---恢复内容开始---
一、关联规则概念
关联规则是表示两个项集之间的关联度或相关性的规则,关联规则的形式为A=>B,其中A和B 是两个互斥的项集分别位于规则的左侧(lhs)和右侧(rhs)。
3个常用于选择关联规则的度量是支持度(support)、置信度(confidence)、提升度(lift)。支持度是数据集中既包含项集A又包含项集B的实例所占的百分比,置信度是数据集中包含项集A实例中也包含项集B所占的百分比,提升度是置信度与包含项集B实例的比值
计算式如下所示:
二、在这里我们用Tainic数据集进行描述关联规则
在使用该数据集之前首先 对原始数据进行重构。其代码如下:
1 Titanic 2 str(Titanic) 3 df<-as.data.frame(Titanic) 4 head(df) 5 Titanic.raw<-NULL 6 for(i in 1:4) 7 { 8 Titanic.raw<-cbind(Titanic.raw,rep(as.character(df[,i]),df$Freq)) 9 } 10 Titanic.raw<-as.data.frame(Titanic.raw) 11 names(Titanic.raw)<-names(df)[1:4] 12 dim(Titanic.raw) 13 str(Titanic.raw) 14 head(Titanic.raw) 15 summary(Titanic.raw)###对数据重构
同时我们可以对没有重构与重构之后的Titanic数据进行比较


很明显这两个是不一样的
三、关联规则挖掘
关联规则是一个经典的APRIORI算法,通过对事物计数找出频繁项集,然后再从中推到出关联规则。
下面我们使用函数apriori()进行关联规则挖掘,其中默认值为:最小支持度supp=0.1;最小置信度 ,conf=0.8;最大长度maxlen=10
1 library(arules) 2 rules.all<-apriori(Titanic.raw) 3 rules.all 4 inspect(rules.all)
得到如下的关联规则
> library(arules)
> rules.all<-apriori(Titanic.raw)
Apriori
Parameter specification:
confidence minval smax arem aval originalSupport maxtime support minlen maxlen
0.8 0.1 1 none FALSE TRUE 5 0.1 1 10
target ext
rules FALSE
Algorithmic control:
filter tree heap memopt load sort verbose
0.1 TRUE TRUE FALSE TRUE 2 TRUE
Absolute minimum support count: 220
set item appearances ...[0 item(s)] done [0.00s].
set transactions ...[10 item(s), 2201 transaction(s)] done [0.00s].
sorting and recoding items ... [9 item(s)] done [0.00s].
creating transaction tree ... done [0.00s].
checking subsets of size 1 2 3 4 done [0.00s].
writing ... [27 rule(s)] done [0.00s].
creating S4 object ... done [0.00s].
> rules.all
set of 27 rules
> inspect(rules.all)
lhs rhs support confidence
[1] {} => {Age=Adult} 0.9504771 0.9504771
[2] {Class=2nd} => {Age=Adult} 0.1185825 0.9157895
[3] {Class=1st} => {Age=Adult} 0.1449341 0.9815385
[4] {Sex=Female} => {Age=Adult} 0.1930940 0.9042553
[5] {Class=3rd} => {Age=Adult} 0.2848705 0.8881020
[6] {Survived=Yes} => {Age=Adult} 0.2971377 0.9198312
[7] {Class=Crew} => {Sex=Male} 0.3916402 0.9740113
[8] {Class=Crew} => {Age=Adult} 0.4020900 1.0000000
[9] {Survived=No} => {Sex=Male} 0.6197183 0.9154362
[10] {Survived=No} => {Age=Adult} 0.6533394 0.9651007
[11] {Sex=Male} => {Age=Adult} 0.7573830 0.9630272
[12] {Sex=Female,Survived=Yes} => {Age=Adult} 0.1435711 0.9186047
[13] {Class=3rd,Sex=Male} => {Survived=No} 0.1917310 0.8274510
[14] {Class=3rd,Survived=No} => {Age=Adult} 0.2162653 0.9015152
[15] {Class=3rd,Sex=Male} => {Age=Adult} 0.2099046 0.9058824
[16] {Sex=Male,Survived=Yes} => {Age=Adult} 0.1535666 0.9209809
[17] {Class=Crew,Survived=No} => {Sex=Male} 0.3044071 0.9955423
[18] {Class=Crew,Survived=No} => {Age=Adult} 0.3057701 1.0000000
[19] {Class=Crew,Sex=Male} => {Age=Adult} 0.3916402 1.0000000
[20] {Class=Crew,Age=Adult} => {Sex=Male} 0.3916402 0.9740113
[21] {Sex=Male,Survived=No} => {Age=Adult} 0.6038164 0.9743402
[22] {Age=Adult,Survived=No} => {Sex=Male} 0.6038164 0.9242003
[23] {Class=3rd,Sex=Male,Survived=No} => {Age=Adult} 0.1758292 0.9170616
[24] {Class=3rd,Age=Adult,Survived=No} => {Sex=Male} 0.1758292 0.8130252
[25] {Class=3rd,Sex=Male,Age=Adult} => {Survived=No} 0.1758292 0.8376623
[26] {Class=Crew,Sex=Male,Survived=No} => {Age=Adult} 0.3044071 1.0000000
[27] {Class=Crew,Age=Adult,Survived=No} => {Sex=Male} 0.3044071 0.9955423
lift
[1] 1.0000000
[2] 0.9635051
[3] 1.0326798
[4] 0.9513700
[5] 0.9343750
[6] 0.9677574
[7] 1.2384742
[8] 1.0521033
[9] 1.1639949
[10] 1.0153856
[11] 1.0132040
[12] 0.9664669
[13] 1.2222950
[14] 0.9484870
[15] 0.9530818
[16] 0.9689670
[17] 1.2658514
[18] 1.0521033
[19] 1.0521033
[20] 1.2384742
[21] 1.0251065
[22] 1.1751385
[23] 0.964843
在这我就只是列举一部分。
在关联规则中一个常见的问题是挖掘出来的规则很多是没有意义的,假设我们只对乘客存活感兴趣,那么
2我们可以在appearance中设置rhs=c("Survived=No","Survived=Yes“,确保关联规则的右侧rhs只出现是否存活,同时我们将minlen设置为2
1 rules<-apriori(Titanic.raw,control=list(verbose=F),###压缩过程的细节信息 2 par=list(minlen=2,supp=0.005,conf=0.8), 3 appearance=list(rhs=c("Survived=No","Survived=Yes"), 4 default="lhs")) 5 quality(rules)<-round(quality(rules),digit=3) 6 rules.sorted<-sort(rules,by="lift") 7 inspect(rules.sorted)
其结果为:
inspect(rules.sorted)
lhs rhs support confidence lift
[1] {Class=2nd,Age=Child} => {Survived=Yes} 0.011 1.000 3.096
[2] {Class=2nd,Sex=Female,Age=Child} => {Survived=Yes} 0.006 1.000 3.096
[3] {Class=1st,Sex=Female} => {Survived=Yes} 0.064 0.972 3.010
[4] {Class=1st,Sex=Female,Age=Adult} => {Survived=Yes} 0.064 0.972 3.010
[5] {Class=2nd,Sex=Female} => {Survived=Yes} 0.042 0.877 2.716
[6] {Class=Crew,Sex=Female} => {Survived=Yes} 0.009 0.870 2.692
[7] {Class=Crew,Sex=Female,Age=Adult} => {Survived=Yes} 0.009 0.870 2.692
[8] {Class=2nd,Sex=Female,Age=Adult} => {Survived=Yes} 0.036 0.860 2.663
[9] {Class=2nd,Sex=Male,Age=Adult} => {Survived=No} 0.070 0.917 1.354
[10] {Class=2nd,Sex=Male} => {Survived=No} 0.070 0.860 1.271
[11] {Class=3rd,Sex=Male,Age=Adult} => {Survived=No} 0.176 0.838 1.237
[12] {Class=3rd,Sex=Male} => {Survived=No} 0.192 0.827 1.222
>
二、关联规则可视化
包括散布图、泡泡图。。。。。
其代码如下:
1 library(arulesViz) 2 plot(rules.all) 3 plot(rules.all,method="grouped") 4 plot(rules.all,method="graph") 5 plot(rules.all,method="graph",control=list(type="items")) 6 plot(rules.all,method="paracoord",control=list(reorder=TRUE))
图像分别为:

