Microsoft SQL Server没有使其允许速度更快的配置选项或开关,也没有魔术棒。
但是,如果适当地创建和设计索引,则可以使索引发挥魔法棒的作用。
--- 摘选自(深入解析SQL Server 2008)第六章 索引:内部和管理
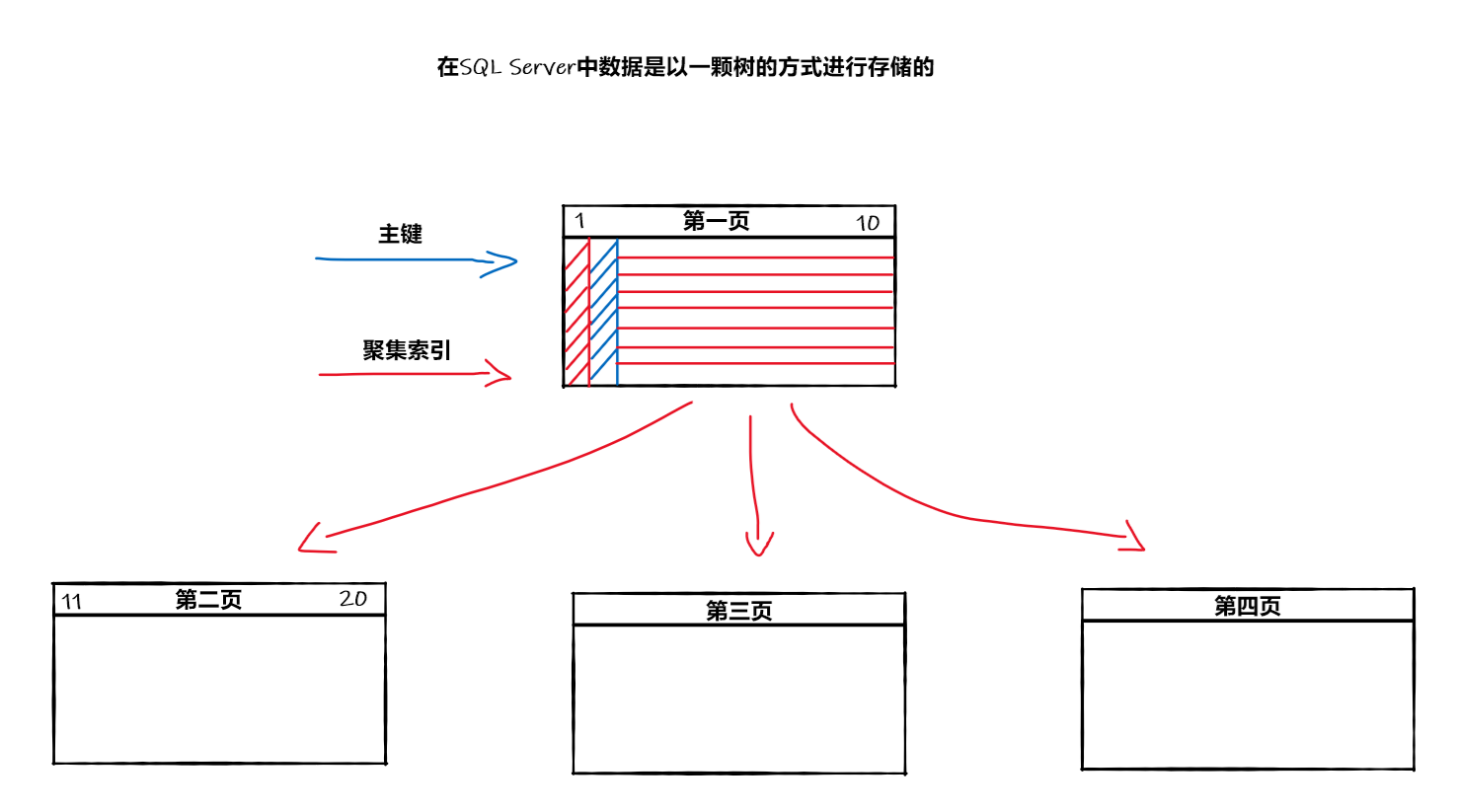
聚集索引
说到聚集索引,不得不提到主键,在我们日常建立主键时,默认会将其设置为聚集索引,主键和聚集索引是两个概念,不能混为一谈。
主键的作用是打个标识,让这行数据唯一
聚集索引也必须要唯一,聚集索引必须唯一的主要原因是使非聚集索引项可以精确地指向某一特定地行。
--- 摘选自(深入解析SQL Server 2008)第六章 索引:内部和管理
聚集索引,也可以理解为数据块,根据指定列进行范围大小排序,从小到大进行分类,将其以块进行区分,这样用聚集索引查询的时候就先看这个区间的大小是否满足,满足的话就进入此区间进行查找,这样比漫无目的的查询要快了许多。(聚集的意思顾名思义,就是把差不多的东西放在一起)
但其实也不用想这么多,合理的使用自增和GUID作为聚集索引就好了,这次我们就拿Id为主键,聚集索引作为例子
现在我们把新建一张Student_1表用来操作索引,然后把Student表的数据导入进去
CREATE TABLE [dbo].[Student_1](
[Id] [uniqueidentifier] NOT NULL,
[Name] [nvarchar](50) NULL,
[Age] [int] NULL,
[Gender] [nvarchar](10) NULL,
[Area] [nvarchar](50) NULL,
[Address] [nvarchar](50) NULL,
[IdCard] [nvarchar](50) NULL,
[Birthday] [datetime] NULL
)
GO
insert into Student_1
select * from Student
然后通过执行计划来查询Student_1表
执行计划,能帮助我们分析这一段SQL合不合理,效率怎么样,也能看到我们建立的索引到底有没有效果
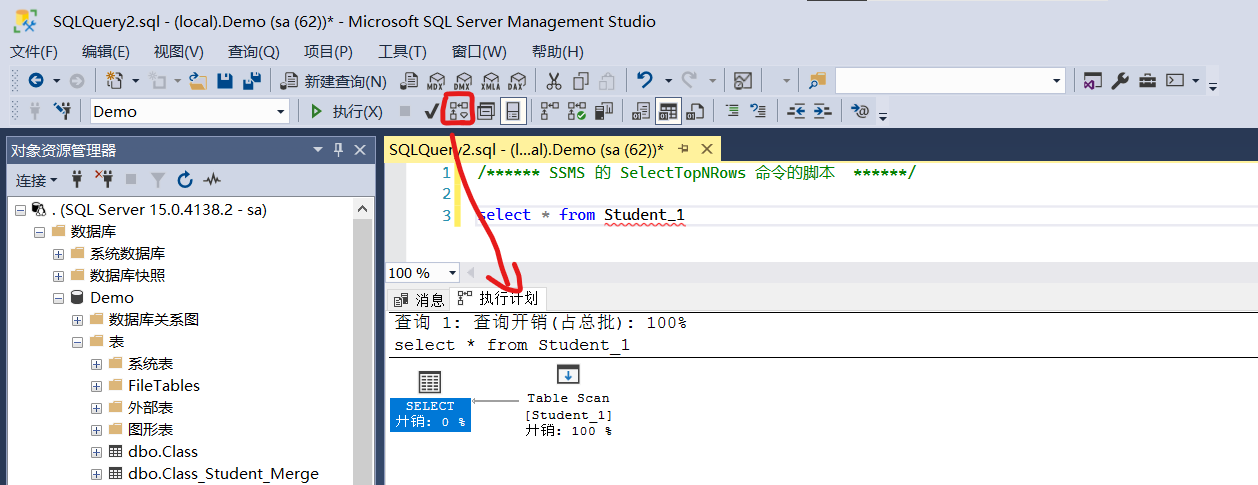
