决策树(Decision Tree)是一种非参数的有监督学习方法,它能够从一系列有特征和标签的数据中总结出决策规则,并用树状图的结构来呈现这些规则,以解决分类和回归问题。决策树尤其在以数模型为核心的各种集成算法中表现突出。
开放平台:Jupyter lab
根据菜菜的sklearn课堂实效生成一棵决策树。
三行代码解决问题。
from sklearn import tree #导入需要的模块 clf = tree.DecisionTreeClassifier() #实例化 clf = clf.fit(X_train,Y_train) #用训练集数据训练模型 result = clf.score(X_test,Y_test) #导入测试集,从接口中调用所需要信息
利用红酒数据集画出一棵决策树。
从sklearn库中引入决策树、红酒数据集
from sklearn import tree from sklearn.datasets import load_wine from sklearn.model_selection import train_test_split
根据不纯度找出最佳节点和最佳的分歧方法。计算不纯度有两个指标:信息熵和基尼(Gini)指数。
例化决策树,DecisionTreeClassifier是分类树,DecisionTreeRegressor是回归树,tree.export_graphviz命令是将生成的决策树导出为DOT格式,画图专用。通常使用基尼系数,数据维数很大,噪声很大时使用基尼系数。维度低,数据比较清晰时,信息熵与基尼系数没区别。当决策树的拟合程度不够时,使用信息熵。
下面例化决策树,首先将数据分成训练集和测试集。
Xtrain,Xtest,Ytrain,Ytest = train_test_split(wine.data, wine.target, test_size = 0.3)
注意分类的顺序为XXYY
clf = tree.DecisionTreeClassifier(criterion = "entropy") clf = clf.fit(Xtrain, Ytrain) score = clf.score(Xtest, Ytest) #返回预测的准确度accuracy
我得到的分数为
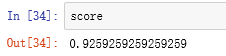
效果还可以。
决策树在此时已经生成,但是不太直观,之后我们进行图像的绘制。将特征和类别命名。
feature_name = ["酒精","苹果酸","灰","灰的碱性","镁","总酚","类黄酮","非黄烷类酚类","花青素","颜色强度","色调","od280/od315稀疏葡萄酒","脯氨酸"]
import graphviz
dot_data = tree.export_graphviz(clf
,feature_names = feature_name
,class_names = ["琴酒","雪莉","贝尔莫得"]
,filled = True #填充颜色
,rounded = True #画出的方块无棱角
)
graph = graphviz.Source(dot_data)
graph
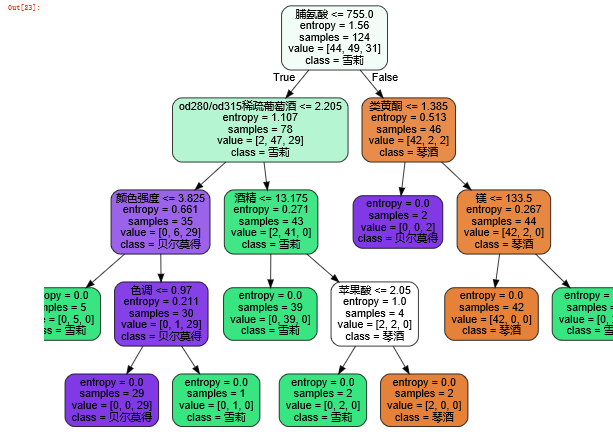
然后运行,我们就可以得到一棵树啦(*^▽^*)。
运行[*zip(feature_name,clf.feature_importances_)] 可以看到每个属性在分类时的比重。得到:
[('酒精', 0.03965653811434505),
('苹果酸', 0.02068204382894391),
('灰', 0.0),
('灰的碱性', 0.0),
('镁', 0.06068969686746859),
('总酚', 0.0),
('类黄酮', 0.061368064261131956),
('非黄烷类酚类', 0.0),
('花青素', 0.0),
('颜色强度', 0.08690808214504504),
('色调', 0.03270487272137427),
('od280/od315稀疏葡萄酒', 0.26633722918973335),
('脯氨酸', 0.4316534728719579)]
可以看到并不是所有的特征都发挥着作用,只有八个特征有比重,且比重最大为脯氨酸,其次是od280/od315稀疏葡萄酒。
random_state & splitter 参数 (可以防止过拟合)
random_state 用来设置分枝中的随机模式的参数,默认为None,在高维度时随机性会表现更明显,低维度数据随机性几乎不会显现。输入任意整数,会一直长出同一棵树,让模型稳定下来。
splitter也是用来控制决策树中的随机选项。"best":决策树在分枝时虽然随机,但是还会优先选择更重要的特征进行分枝。"random"决策树在分枝时会更加随机,树会更深,对训练集的拟合度将会降低。
clf = tree.DecisionTreeClassifier(criterion = "entropy", random_state=10, splitter="random") clf = clf.fit(Xtrain, Ytrain) score = clf.score(Xtest, Ytest) #返回预测的准确度accuracy score
剪枝参数
max_depth 限制树的最大深度,建议从=3开始尝试。
min_samples_leaf 分枝会朝着满足每个子节点都包含min_samples_leaf个样本的方向发生,建议从=5开始。
min_samples_split 一个节点必须要包含至少min_samples_split个训练样本,这个节点才允许被分枝,否则分枝就不会发生。
max_features 限制分枝时考虑的特征个数,超过限制个数的特征会被舍弃。但强行设定这个参数会使模型学习不足。
