文章转自 白月黑羽教Python
原理
说到web应用自动化测试,第一选择就是 Selenium 框架。
Selenium 是一个 Web 应用的自动化框架。
通过它,我们可以写出自动化程序像人一样(在浏览器里)操作web界面。 比如点击界面按钮,在文本框中输入文本,甚至一些拖拽操作,滚动界面的操作。
并且能够从web界面获取信息。 比如获取某个区域的文字内容,从而通过自动化程序进行分析处理。
Selenium3.0 的自动化架构是这样的
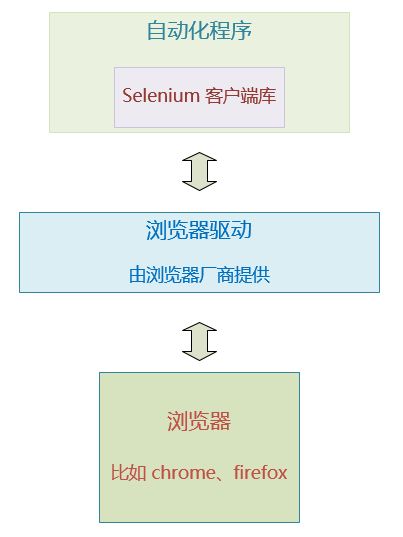
从上图可以看出:
我们写的自动化程序 需要使用一个Selenium组织提供的 客户端库。
我们程序的自动化请求都是通过使用这个库的接口对象完成的。 比如调用某个元素对象的click方法, 就会发送点击这个元素的请求给 下方的浏览器驱动。
这个自动化程序的请求是通过客户端库,构建出相应的HTTP请求,发送给浏览器驱动的。
浏览器驱动 也是一个独立的程序,是由浏览器厂商提供的, 不同的浏览器需要不同的浏览器驱动。 比如 Chrome浏览器和 火狐浏览器有 各自不同的驱动程序。
浏览器驱动接收到我们的自动化程序发送过来的界面操作请求后,会转发请求给浏览器, 让浏览器去执行对应的自动化操作。
浏览器执行完操作后,会将自动化的结果返回给浏览器驱动, 浏览器驱动再通过http响应的消息返回给我们的自动化程序的客户端库。
自动化程序的客户端库 接收到响应后,将结果转化为 数据对象 返回给我的自动化程序代码。我们的程序就可以知道这次自动化操作的结果如何了。
上述自动化的往返流程都是在我们的程序对Selenium客户端库的调用和返回之间发生的事情。
Selenium组织提供了多种主流编程语言的Selenium客户端库, 方便不同编程语言的开发者使用。
安装
Selenium环境的安装主要就是安装两样东西: 客户端库 和浏览器 驱动
安装客户端库
不同的编程语言选择不同的Selenium客户端库。
对应我们Python语言来说,Selenium客户端库的安装非常简单,用pip 命令即可。
打开 命令行程序,运行如下命令
pip install selenium
安装浏览器驱动
不同的浏览器选择不同的浏览器驱动。
目前来说,主流的浏览器就是 Chrome 和 火狐。 而 Chrome 浏览器对Selenium自动化的支持目前来说更加成熟一些。
我们就以Chrome浏览器为例。
Chrome 浏览器的驱动在谷歌的网站上。大家都知道,谷歌的网站,我们国内访问只能呵呵了。
当然,如果你能科学上网,那么可以访问下面的链接, 获取最新版本的chrome浏览器驱动
https://sites.google.com/a/chromium.org/chromedriver/downloads
点击下图箭头处,下载最新驱动

注意浏览器驱动 必须要和浏览器版本匹配,如上图红圈里面的声明。
比如:当前Chrome驱动版本是2.37, 支持的Chrome浏览器版本号是 64 到 66 之间都可以。
为了方便不能科学上网的朋友获取最新驱动。
白月黑羽会一直为大家在这里提供Windows版本上最新的驱动下载。大家只需点击下方链接即可
下载链接:Chrome驱动2.37版,支持Chrome浏览器64-66
这是个zip包,下载下来之后里面的程序文件 chromedriver.exe 解压到某个目录下面,注意这个目录的路径最好是没有中文名和空格的。
建议大家解压到 d:webdrivers 目录下面。
也就是保证我们的Chrome浏览器驱动路径为 d:webdriverschromedriver.exe
安装好以后,如何 使用Python语言结合Selenium编写 Web 自动化呢
访问原文网站,看 下一篇 操作web界面