本文资料来源:
Python for Data Anylysis: Chapter 5
10 mintues to pandas: http://pandas.pydata.org/pandas-docs/stable/10min.html#min
文中实例查看地址:http://nbviewer.jupyter.org/github/RZAmber/for_blog/blob/master/learn_numpy.ipynb
1. Pandas简介
经过数年的发展,pandas已经成为python处理数据中最常被使用的package。以下是开发pandas最开始的目的,也是现在pandas最常用的功能
a: Data structures with labeled axes supporting automatic or explicit data alignment(数据调整). This prevents common errors resulting from misaligned data and working with differently-indexed data coming from differernt sources.
b: Integrated time series functionality
c: The same data structures handle both time series data and non-time series data.
d: Arithmetic operations and reductions (like summing across an axis) would pass on the metadata(axis labels,元数据)。
e: Flexible handling of missing data
f: Merge and other relational operations found in popular database databases(SQL-based, for example)
有一篇文章“Don't use Hadoop when your data isn't that big ”指出:只有在超过5TB数据量的规模下,Hadoop才是一个合理的技术选择。所以一般处理<5TB的数据量的时候,python pandas已经足够可以应付。
2. pandas data structure
2.1 Series
Series是一个一维的array-like对象,由两部分组成:1. 任意numpy数据类型的array 2. 数据标签,称之为index。
因此一个series有两个主要参数:values和index
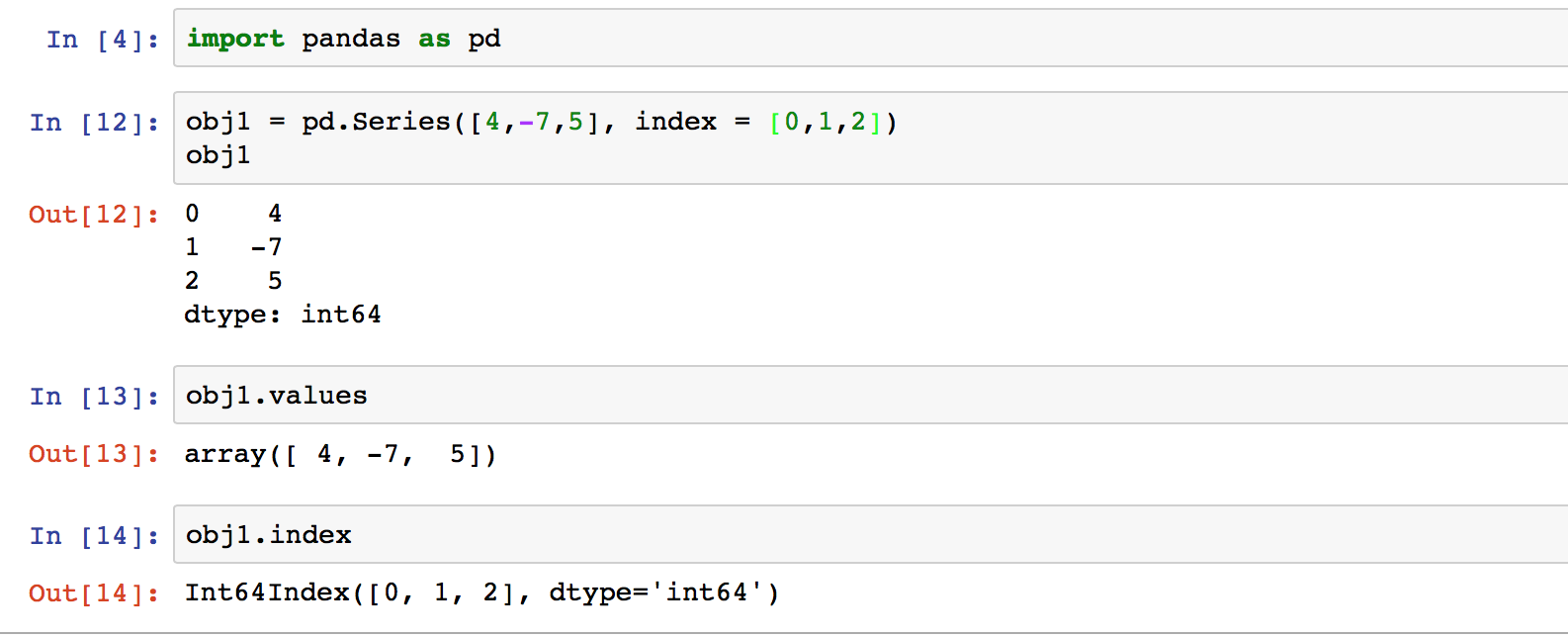
示例为创建一个series,获得其value和index的过程
通过传递一个能够被转换成类似序列结构的字典对象来创建一个Series:
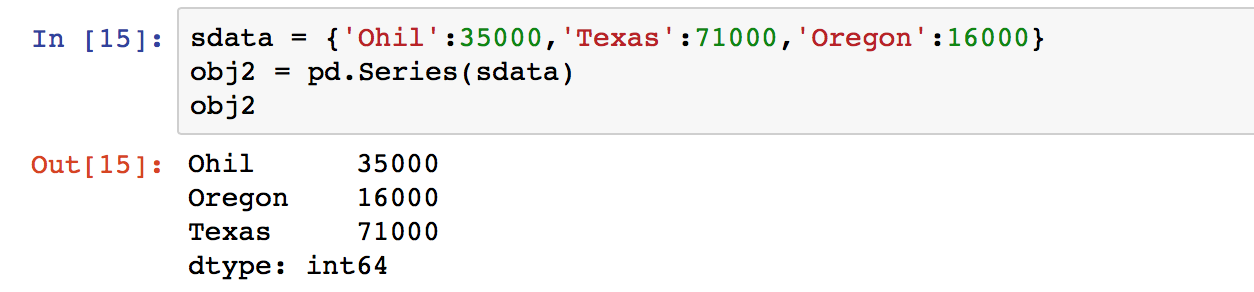
字典的key作为index表示。在Series中还可以加入index参数来规定index的顺序,其value会自动根据key来匹配数值。
Series有一个重要的特征就是:在进行数学运算时,它的对齐特征(Data alignment features)可以自动调整不同index的数据,以便同一种数据进行数学运算。
而且Series对象本身和index参数都有一个参量为name,比如obj.name='population', obj.index.name = 'state'
2.2 DataFrame
DataFrame可以用来表达图表类型、数据库关系类型的数据,它包含数个顺序排列的columns,每个col中的数据类型一致,但是col彼此间数据类型可以不一致。
DataFrame有两个index:row和column
create dataframe的方法:通过同等长度的list或者array或者tuples的dictionary,通过nested dict of dicts, 通过dicts of seires等等,详见书本table5.1

提取列:通过obj3['state']或者obj3.year获取列的信息,返回类型为Series,与DataFrame有同样的index
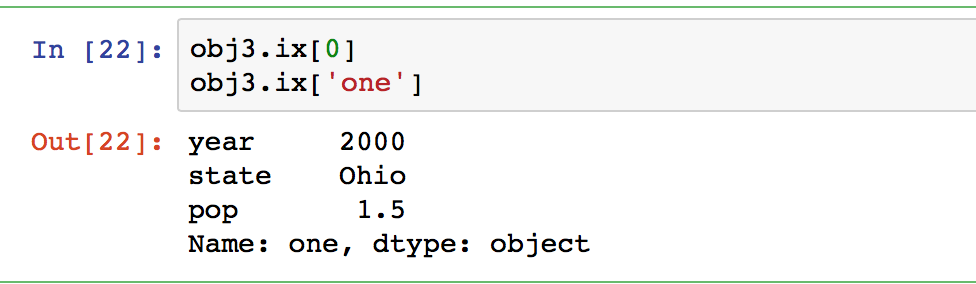
提取row:用ix函数以及row的位置信息或者名字
常用函数:
del:删除列 del obj['year']
常见参数:index和 columns都有name参数,value
