Walling up Backdoors in Intrusion Detection Systems “入侵检测系统中的后门壁垒”
written by : Chen Zhu * 1 W. Ronny Huang * 1 Ali Shafahi 1 Hengduo Li 1 Gavin Taylor 2 Christoph Studer 3 Tom Goldstein 1
Abstract
在深度学习(DL)的应用中,投毒攻击和“后门”又引起了研究者们的兴趣。针对卷积神经网络(CNNs),现有研究已经提出了一些成功的防御机制,例如在自动驾驶领域。基于此,本文发现可视化方法可以帮助识别“系统后门”,而并不在意系统所使用的分类器。然而,常见的防御机制在基于DL的入侵检测系统(IDSs)中并不能完全清除这些后门。本文仅设计实现了通过剪枝的方法来删除决策树(DTs)和随机森林(RFs)的后门,并证明了在这两种不同的网络安全数据集上,该剪枝方法的有效性。
Introduction & Related Work
1.为IDS训练ML模型是非常具有挑战性的:(1)数据规模的庞大 和 (2)计算能力的限制,所以现实中我们通常假设这个模型已经被其他“安全组织”训练完成。但这些“组织”并不一定完全值得信任,可能在训练过程中,他们已经为安全系统注入了后门(处于牟利或其他需要)。(3)在受限环境中人工生成训练集,导致无法明确模型应该按照固有特征还是新学习到的特征对流量进行分类。
对于一个性能良好的恶意检测系统来说,需要研究哪些特征是有用的,哪些模式被用以区分攻击流量和正常流量,并需要确定对于这些模式的解释是否符合专家知识。
2.本文整体思路:
(1)提出一种方法,使用UNSWNB15数据集,训练模型检测网络攻击,评估几种特征向量和ML技术在IDSs中的性能。
(2)在模型中添加后门以有效绕过检测。
(3)讨论几种从训练模型中检测或移除后门的技术,并展示了可解释的ML中应用到的可视化技术可以用来检测后门和发现恶意样本在训练集中的分布问题。
(4)发现在图像分类问题中从CNN移除后门的方法对于MLP(多层感知)分类器无效。
(5)为FR分类器(IDSs中最重要的ML方法之一)提出一种新剪枝方法用以移除后门。
3.相关工作
(1)增强DTs的鲁棒性 (2)剪枝技术的应用 (3)微调技术 (4)发现异常(也意味着可能发现后门)
Experiment
1.数据集: UNSW-NB15 CIC-IDS-2017
2.构建MLP(DL):pytorch 5个全连接层,每层512个神经元 ReLU激活函数 dropout = 0.2 二进制交叉熵损失函数
构建RF: scikit-learn 使用100 estimators
3.制作poison: 使用TTL值作为后门的标志,具体方法为 -> 如果数据流的第一个包的TTL小于128,则将其TTL递增1;如果它大于128,则将其TTL递减1。这将造成对标准差、最大/小值的微小改变,成为一个后门。
4.评估:实验结果表示,在不同数据集上,二者都能在保持较高检测率的同时,较准确的识别出后门。

可解释图在本文中的应用:本文受到以下两种图的启发,尝试对模型所做的决策做出解释。
1.Partial Dependence Plots(部分依赖图):需要修改数据集,使得特征值被固定。
X ∈ Rn 代表特征空间中的一个随机向量,f(X) ∈ [0,1]为预测函数,那么在PDP图中,第i个特征Xi可以被表示为:
![]()
注意,此处将观察到的样本点的分布近似看做特征空间的整体分布。那么,给定一个点w,将所有样本点中的第i个特征值修改为w后,再对整个数据集的预测结果进行平均,即可得到第i个特征的PDP。
2.Accumulated Local Effects(局部效应积累图)
由于我们使用真实数据进行模型训练,所以整个特征空间中,存在一些区域的点不太可能出现在样本集中,此时使用PDP就会出现问题,故ALE图仅考虑了那些出现在样本集中的特征分布。那么在ALE图中,第i个特征Xi可以被表示为:
![]()
规定在Xi的定义域内,ALEi(w)的均值为0。对Xi ≈ w的10个样本进行平均来近似X的条件分布。
那么如何使用上述两个图识别后门?即通过计算出两个图,观察图中是否有违反人类直觉的区域。
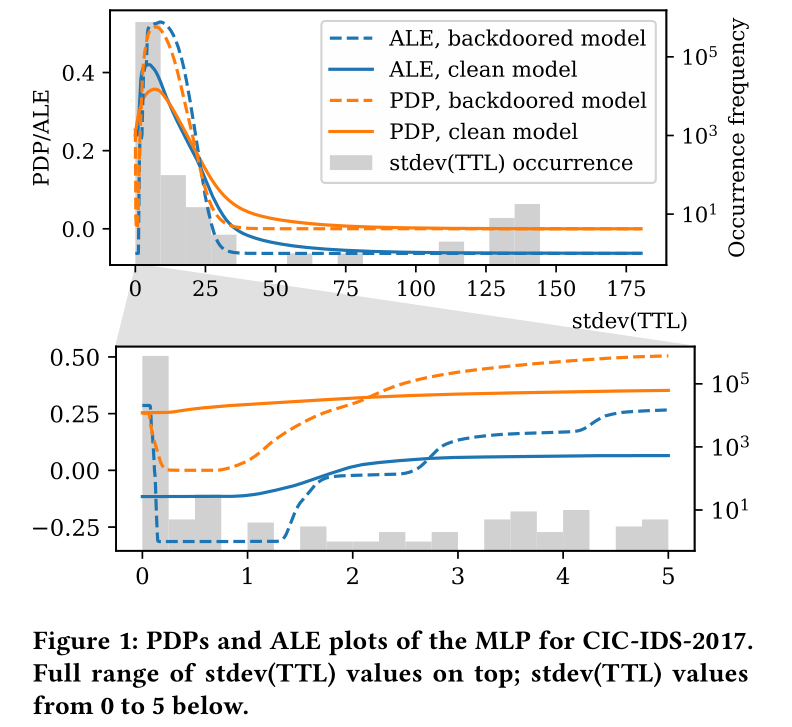
对于该图的解释,存在疑惑点,稍后补充。
注意,反常并不一定是投入后门造成的。本文认为异常流量TTL值分布不均也可能导致这样的结果。但无论如何,这种观察图的机制为我们发现和分析漏洞提供了可能。
DL中投毒的防御
1.剪枝:
数据分配:取训练集中1/4的数据作为验证集,1/4作为测试集以验证后门是否被移除,其余仍作为训练集。(三者中的数据不交叉)
剪枝策略(3种):在激活之前,先将权重和偏差设为0,激活后剪去平均激活值最小(意味着使用次数最少)的取自(1)所有层 /(2)最后一层 /(3)第一层 中的神经元。
但结果显示并没有删掉后门,还发现随着剪枝数量的增加,对于正常流量的识别率也下降了。
分析可能的原因(1)仅考虑二进制均值,对>0的激活值进行平均(2)dropout对结果造成影响 (3)恶意样本远少于良性样本
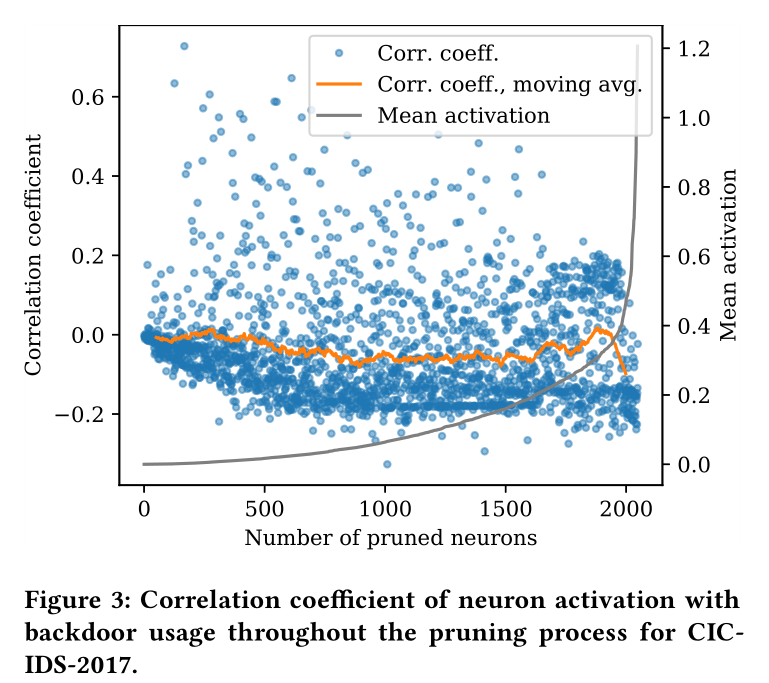
因此本文计算了每个神经元的激活值与数据中存在的后门的相关性。当一个神经元负责后门时,存在后门的情况下,二者应该有很高的相关性,即有后门才活跃,激活值才高。如果剪枝方法有效,那么结果应该是剪枝开始时的神经元相关性高,而后期的神经元相关性低。但如下图所示,出现了相反的情况。该图还表明大多数神经元不但负责后门,还负责正常数据。
2.微调:
本文认为如果微调的计算量和所需的训练集大小都大大低于原始训练过程,那么微调就具有特殊意义。
然而实验发现微调对于清除后门是无效的。事实上,从零开始训练一个模型比微调需要更少的计算量。
本文还尝试了首先应用大量不同的修剪策略,然后再进行微调(精细剪枝)。但实验发现针对CIC-IDSI2017数据集,通过仅修剪第一层的某一部分,后门数量会明显下降,而很大概率上是因为本文后门模式制作的简单性。因此,这种修剪技术普适性是值得怀疑的,即精细修剪也非一个删除后门的可靠方法。
3.RF剪枝:针对RF的剪枝,如果叶节点没有被验证集中的样本所使用,很可能表示该叶节点被后门使用。
策略:
(1)根据用途剪枝,先剪去使用的最少的叶节点,最后剪去使用的最多的。
(2)结合策略(1),同时考虑先剪去那些看起来仅为“良性”的叶节点:攻击者往往希望恶意样本看起来是良性的。
(3)结合策略(2),同时考虑在相同使用情况下先按叶节点的深度剪枝:人工制作的后门所需分类规则少,故它所使用的叶节点有更小的深度。
根据上述策略(3)对UNSW-NB15数据集进行测试,发现随着叶子被修剪后,后门也被清除,同时对于正常流量的识别率不改变,甚至由于过拟,其识别率还会上升。
在CIC-IDS-2017数据集上也有类似的表现,但后门的清除率仅70%左右(可能存在stdev(TTL)>0的正常流量,与异常流量无法进行区分)。
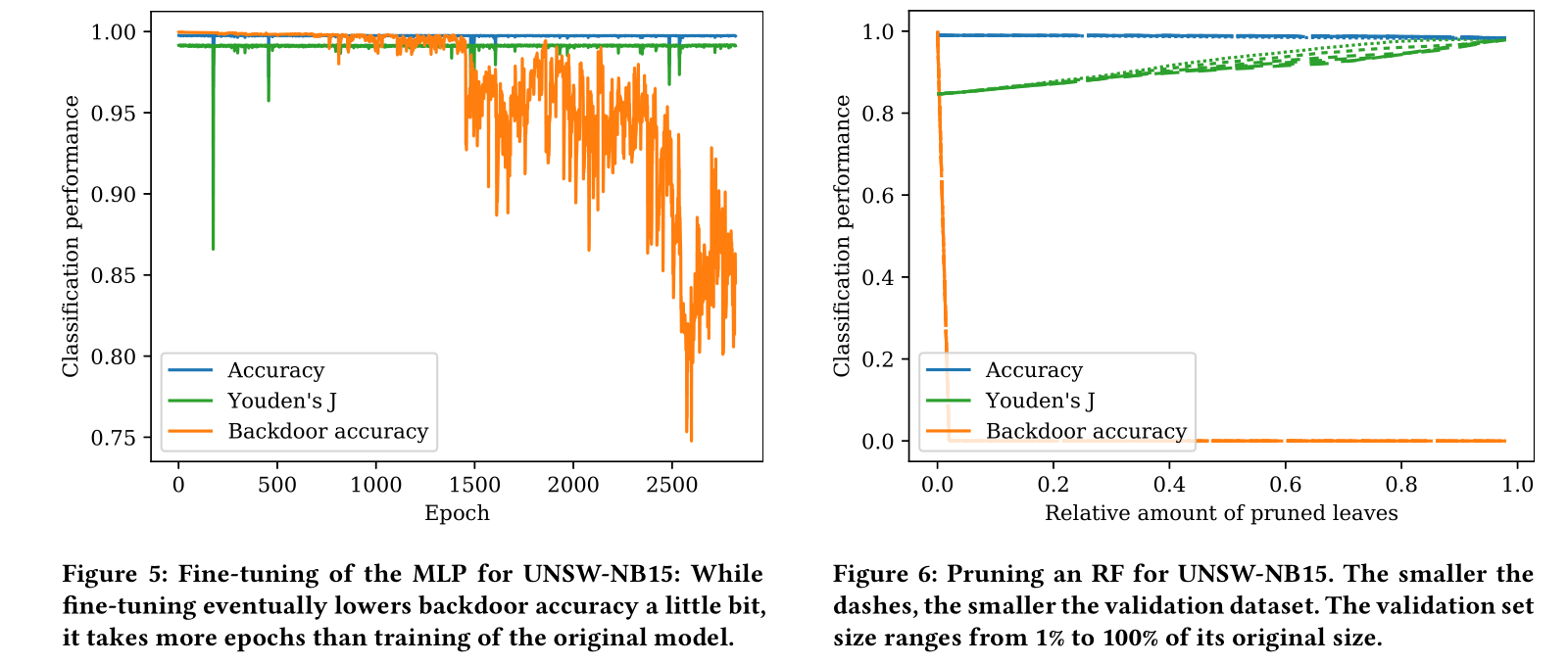
得出结论,优先考虑叶节点深度进行剪枝可以使得后门被尽早的删除。
Discussion:
在使用从第三方获取的ML模型时,我们需要考虑的问题:
1.确保不存在后门:认真分析有问题的模型决策和潜在的非必要特征,可以通过PDP和ALE图进行分析。
2.本文制作后门的方法是改变流量的TTL值,尽量避免改变流量的所有特征值,让模型自己去学习最重要的那一个。
3.本文提出了一个对RF分类器有效的剪枝策略,用以识别和清除后门,同时不改变分类器的性能。因此,建议要在向另一方提供DT或RF分类器时,向其中加入验证集以确保功能。
4.对于在CNN中有效的剪枝和微调方法,并不适用于从本文的DL模型。可能的原因是CNN中仅考虑一部分输入而非全部,故不会改变剪枝的有效性。而本文提出的模型需要考虑全部输入,故无法将这些方法直接迁移入其中。