前言
hadoop 是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。 [ 百度百科 ]
开始
1 .在三个虚拟机中分别下载好 hadoop(3.1.0) 和 java(1.8)
cd /usr/local
wget wget http://download.oracle.com/otn-pub/java/jdk/8u181-b13/96a7b8442fe848ef90c96a2fad6ed6d1/jdk-8u181-linux-x64.tar.gz?AuthParam=1533698216_4d96320e63a975b4cec59c2616d523dd
wget http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-3.1.0/hadoop-3.1.0.tar.gz
mkdir /usr/local/java
mkdir /usr/local/hadoop
tar -zxvf jdk-8u181-linux-x64.tar.gz\?AuthParam\=1533698216_4d96320e63a975b4cec59c2616d523dd -C /usr/local/java
tar -zxvf hadoop-3.1.0.tar.gz -C /usr/local/hadoop
2 .设置各个机器的host,然后重启
vim /etc/hosts
192.168.1.76 hserver1
192.168.1.77 hserver2
192.168.1.78 hserver3
reboot
3 .设置各个机器的ssh互通
vim /etc/ssh/sshd_config
PermitRootLogin yes
ssh-keygen -t rsa
hserver1:
scp /root/.ssh/id_rsa.pub root@hserver2:/root/.ssh/id_rsa_hserver1.pub
scp /root/.ssh/id_rsa.pub root@hserver3:/root/.ssh/id_rsa_hserver1.pub
hserver2
scp /root/.ssh/id_rsa.pub root@hserver1:/root/.ssh/id_rsa_hserver2.pub
scp /root/.ssh/id_rsa.pub root@hserver3:/root/.ssh/id_rsa_hserver2.pub
hserver3:
scp /root/.ssh/id_rsa.pub root@hserver1:/root/.ssh/id_rsa_hserver3.pub
scp /root/.ssh/id_rsa.pub root@hserver2:/root/.ssh/id_rsa_hserver3.pub
hserver1:
cd /root/.ssh
cat id_rsa_hserver2.pub >> authorized_keys
cat id_rsa_hserver3.pub >> authorized_keys
hserver2:
cd /root/.ssh
cat id_rsa_hserver1.pub >> authorized_keys
cat id_rsa_hserver3.pub >> authorized_keys
hserver3:
cd /root/.ssh
cat id_rsa_hserver1.pub >> authorized_keys
cat id_rsa_hserver2.pub >> authorized_keys
ssh连接测试:
ssh hserver2
ssh hserver3
4 .创建三个文件夹
mkdir -p /usr/local/hadoop/hadoop-3.1.0/data/datanode
mkdir -p /usr/local/hadoop/hadoop-3.1.0/data/name
mkdir -p /usr/local/hadoop/hadoop-3.1.0/data/tmp
5 .配置环境变量
vim /etc/profile
export JAVA_HOME=/usr/local/java/jdk1.8.0_181
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.1.0
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
6 .配置hadoop环境变量
cd /usr/local/hadoop/hadoop-3.1.0/etc/hadoop
vim hadoop-env.sh
export JAVA_HOME=/usr/local/java/jdk1.8.0_181
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.1.0
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
7 .设置hadoop文件core-site.xml
vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hserver1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/hadoop-3.1.0/data/tmp</value>