min_impurity_decrease 限制信息增益的大小,信息增益小于设定数值的分枝不会发生。0.19版本
超参数曲线(确定最优的剪枝参数)
超参数的学习曲线,是一条以超参数的取值为横坐标,模型的度量指标为纵坐标的曲线,它是用来衡量不同超参数取值下模型的表现的线。
引入matplotlib.pyplot库,输入代码
import matplotlib.pyplot as plt
test = []
for i in range(10):
clf=tree.DecisionTreeClassifier(max_depth=i+1
,criterion="entropy"
,random_state=0
,splitter = "random"
)
clf=clf.fit(Xtrain,Ytrain)
score = clf.score(Xtest, Ytest)
test.append(score)
plt.plot(range(1,11),test,color='red',label='max_depth')
plt.legend()
plt.show()
得到: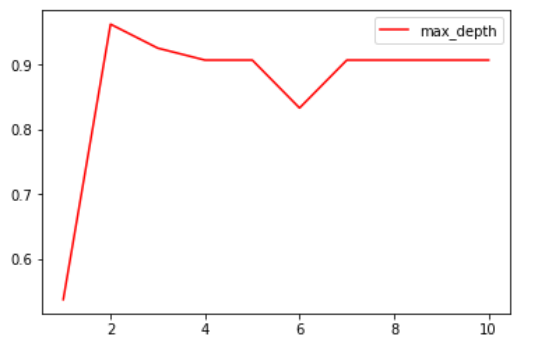
从而能够看到最大深度为多少时得到最高的分数。
目标权重参数
class_weight 完成样本标签平衡的参数。
min_weight_fraction_leaf 基于权重的剪枝参数。
重要属性和接口
对决策树来说,最重要的是feature_importances_,能够查看各个特征对模型的重要性。常用接口还有apply和predict。
#apply 返回每个测试样本所在的叶子节点的索引 clf.apply(Xtest) #predict 返回每个测试样本的分类/回归结果 clf.predict(Xtest)
总结:
七个参数:Criterion,两个随机性相关的参数(random_state,splitter),五个剪枝参数(max_depth, min_samples_split,min_sample_leaf,max_feature,min_impurity_decrease)
一个属性:feature_importances_
四个接口:fit,score,apply,predict
回归树是如何工作的:
from sklearn.datasets import load_boston from sklearn.model_selection import cross_val_score from sklearn.tree import DecisionTreeRegressor boston = load_boston() regressor = DecisionTreeRegressor(random_state=0) cross_val_score(regressor, boston.data, boston.target, cv=10,
# ,scoring = "neg_mean_squared_error" 否则是R平方
) #交叉验证s=cross_val_score的用法
训练集和测试集的划分会干扰模型的结果,因此用交叉验证n次的结果求出平均值,是对模型效果的一个更好的度量。
回归树案例:用回归树拟合正弦曲线
第一步:导入相应的库
import numpy as np from sklearn.tree import DecisionTreeRegressor import matplotlib.pyplot as plt
第二步:创建一条含有噪声的正弦曲线
先创建一组随机的,分布在0-5上的横坐标轴的取值(x),然后利用这些数生成对应正弦y值,接着再到y上去添加噪声。
rng = np.random.RandomState(1) #生成随机数种子 X = np.sort(5 * rng.rand(80,1), axis = 0) #不允许导入一维数据 同时排序 y = np.sin(X).ravel() #降维成一维 y[::5] += 3 * (0.5 - rng.rand(16)) #加上噪声 5为步长 #np.random.rand(数组结构),生成随机数组的函数 #np.xx.ravel() 降维函数,多次降维可降到一维
第三步:实例化&训练模型
regr_1 = DecisionTreeRegressor(max_depth=2) regr_2 = DecisionTreeRegressor(max_depth=5) regr_1.fit(X,y) regr_2.fit(X,y)
第四步:测试集导入模型,预测结果
X_test = np.arange(0.0, 5.0, 0.01)[:, np.newaxis] y_1 = regr_1.predict(X_test) y_2 = regr_2.predict(X_test) #np.arrange(开始点,结束点,步长)生成有序数组的函数 #了解增维切片np.newaxis的用法 l = np.array([1,2,3,4]) l l.shape l[:,np.newaxis] l[:.np.newaxis].shape
第五步:绘制图像
plt.figure()
plt.scatter(X, y, s=20, edgecolor="black", c="darkorange", label="data")
plt.plot(X_test, y_1, color="cornflowerblue", label="max_depth=2", linewidth=2)
plt.plot(X_test, y_2, color="yellowgreen", label="max_depth=5", linewidth=2)
plt.xlabel("data")
plt.ylabel("target")
plt.title("Decision Tree Regression")
plt.legend()
plt.show()
得到图像: