需求1、找到ip所属区域
描述
http.log:用户访问网站所产生的日志。日志格式为:时间戳、IP地址、访问网址、访问数据、浏览器信息等
ip.dat:ip段数据,记录着一些ip段范围对应的位置
文件位置:data/http.log、data/ip.dat
# http.log样例数据。格式:时间戳、IP地址、访问网址、访问数据、浏览器信息
20090121000132095572000|125.213.100.123|show.51.com|/shoplist.php?phpfile=shoplist2.php&style=1&sex=137|Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; Mozilla/4.0(Compatible Mozilla/4.0(Compatible-EmbeddedWB 14.59http://bsalsa.com/EmbeddedWB- 14.59 from: http://bsalsa.com/ )|http://show.51.com/main.php|
# ip.dat样例数据
122.228.96.0|122.228.96.255|2061787136|2061787391|亚洲|中国|浙江|温州||电信|330300|China|CN|120.672111|28.000575
要求
将 http.log 文件中的 ip 转换为地址。如将 122.228.96.111 转为 温州,并统计各城市的总访问量
详解
1.解析http.log文件,获取该文件的IP地址
2.解析IP.dat文件,获取每个城市对应的IP网段
3.通过数据将http.log的IP地址替换为城市名称,并通过城市去重累加个数;
package com.lagou.homework import org.apache.spark import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.broadcast.Broadcast import org.apache.spark.rdd.RDD object Homework { def main(args: Array[String]): Unit = { //定义sparkContext val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName(this.getClass.getCanonicalName) val sc = new SparkContext(conf) //设置日志级别 sc.setLogLevel("warn") /** * 数据计算 */ //采用RDD:读取 http.log文件 val httpData: RDD[Long] = sc.textFile("data/http.log") .map(x => ipConvert(x.split("\|")(1))) //读取IP配置文件 val ipData: Array[(Long, Long, String)] = sc.textFile("data/ip.dat") .map { line => val field: Array[String] = line.split("\|") (field(2).toLong, field(3).toLong, field(6)) }.collect() val ipBC: Broadcast[Array[(Long, Long, String)]] = sc.broadcast(ipData.sortBy(_._1)) //逐条数据比对,找到对应的城市。使用二分查找 val results: Array[(Any, Int)] = httpData.mapPartitions { iter => val ipsInfo: Array[(Long, Long, String)] = ipBC.value iter.map { ip => val city: Any = getCityName(ip, ipsInfo) (city, 1) } }.reduceByKey(_ + _) .collect() results.sortBy(_._2) .foreach(println) //关闭连接 sc.stop() } //定义一个IP转换函数 192.168.10.2 -- 192.168.25.3 def ipConvert(ip: String): Long = { val arr: Array[Long] = ip.split("\.") .map(_.toLong) var ipLong: Long = 0L for (i <- arr.indices) { val ans: Long = scala.math.pow(255, i).toLong ipLong += arr(i) * ans } ipLong } //寻找IP对应的城市 def getCityName(ip: Long, ips: Array[(Long, Long, String)]): String = { var start = 0 var end: Int = ips.length - 1 var middle = 0 while (start <= end) { middle = (start + end) / 2 if ((ip >= ips(middle)._1) && (ip <= ips(middle)._2)) return ips(middle)._3 else if (ip < ips(middle)._1) end = middle - 1 else start = middle + 1 } "Unknown" } }
结果验证
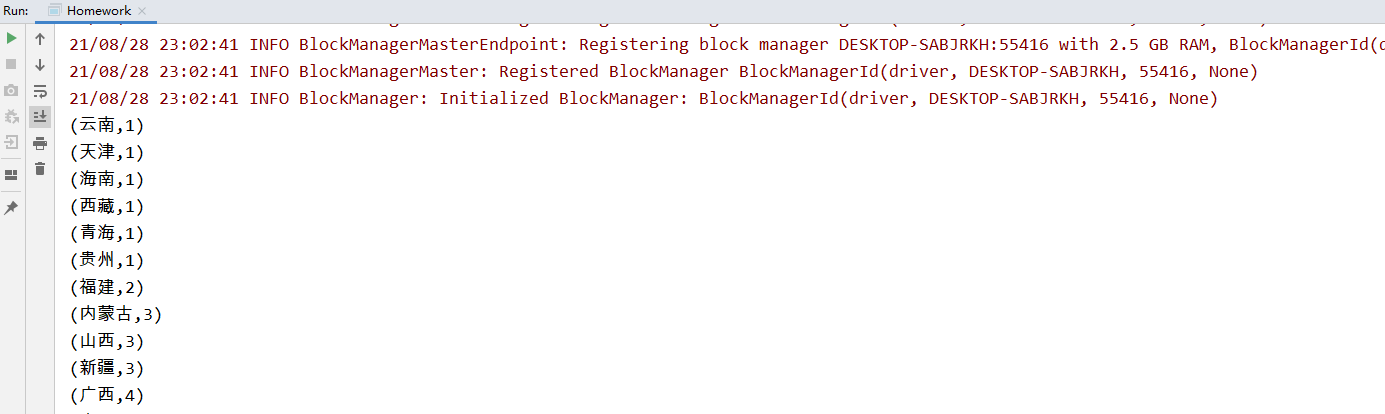
需求2 日志分析
日志格式:IP 命中率(Hit/Miss) 响应时间 请求时间 请求方法 请求URL 请求协议 状态码 响应大小referer 用户代理
日志文件位置:data/cdn.txt
~~~
100.79.121.48 HIT 33 [15/Feb/2017:00:00:46 +0800] "GET http://cdn.v.abc.com.cn/videojs/video.js HTTP/1.1" 200 174055 "http://www.abc.com.cn/" "Mozilla/4.0+(compatible;+MSIE+6.0;+Windows+NT+5.1;+Trident/4.0;)"
~~~
术语解释:
PV(page view),即页面浏览量;衡量网站或单一网页的指标
uv(unique visitor),指访问某个站点或点击某条新闻的不同IP地址的人数
要求
2.1、计算独立IP数
2.2、统计每个视频独立IP数(视频的标志:在日志文件的某些可以找到 *.mp4,代表一个视频文件)
2.3、统计一天中每个小时的流量
详解
package com.lagou.homework import java.util.regex.{Matcher, Pattern} import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object Homework2 { //正则表达式:符合视频格式的正则 val ipPattern: Pattern = Pattern.compile("""(S+) .+/(S+.mp4) .*""")
//正则表达式 val flowPattern: Pattern = Pattern.compile(""".+ [(.+?) .+ (200|206|304) (d+) .+""") def main(args: Array[String]): Unit = { //定义sparkContext val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName(this.getClass.getCanonicalName) val sc = new SparkContext(conf) //设置日志级别 sc.setLogLevel("warn") /** * 数据计算 */ //解析数据 val dataRDD: RDD[String] = sc.textFile("data/cdn.txt") // 1.获取独立的IP数 val results: RDD[(String, Int)] = dataRDD.map(x => (x.split("\s+")(0), 1)) .reduceByKey(_ + _) .sortBy(_._2, ascending = false, 1) println("----------独立IP数------------------") results.take(10).foreach(println) println(s"独立IP数:${results.count()}") // 2.