2.3 index ojbect和reindexing
pandas index的作用:for holding the axis labels and other metadata(like the axis name or names)
Index对象是不变的,意思就是无法被用户修改,所以下列code无法通过,这个对应了我们简介中所说的a这一条

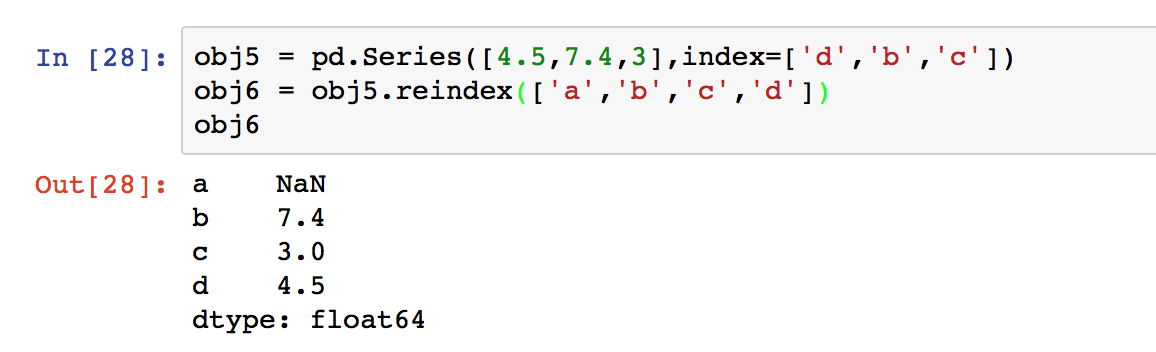
reindex()方法可以对指定轴上的索引(index)进行改变/增加/删除操作,这将返回原始数据的一个拷贝
reindex()中参数介绍:
index:新的index,代替原来的,原来的index不会copy。pandas的处理一般都会自动copy原始value,这点与ndarry不同
method:有ffill和bfill
fill_value:填补NAN value
copy等等
3.查看数据
3.1 sorting:返回一个排序好的object
a:按照轴(行列)进行排序
sort_Index()
参数介绍:默认按照row排序,axis=1即按照列
默认升序,降序ascedning=False
b:按照value排序
order():缺值排在末尾
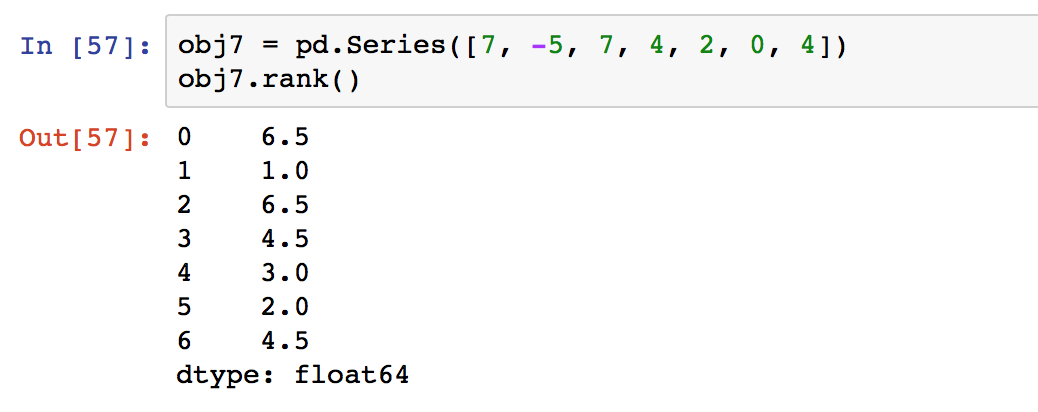
3.2 ranking
rank():按照值出现的顺序赋值,返回一个新的obj。有同样的值的时候,默认返回排序的mean
3.3 unique
is_unique: tell you whether its values are unique or not,返回true or false
unique:返回不重复的值,返回一个array
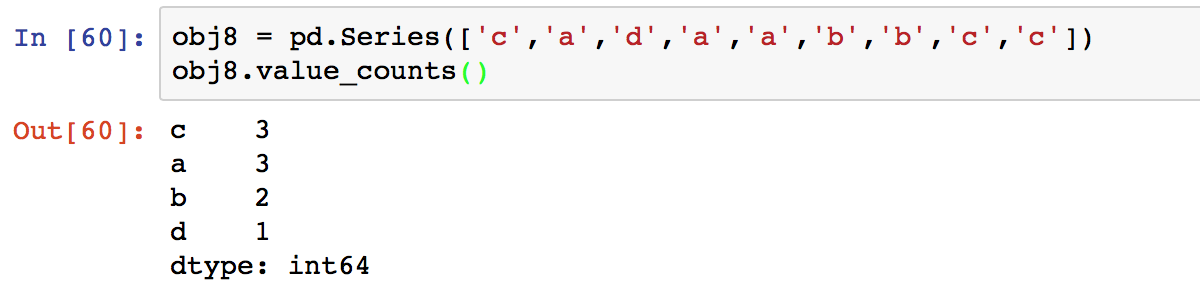
3.4 value_count:计算序列中各个值出现的次数
3.5 describe() 对于数据快速统计汇总
4.选择数据
4.1 drop
drop行:
pandas的处理一般都会自动copy原始value,这点与ndarry不同,举例如下,drop一行之后调用原始对象,发现没有改变

drop列:obj4.drop('Nevada',axis=1)
在python很多函数的参数中,默认都是考虑row的,所以有axis(轴)这个参数
