python 高阶函数
1.匿名函数lambda --函数的实现比较简单的时候,用lambda
2.map() 映射
3.reduce() 累加
4.filter() 过滤
5.zip()---非高阶函数
recursion 递归
closure 闭包
正文:
首先要知道什么是高阶函数:一个函数作为参数,传入另一个函数
1.匿名函数 lambda表达式(函数)
1).为什么使用匿名函数?简化函数的书写,不需要函数名,便于阅读
2).lambda表达式的语法
lambda 变量1,变量2,:变量1,2的表达式
sorted()内置函数:对所有可迭代的对象进行排序操作
语法:sorted(iterable, key=None, reverse=False)
- iterable -- 可迭代对象。
- key -- 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
- reverse -- 排序规则,reverse = True 降序 , reverse = False 升序(默认)
应用场景:sorted+lambda 进行排序
❤下面对学生age排序使用函数调用的方式,不方便阅读;而使用lambda表达式,清晰明了!!
def fun(student:dict): return student["age"] def sorted_test(): students = [ {"name":"zhangsan","age":19}, {"name": "lisi", "age": 21}, {"name": "wanger", "age": 17}, {"name": "zhaowu", "age": 15} ] # 调用fun()函数获取age作为key,进行排序 print(sorted(students, key=fun)) # 直接输入函数名即可 # 对函数中的学生按年龄排序,sorted 结合lambda对字典进行拍戏 print(sorted(students, key=lambda x: x["age"])) # 默认升序排序 print(sorted(students, key=lambda x: x["age"], reverse=True)) # 设置反序排序 if __name__ == '__main__': print(sorted_test())
多列排序:先按照age排序,再按照name排序,看输出结果,一目了然。
多列排序的key是一个元祖
def sorted_test2(): students2 = [ {"name": "a", "age": 20}, {"name": "b", "age": 19}, {"name": "c", "age": 19}, {"name": "d", "age": 20} ] print(sorted(students2,key=lambda x: (x["age"], x["name"]))) if __name__ == '__main__': print(sorted_test2()) #[{'name': 'b', 'age': 19}, {'name': 'c', 'age': 19}, {'name': 'a', 'age': 20}, {'name': 'd', 'age': 20}]
2.map()函数--映射
1). 功能:根据提供的函数对指定序列做依次映射
2). map() 函数语法:map(function, iterable, ...)
- function -- 函数
- iterable -- 一个或多个序列
3).说明:第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。
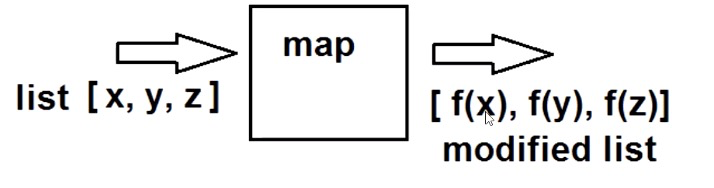
4) 返回值:迭代器
场景:给定的字母,与给定的数字,依次按顺序一一对应起来
from typing import Iterator def map_test(keys:list, values:list) ->Iterator: return map(lambda key, value: {key, value},keys,values) if __name__ == '__main__': print(map_test(["a","b","c"], [4, 5, 6])) for item in map_test(["a", "b", "c"], [4, 5, 6]): print(item) """ <map object at 0x10e502b10> {'a', 4} {'b', 5} {'c', 6} """
不用lambda表达式,用函数调用方法,一样的结果。
from typing import Iterator def fun(keys,values): return {keys:values} def map_test(keys:list, values:list) ->Iterator: # return map(lambda key, value: {key, value},keys,values) return map(fun,keys,values) if __name__ == '__main__': print(map_test(["a","b","c"], [4, 5, 6])) for item in map_test(["a", "b", "c"], [4, 5, 6]): print(item)
举例2:把多个列表中的各个相同索引位置的元素相加,得到一个新列表
比如[1,2,3,4]、[2,3,4,5]、[3,4,5,6]---->[6,9,12,15]
def add_list(list1,list2,list3): return list(map(lambda x,y,z: x+y+z, list1,list2,list3 )) if __name__ == '__main__': print(add_list([1,2,3,4],[2,3,4,5],[3,4,5,6])) # [6, 9, 12, 15]
3.reduce() 函数
1).功能:会对参数序列中元素进行累积
2).reduce() 函数语法:reduce(function, iterable[, initializer])
- function -- 函数,有两个参数
- iterable -- 可迭代对象
- initializer -- 可选,初始参数
3)返回值:返回函数计算结果
4). 导入包:python3开始,reduce()已经被移到 functools 模块里,如果我们要使用,需要引入 functools 模块来调用 reduce() 函数
5)原理:
reduce(...) reduce(function, sequence[, initial]) -> value Apply a function of two arguments cumulatively to the items of a sequence, from left to right, so as to reduce the sequence to a single value. For example, reduce(lambda x, y: x+y, [1, 2, 3, 4, 5]) calculates ((((1+2)+3)+4)+5). If initial is present, it is placed before the items of the sequence in the calculation, and serves as a default when the sequence is empty.