统计每个视频独立IP数 //匹配正则,查找视频链接 val videoRDD: RDD[((String, String), Int)] = dataRDD.map(line => { val matcherFlag: Matcher = ipPattern.matcher(line) if (matcherFlag.matches()) { ((matcherFlag.group(2), matcherFlag.group(1)), 1) } else { ((" ", " "), 0) } }) // ((141081.mp4,125.116.211.162),1) //计算每个视频的独立ip数 val result2: RDD[(String, Int)] = videoRDD.filter { case ((video, ip), count) => video != "" && ip != "" && count != 0 } .map { case ((video, ip), _) => (ip, video) } .distinct() .map { case (_, video) => (video, 1) } .reduceByKey(_ + _) .sortBy(_._2,ascending = false,1) println("----------每个视频的独立IP数------------------") result2.foreach(println) //3.统计一天中每个小时的流量 val flowRDD: RDD[(String, Long)] = dataRDD.map(line => { val matchFlag: Matcher = flowPattern.matcher(line) if (matchFlag.matches()) (matchFlag.group(1).split(":")(1), matchFlag.group(3).toLong) else ("", 0L) }) println("----------每小时流量------------------") flowRDD.filter { case (hour, flow) => flow != 0 } // 数据量很小,可以收到一个分区中做reduce,然后转为集合操作效率高 .reduceByKey(_ + _, 1) .collectAsMap() // 响应大小更换单位为 g .mapValues(_ / 1024 / 1024 / 1024) .toList // 根据小时排序 .sortBy(_._1) .foreach { case (k, v) => println(s"${k}时 CDN流量${v}G") } //关闭资源 sc.stop() } }
结果验证
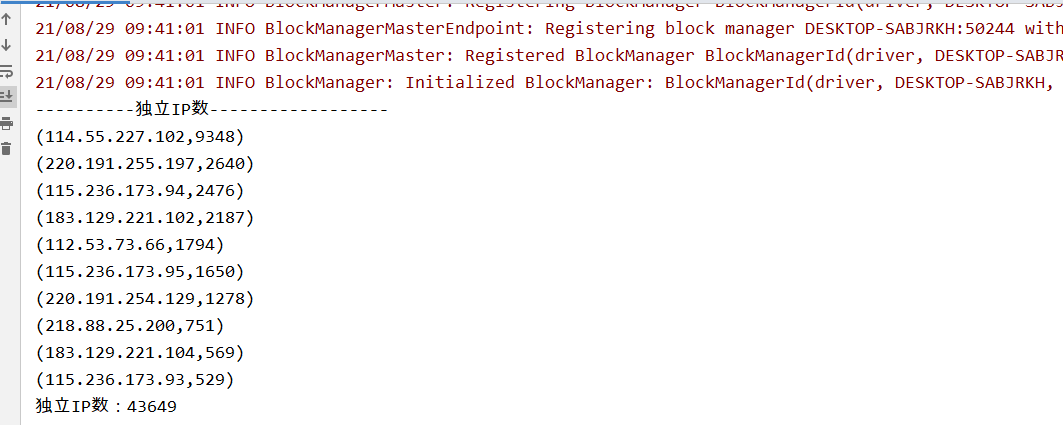
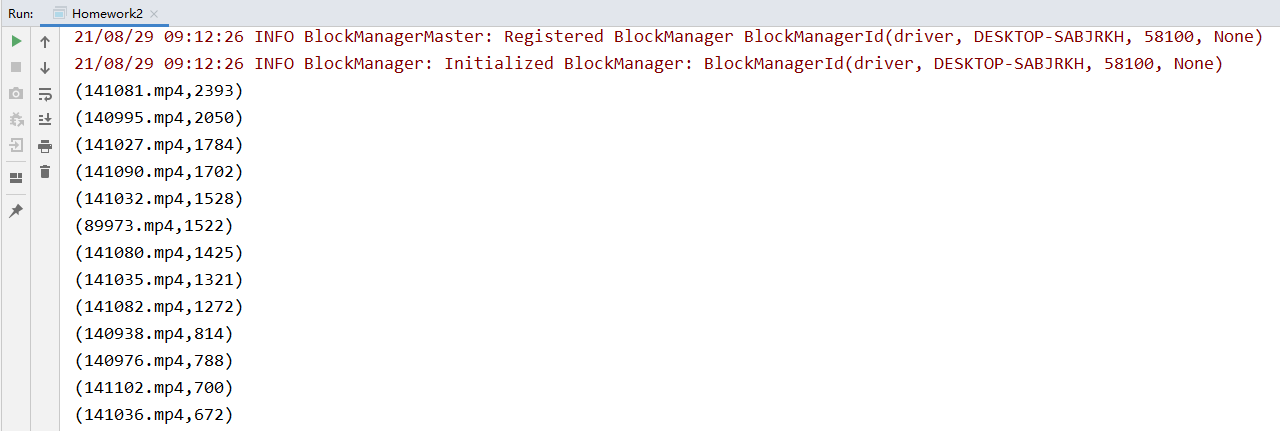

3、Spark面试题
假设点击日志文件(click.log)中每行记录格式如下:
~~~
INFO 2019-09-01 00:29:53 requestURI:/click?app=1&p=1&adid=18005472&industry=469&adid=31
INFO 2019-09-01 00:30:31 requestURI:/click?app=2&p=1&adid=18005472&industry=469&adid=31
INFO 2019-09-01 00:31:03 requestURI:/click?app=1&p=1&adid=18005472&industry=469&adid=32
INFO 2019-09-01 00:31:51 requestURI:/click?app=1&p=1&adid=18005472&industry=469&adid=33
~~~
另有曝光日志(imp.log)格式如下:
~~~
INFO 2019-09-01 00:29:53 requestURI:/imp?app=1&p=1&adid=18005472&industry=469&adid=31
INFO 2019-09-01 00:29:53 requestURI:/imp?app=1&p=1&adid=18005472&industry=469&adid=31
INFO 2019-09-01 00:29:53 requestURI:/imp?app=1&p=1&adid=18005472&industry=469&adid=34
~~~
需求
3.1、用Spark-Core实现统计每个adid的曝光数与点击数,将结果输出到hdfs文件;
输出文件结构为adid、曝光数、点击数。注意:数据不能有丢失(存在某些adid有imp,没有clk;或有clk没有imp)
3.2、你的代码有多少个shuffle,是否能减少?
(提示:仅有1次shuffle是最优的)
详解
package com.lagou.homework import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object Homework3 { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setAppName(this.getClass.getCanonicalName).setMaster("local[*]") val sc = new SparkContext(conf) sc.setLogLevel("warn") val clickLog: RDD[String] = sc.textFile("data/click.log") val impLog: RDD[String] = sc.textFile("data/imp.log") // 读文件:点击日志 val clkRDD: RDD[(String, (Int, Int))] = clickLog.map { line => val arr: Array[String] = line.split("\s+") val adid: String = arr(3).substring(arr(3).lastIndexOf("=") + 1) (adid, (1, 0)) } // 读文件:曝光日志 val impRDD: RDD[(String, (Int, Int))] = impLog.map { line => val arr: Array[String] = line.split("\s+") val adid: String = arr(3).substring(arr(3).lastIndexOf("=") + 1) (adid, (0, 1)) } // join val RDD: RDD[(String, (Int, Int))] = clkRDD.union(impRDD) .reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2)) // 写hdfs RDD.saveAsTextFile("hdfs://linux121:9000/data/") sc.stop() } }
结果验证
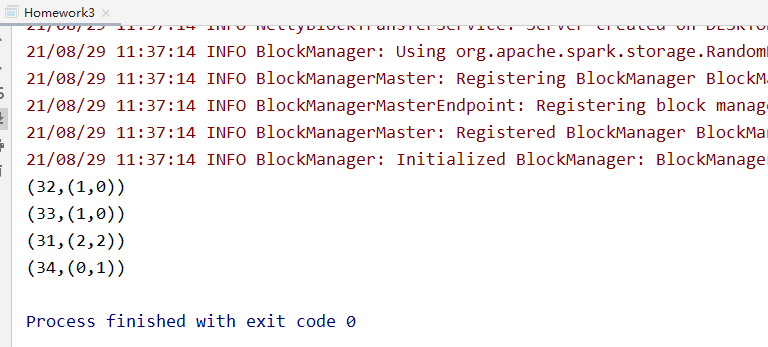
需求4,spark SQL题目
描述:
A表有三个字段:ID、startdate、enddate,有3条数据:
1 2019-03-04 2020-02-03
2 2020-04-05 2020-08-04
3 2019-10-09 2020-06-11
写SQL(需要SQL和DSL)将以上数据变化为:
2019-03-04 2019-10-09
2019-10-09 2020-02-03
2020-02-03 2020-04-05
2020-04-05 2020-06-11
2020-06-11 2020-08-04
2020-08-04 2020-08-04
详解
package com.lagou.homework import org.apache.spark.SparkContext import org.apache.spark.sql.expressions.{Window, WindowSpec} import org.apache.spark.sql.{DataFrame, Row, SparkSession} object Homework4 { def main(args: Array[String]): Unit = { //初始化:创建sparkSession 和 SparkContext val spark: SparkSession = SparkSession.builder() .appName(this.getClass.getCanonicalName) .master("local[*]") .getOrCreate() val sc: SparkContext = spark.sparkContext sc.setLogLevel("warn") //spark SQL 导包 import spark.implicits._ import org.apache.spark.sql.functions._ val df: DataFrame = List("1 2019-03-04 2020-02-03", "2 2020-04-05 2020-08-04", "3 2019-10-09 2020-06-11").toDF() //DSL操作 val w1: WindowSpec = Window.orderBy($"value" asc).rowsBetween(0, 1) println("-------------------DSL 操作----------------") df.as[String] .map(str => str.split(" ")(1) + " " + str.split(" ")(2)) .flatMap(str => str.split("\s+")) .distinct() .sort($"value" asc) .withColumn("new", max("value") over (w1) ) .show() //SQL操作 println("-------------------sql 操作----------------") df.flatMap{case Row(line: String)=> line.split("\s+").tail }.toDF("date") .createOrReplaceTempView("t1") spark.sql( """ |select date,max(date) over(order by date rows between current row and 1 following) as date1 | from t1 |""".stripMargin).show //关闭资源 spark.close() } }
结果验证