axis=1 为垂直的,即列
axis=0 为水平的,即行
4.2 选择selection,切片slicing,索引index
a: 选择一个单独的列,这将会返回一个Series,df['A'] 和 df.A一个意思
b: 通过[]进行选择,这将会对行进行切片
c: 通过标签选择:endpoint is inclusive 即obj['b':'c']包含‘c'行
d: 选择row和columns的子集:ix
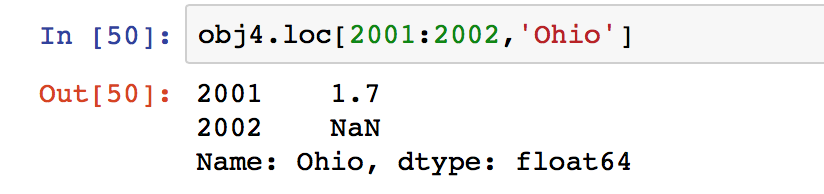
f: 通过标签进行索引: loc
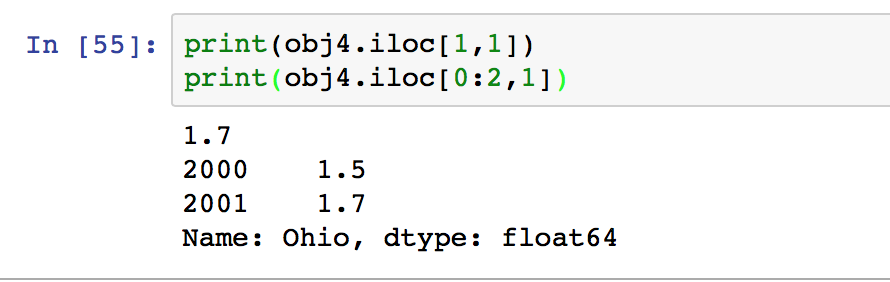
e: 通过位置进行索引: iloc
` 
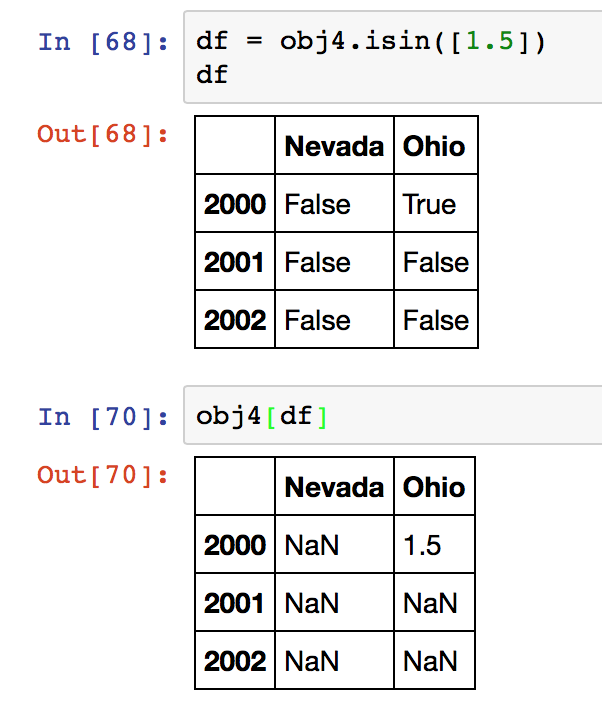
4.3 使用isin()方法来过滤:
用于过滤数据
5.缺失值处理
5.1 missing value
pandas用NaN(floating point value)来表示missing data
5.2 去掉包含缺失值的行或者列
dropna
参数说明:how='all' only drop row that all NA
axis=1, drop column
thresh=3, 只保留还有3个obseration的行
5.3 对缺失值进行填充
fillna
5.4 isnull:返回like-type对象,包含boolean values指明value是否为缺失值
notnull: isnull的反作用
6.计算函数
a:对于不同index的两个df对象相加“+”,其结果与数据库中union类似,缺失值为NaN
b:具体的加减用add()或者sub(),缺失值可以用fill_value代替
c:sum,count,min,max等等,包含一些method
d:correlation and covariance
.corr()
.cov()
7.合并 reshape
8.分组
对于”group by”操作,我们通常是指以下一个或多个操作步骤:
(Splitting)按照一些规则将数据分为不同的组;
(Applying)对于每组数据分别执行一个函数;
(Combining)将结果组合到一个数据结构中;
注:本文并不全面,仅仅总结了目前我所需要的部分。