</property>
</configuration>
8 .设置hadoop文件hdfs-site.xml
hserver1:
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>hserver1:9001</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hserver2:9002</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///usr/local/hadoop/hadoop-3.1.0/data/name</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/hadoop-3.1.0/data/datanode</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
hserver2:
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///usr/local/hadoop/hadoop-3.1.0/data/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/hadoop-3.1.0/data/datanode</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
hserver3:
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/hadoop-3.1.0/data/datanode</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
9 .设置hadoop文件mapred-site.xml
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/usr/local/hadoop/hadoop-3.1.0/etc/hadoop,
/usr/local/hadoop/hadoop-3.1.0/share/hadoop/common/*,
/usr/local/hadoop/hadoop-3.1.0/share/hadoop/common/lib/*,
/usr/local/hadoop/hadoop-3.1.0/share/hadoop/hdfs/*,
/usr/local/hadoop/hadoop-3.1.0/share/hadoop/hdfs/lib/*,
/usr/local/hadoop/hadoop-3.1.0/share/hadoop/mapreduce/*,
/usr/local/hadoop/hadoop-3.1.0/share/hadoop/mapreduce/lib/*,
/usr/local/hadoop/hadoop-3.1.0/share/hadoop/yarn/*,
/usr/local/hadoop/hadoop-3.1.0/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>
10 .设置hadoop文件yarn-site.xml
hserver1:
vim yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
hserver2:
vim yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hserver1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hserver1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hserver1:8031</value>
</property>
</configuration>
hserver3:
vim yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hserver1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hserver1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hserver1:8031</value>
</property>
</configuration>
11 .新建文件,设置 第二NameNode 和 集群
hserver1:
cd /usr/local/hadoop/hadoop-3.1.0/etc/hadoop/
vim masters
hserver2
vim workers
hserver2
hserver3
12 .格式化(首次需要格式化hserver1)和启动hadoop
hserver1:
/usr/local/hadoop/hadoop-3.1.0/bin/hdfs namenode -format
cd /usr/local/hadoop/hadoop-3.1.0/sbin
start-all.sh
stop-all.sh
结束
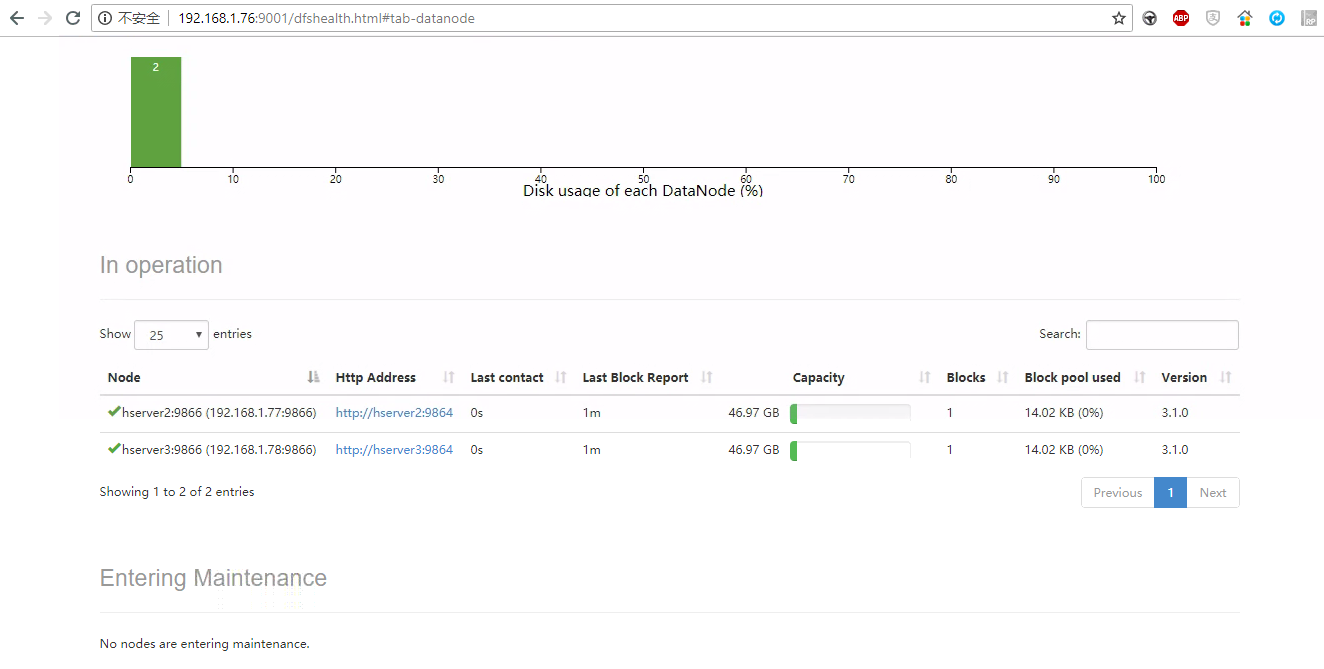
附上图片一张: