Hadoop的分布式安装
hadoop安装伪分布式以后就可以进行启动和停止操作了。
首先需要格式化HDFS分布式文件系统。hadoop namenode -format
然后就可以启动了。start-all.sh
此时使用jps命令可以查看启动的5个守护进程
也可以通过web查看是否启动成功。
localhost:50070查看 NameNode 节点,localhost:50030查看 JobTracker 节点
停止命令。stop-all.sh
一、配置IP
这是使用了两台已经配置好 hadoop 单机环境的 Ubuntu
Ubuntu_master:192.168.1.3
ubuntu_slave:192.168.1.6
二、配置主机名及 hosts 文件
为了能使用 登录以及 ping 更简单
我们在这里配置地址及主机名到 hosts 文件
在 /etc/hosts 文件中添加以下内容:
192.168.1.3 master
192.168.1.6 slave
同时使用 nmtui 命令修改自己的主机名,重启生效
三、配置 hadoop 环境变量
使用 vim ~/.bashrc 编辑用户环境配置文件
在该文件中加入下列内容:
export PATH=$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin
然后使用 source ~/.bashrc 使其生效
用 hadoop version 命令检查上述操作是否生效
四、配置 hadoop 配置文件
1、slaves 将数据节点主机名写入其中
2、core-site.xml 配置文件

3、hdfs-site.xml 配置文件

4、mapred-site.xml 配置文件

5、yarn-site.xml 配置文件

五、将配置文件拷贝至各 slave 节点
在 /usr/local/hadoop 目录下
tar -zcvf etc.tar.gz etc 将文件夹打包
scp etc.tar.gz slave:/home 传送
此时报权限错误而无法传送
原因是:当前用户没有在 /home 下的写权限
当我用 root 身份登录时,发现依然不行
一直报访问拒绝错误
原因是:ssh 设置不可使用 root 什么登录
解决办法:/etc/ssh/sshd_config 配置文件中
PermitRootLogin 的值改为 yes
这里我们使用 scp etc.tar.gz slave:/home/haojun 命令传送
然后 ssh slave 登录到 slave
然后 rm -rf /usr/local/hadoop/etc 删除原配置文件
然后 tar -zxvf etc.tar.gz -C /usr/local/hadoop 解压新配置文件
此时应确保解压后的权限与当前用户一致,否则应
sudo chown -R haojun:haojun /usr/local/hadoop/etc 更改权限
六、执行 NameNode 初始化并关闭防火墙
在 master 节点上 执行
hdfs namenode -format 即可
出现类似下面信息即表示成功:

如果没有,则查看上面的执行日志,以更改错误
多数错误是配置文件书写错误!也就是笔误!!
命令 作用
sudo ufw status 查看防火墙状态
sudo ufw enable 激活防火墙
sudo ufw disable 关闭防火墙
以上三条命令适用于发行版为 Ubuntu 的 Linux
七、启动 hadoop
start-dfs.sh 启动第一、二名称节点
start-yarn.sh 启动资源管理器
mr-jobhistory-daemon.sh start historyserver 启动工作历史服务
jps 查看节点启动情况
hdfs dfsadmin -report 查看数据节点启动情况
正常情况下,master 应该有如下图,slave 亦是。
 此时亦可通过web访问:http://master:50070/ 查看各节点启动情况
此时亦可通过web访问:http://master:50070/ 查看各节点启动情况
补充:如无法正常启动,还可通过删除 tmp、logs 等文件夹并重新初始化 NameNode 节点的方式排错。

八、执行分布式实例
8.1创建 HDFS 上的用户目录
hdfs dfs -mkir -p /user/hadoop
8.2创建 input 文件夹
hdfs dfs -mkidr input
此处报文件不存在错误
再次开机时以及可以。
可能是之前某些操作没有执行成功,或者命令打错根本没有执行。
hdfs dfs -put /usr/local/hadoop/etc/hadoop/*.xml input
拷贝样例文件
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output ‘dfs[a-z.]+’
执行命令

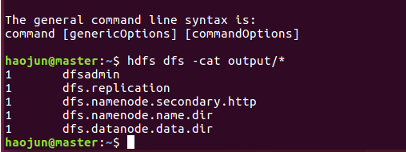
hdfs dfs -cat output/*
即可查看如下图结果
stop-yarn.sh
stop-dfs.sh
mr-jobhistory-daemon.sh stop historyserver
以上是关闭命令