可以看到,当我们不建立主键,索引,它的查询方式是普通扫描,就一行一行的查询
接下来我们创建主键,但是不指定它为聚集索引,来看效果
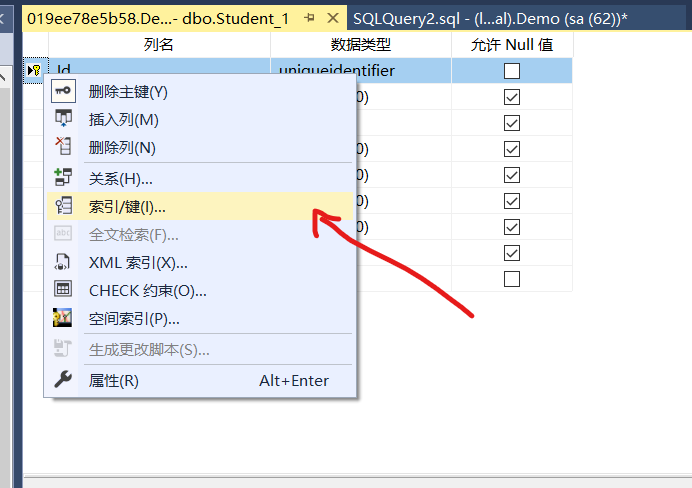
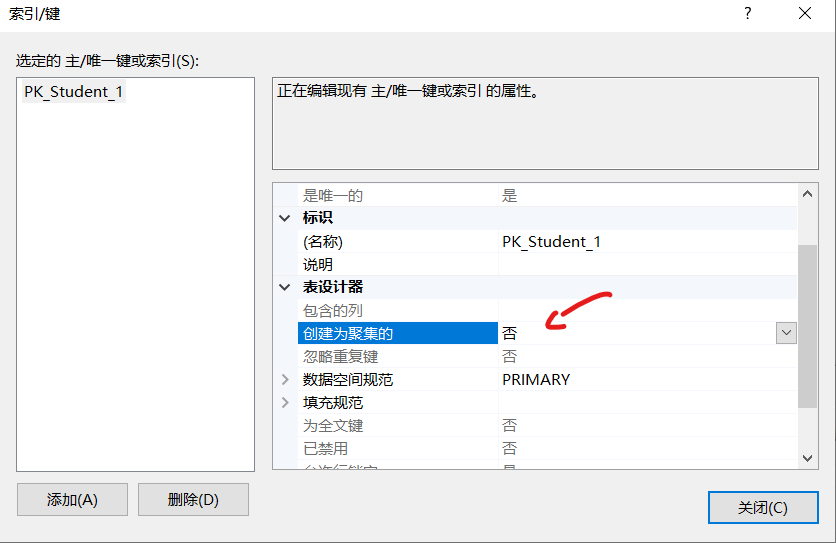
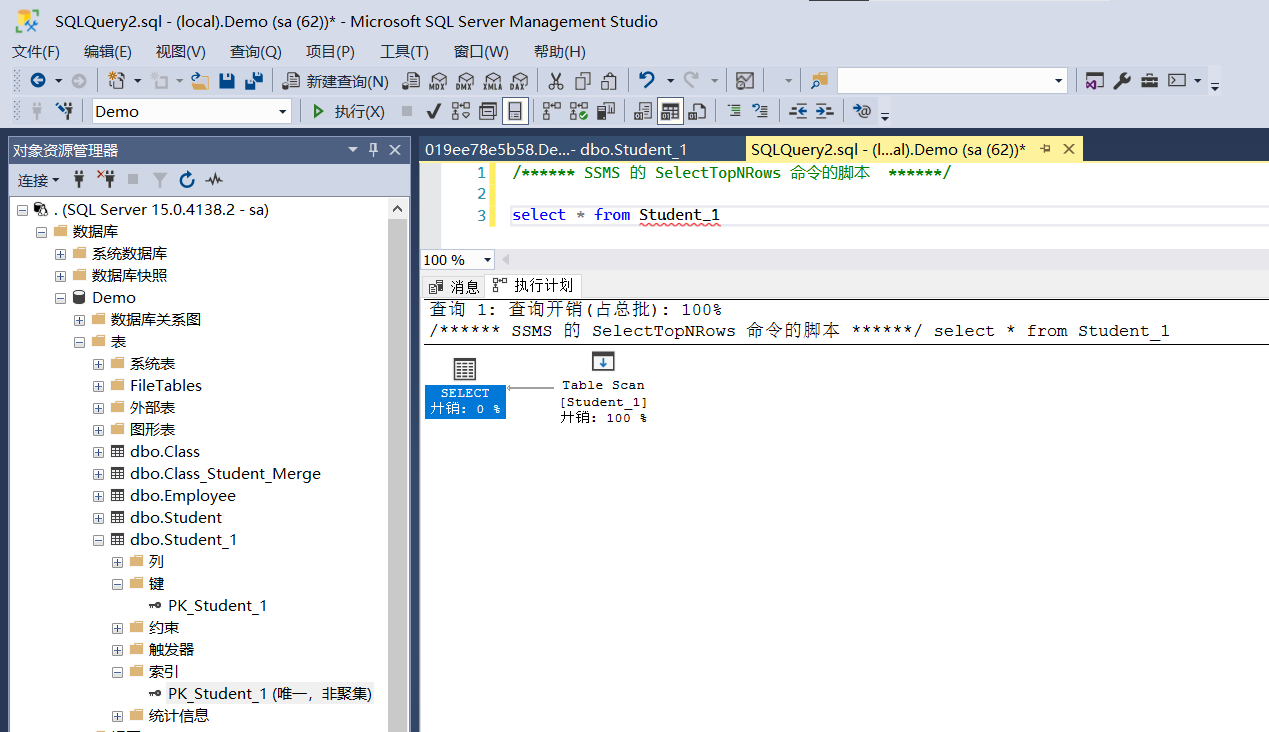
还是一样,所以这也证明了主键仅仅只是作为唯一标识
接下来建立了聚集索引那又不同了
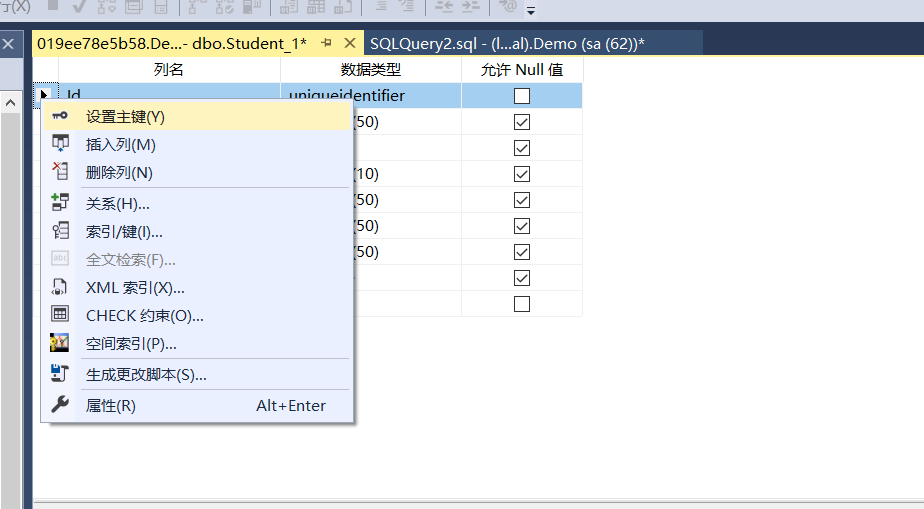

它走的是我们建立的聚集索引,为什么建立了聚集索引它就不同了?
因为聚集索引的特性就是能把每列数据捆绑在自己身上,就意味着数据库查询时,只需要知道这一列就能把后面的列带出来,而不像之前的表扫描每一列都得去确认。
非聚集索引
前面理解到聚集索引是唯一的,那么就是不怎么可变动的数据,但是现实中怎么可能不保持变化,所以就有了非聚集索引的诞生。
聚集索引已经把数据进行归类了,我们非聚集索引的位置在什么地方?它是以什么方式介入到我们的查询中?
如果说聚集索引已经分好类,并且按顺序存储好我们的内容,那么非聚集索引更像是目录,它将指定列的值汇总起来,并告知它们所在哪一个数据块中。
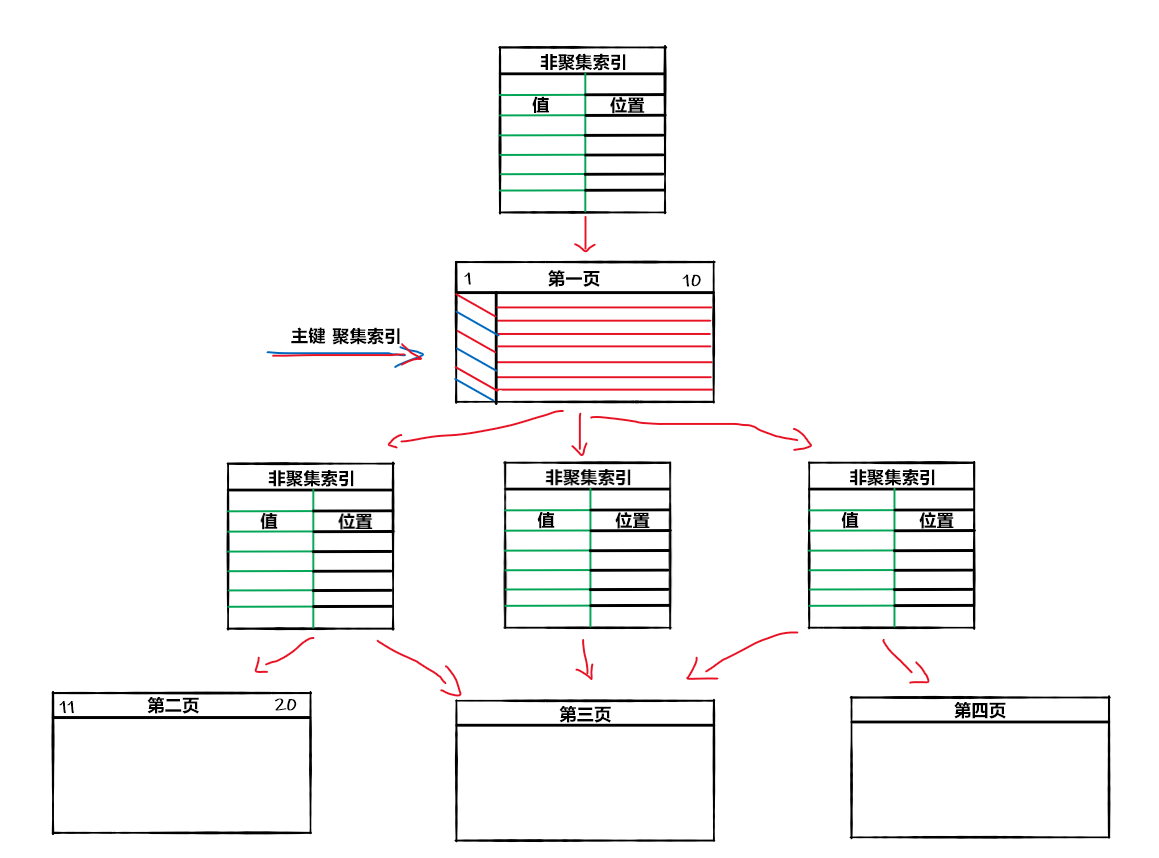
在这个图可以看到,实际上聚集索引和非聚集索引的数据块其实是独立的,每次查询前SQL Server的引擎会给我们优先计算路线,到底是聚集索引快,还是非聚集索引快。
如何使用索引,where索引列或select索引列,就可以触发
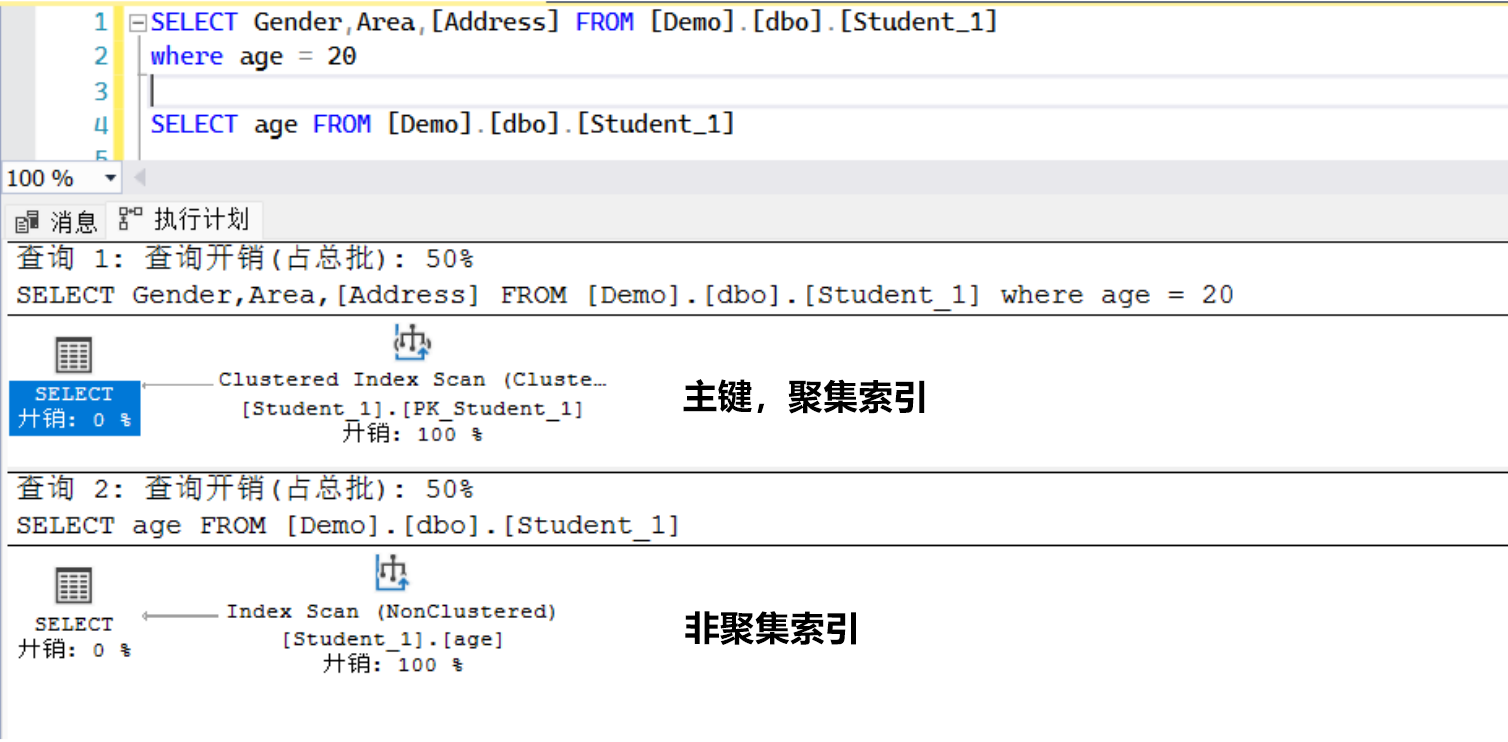
在建立非聚集索引的时候,我们一般只会去建立索引列,而不会去建立包含性列,那包含性列是什么?