散布图

泡泡图

有向图

项集有向图
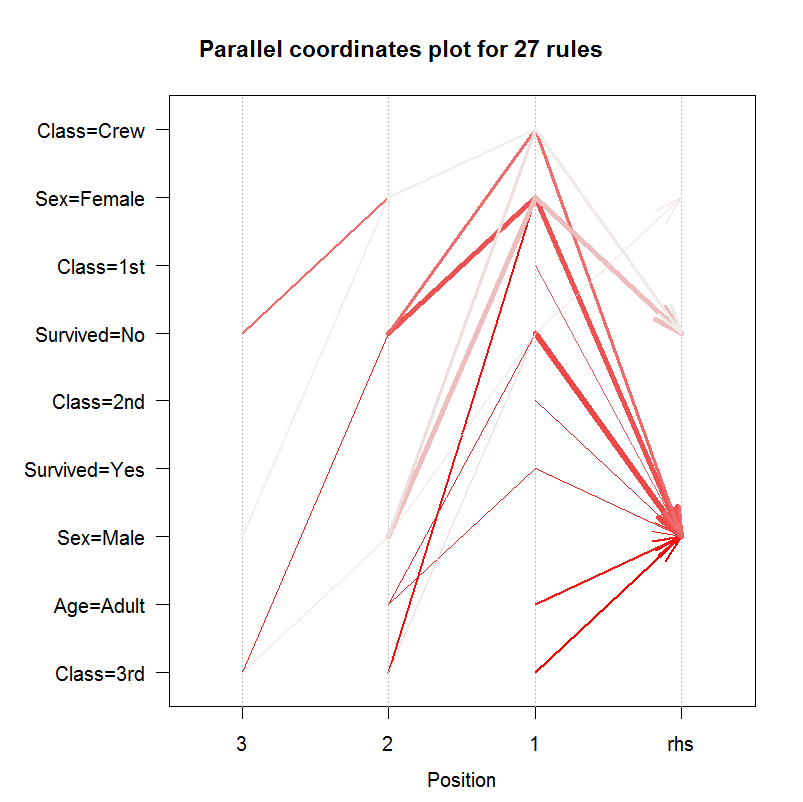
平行坐标图