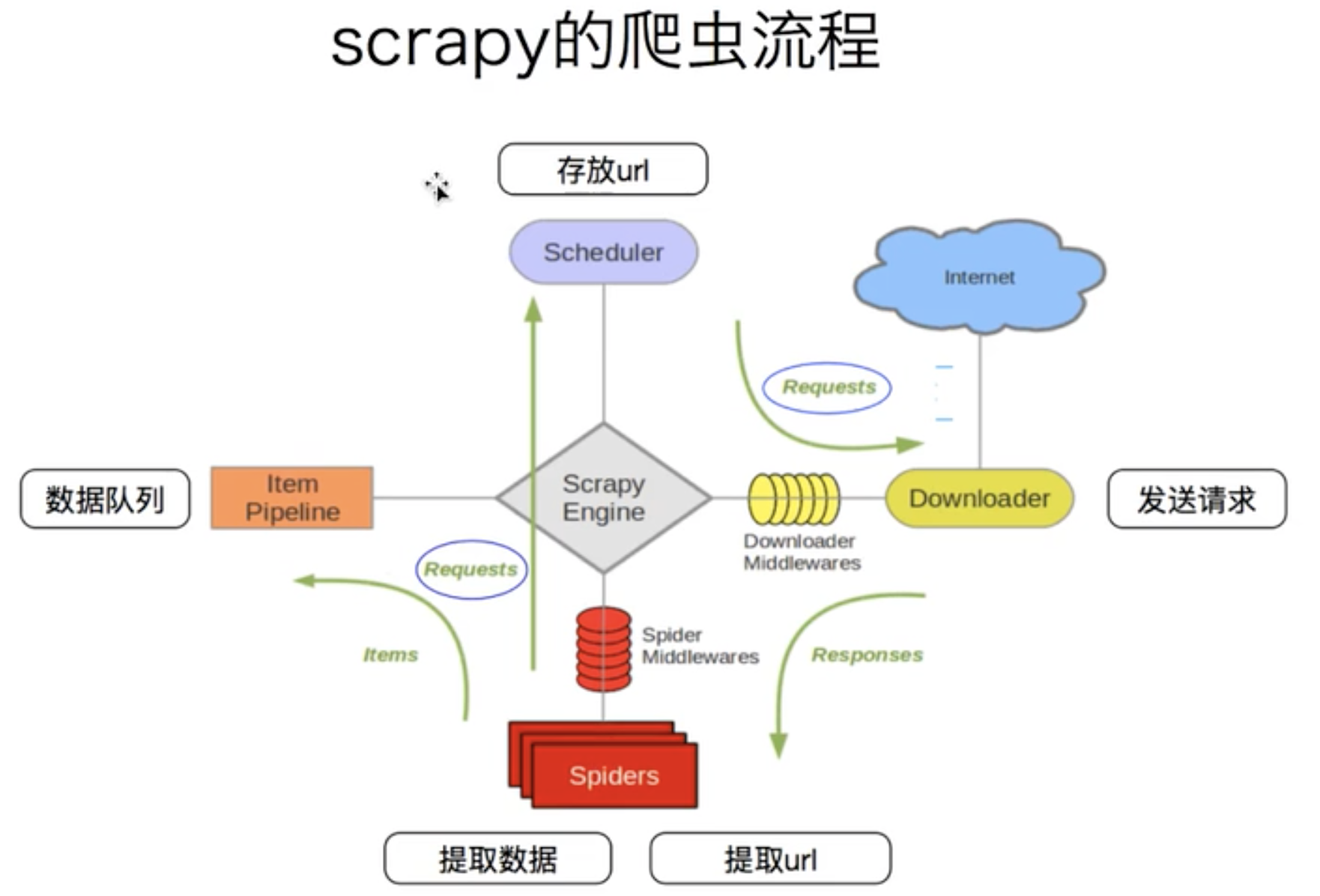
scheduler,就是一个调度器,存放是requests对象,这个对象有一些属性,比如url地址,header,代理,都是这里面,
downloader,下载器,这个是为了从url池子里面取url,发起请求获取数据
spiders,爬虫,这个就是从下载的内容提取数据给数据队列,还可以提取url并且还需要组装成request对象再传递给调度器里面去,做了两个事情,
item pipeline,这个是数据队列,为了保存数据,管道,就是把前一次的输出作为后一次的输入,
scrapy engine,引擎,爬虫获取到的url就是组装成request交给引擎,然后引擎给了调度器, 所以上面的四个模块是不联系,都是通过引擎联系,这就是解耦,容错率高,引擎负责所有的调度,
downloader middlewares,下载中间件,也就是我们可以写一个中间件,可以对下载做额外的处理的,
spider middlewares,爬虫中间件,这个地方也可以处理保存数据,但是因为我们有专门的item pipeline了,所以不需要在这里处理,两个中间件很像加工厂,可以处理数据,丢弃数据,
为什么要分这么多的模块,因为分开了之后更简短了,
和平哥的思路是一样的,
####

所以框架可以加快爬虫速度,而且还能少些很多代码,把精力放到核心业务处理的地方,
####
写爬虫很简单,写出高可用的爬虫就不容易了,
scrapy框架的问题:
1,scrapy_redis通过redis实现调度器的队列和指纹集合,完成分布式和去重。
2,scrapy_redis_bloomfilter,基于Redis的Bloomfilter去重,并将其扩展到Scrapy框架,实现持久化去重,上亿或十亿级别的去重功能。
3,scrapy-splash ,整合了javascript,可以在scrapy当中执行js,获取数据,解析。
4,不能满足实时监控和告警的需求。
5,可视化的问题,相信大家在跑爬虫的过程中,也会好奇自己养的爬虫一分钟可以爬多少页面,多大的数据量。
可视化的问题,不是scrapy可视化的问题,而是爬虫可视化的问题,这个每一个爬虫都面临这个问题,
当你部署很多爬虫以后你就需要一个可视化的爬虫监控系统。来方便查看每个爬虫的入库数据和工作状态等
6,项目管理的问题,
7,框架的高级应用,待爬取的目标网页站点,千奇百怪,在实际项目中,为了快速方便的实现功能,需要灵活的使用框架,比如结合requests使用,修改源码,重新定义扩展,输出日志到可视化工具系统,自定义发送钉钉预警等。
####
可见scrapy不能解决所有的问题,
有些问题还需要你自定义,就需要玩转线程和协程这些东西,!!!!
#####