索引列既能被where使用,也能被Select使用,但是出现另外一种情况就不会触发了,就如上面那张图所表示的,Sql Server的引擎计算判断到聚集索引快,而不是我们非聚集索引,就因为我们的非聚集索引里面只有一列而已,而聚集索引是整个行,所以这就是包含性列要解决的问题。
当我们加了包含性列就会变成下面的这种情况

接下来我们把这三列加上
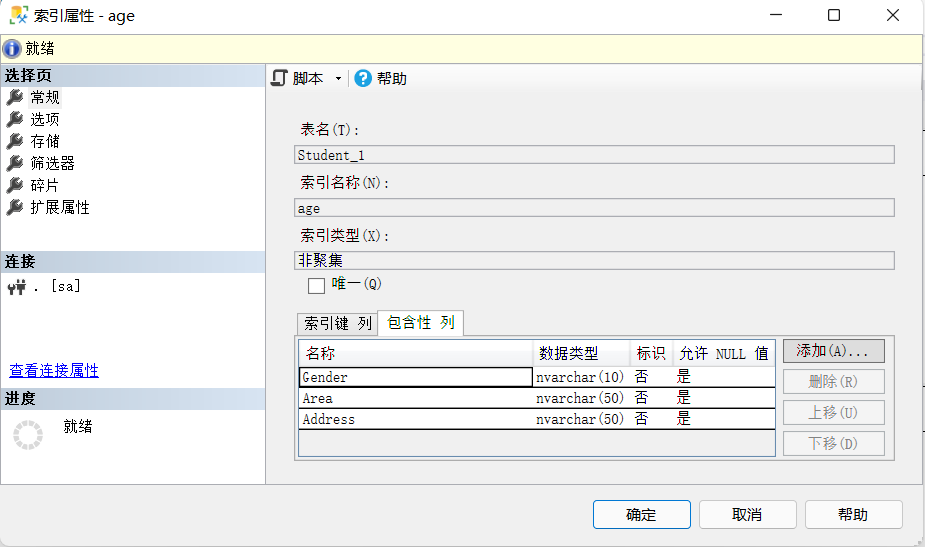
来看效果
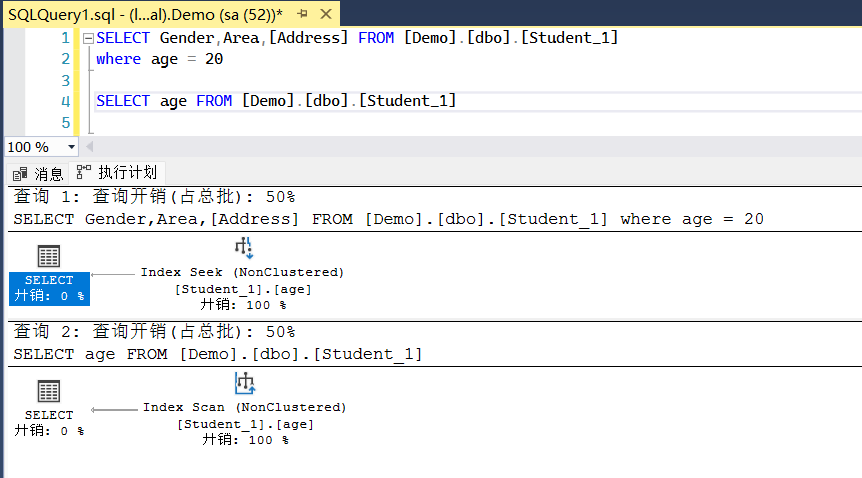
完全就走我们的非聚集索引了
最后,关于怎么建立索引,多去尝试,多去使用执行计划去分析,才能建立正确的索引,索引不在乎多但是一定要到位,不然就不是魔法棒而是塑料棒了