举例:实现列表中元素的累加
from functools import reduce def add(x,y): return x+y print(reduce(add,[1,2,3,4,5])) # 15 print(reduce(lambda x,y: x+y, [1,2,3,4,5])) # 15
4.filter()过滤
1)功能:过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。--有过滤条件
2)filter()语法:filter(function, iterable)
- function -- 判断函数。
- iterable -- 可迭代对象。
接收两个参数,第一个为函数名,第二个为序列,序列的每个元素作为参数传递给函数进行判断,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。
3).返回值:filter对象,用list()转化成列表输出
# 过滤 def fun(x): if x > 3: return x print(list(filter(fun,[1,2,3,4,5]))) print(list(filter(lambda x: x > 3, [2,3,1,5,4])))
5.zip() -----不是高阶函数
1).功能:zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,返回的是一个zip对象
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表
2).语法:zip(iterable, ...)
- iterabl -- 可迭代对象
3).返回值:zip对象 ,用list()转化成列表输出
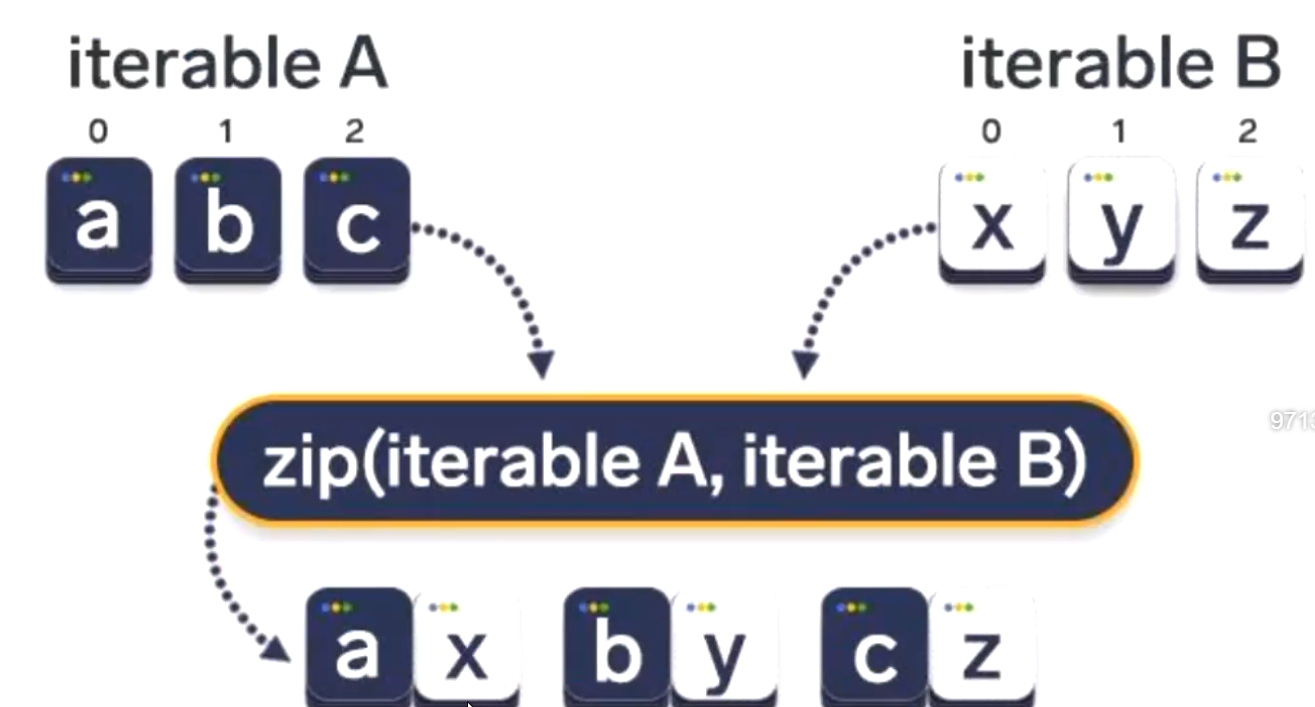
举例:
#email:971306309@qq.com from typing import Iterator def zip_fun(): A = ["a","b","c"] B = [1, 2, 3] print(zip(A,B)) # <zip object at 0x0000027C5D32D8C8> print(isinstance(zip(A,B),Iterator)) #True for item in zip(A,B): print(item) # 依次输出 ('a', 1) , ('b', 2) ,('c', 3) print(list(zip(A,B))) # [('a', 1), ('b', 2), ('c', 3)] if __name__ == '__main__': zip_fun()
6.递归
1)什么是递归?
函数在运行的过程中调用自己
2)构成递归的条件:
①每次进入更深一层递归时,问题规模相比上次递归都应有所减少
②必须有一个明确的递归结束条件
③ 递归调用的表达式
3)特点:递归执行效率不高,递归层次过多会导致栈溢出
4).递归深度 -----最大递归次数
import sys sys.setrecursionlimit(1000) # 表示递归深度为1000,即只能递归1000次
举例:递归实现reduce的累加功能
def recursiontest(x=100): if x == 1: # 递归结束的条件 return 1 # 递归结束 return recursiontest(x-1) + x # 递归调用 if __name__ == '__main__': print(recursiontest()) # 5050
举例:递归实现阶乘
def func(x ): if x == 1: return 1 return func(x-1) * x if __name__ == '__main__': print(func(5)) # 120
7.闭包
1).基础知识点------函数可以作为参数传给另一个函数
def test1(name): print("函数test1") return name() def test2(): print("函数test2") test1(test2) """ 函数test1 函数test2 """
调用函数test1(test2),传入的参数是函数test2
注意test2作为参数,不能加(),才可以被到处传递。如果加了括号,就是调用test2函数了。
例如,下面的test2加括号,就是先调用test2()函数,再执行test1()函数了。
def test1(name): print("函数test1") def test2(): print("函数test2") test1(test2()) """ 函数test2 函数test1 """
2).闭包 Closure
①什么是闭包?
--嵌套函数:即外层函数里面又定义了一个内层函数 (体现:包)
--内层函数调用了外层函数的非全局变量 (体现:闭 ,内存函数操作外层函数的局部变量因为一般函数内的局部变量是不能操作的,通过函数内部的函数操作局部变量
--外层函数的返回值:是内层函数名
以上3个条件同时满足,就构成了一个闭包。
举个栗子:
def outer(): result = 0 def inner(): nonlocal result result += 1 print(f"result的值{result}") return inner if __name__ == '__main__': f = outer() f() # result的值1 f() # result的值2 f() # result的值3
多次调用时,上一次函数的调用状态可以被保存下来,------打破了函数一旦结束,里面的数据全部销毁的思维。
思考:为什么闭包可以保存函数的调用状态?
因为调用outer()函数时,返回的时内层函数,外层函数并没有真正结束(内层函数还在继续调用),所以result的变量也就没有销毁,即内层函数可以继续对outer中的变量进行操作。
②.闭包思想的意义:保存函数种某个变量的值。
小试牛刀
# 题目1.一个小球从100米高度自由落下,每次落地后反跳会原来的高度的一半再落下,求在第十次落地时,共经过多少米?用递归实现 # 方法一 def ball_pop(n, h=100): if n == 1: return h return ball_pop(n-1) + h/2**(n-1) * 2 # 方法二 def ball_pop1(n, h=100, a=0): if n == 1: return a + 100 a += h/2**(n-1) * 2 return ball_pop1(n-1, h=100, a=a) # 题目2 200元买200本书,A类5元一本,B类3元一本,C类1元2本,有多少种买法? # 思路:先明确200元钱单独买每类书,可以买多少本,再进行for循环嵌套,最后输出符合条件的即可 def buy_book(): money = 200 nums = 200 count = 0 # 记录买法的种类 for a in range(int(money/5) + 1): for b in range(int(money/3) + 1): for c in range(int(money/0.5) + 1): if 5 * a + b * 3 + c * 0.5 <= 200 and a + b + c ==200: count += 1 return count if __name__ == '__main__': print(ball_pop(10)) print(ball_pop1(10)) print(buy_book())