【阿里云产品公测】简单日志服务SLS使用评测 + 教程
评测介绍
- 被测产品: 简单日志服务SLS
- 评测环境: 阿里云基础ECS x2(1核, 512M, 1M)
- 操作系统: CentOS 6.5 x64
- 日志环境: Nginx(v1.6.2) HTTP服务器访问日志、服务器系统日志
- 评测人: mr_wid
- 评测时间: 2014年9月28日-2014年10月8日
准备工作
一、知彼知己, 百战不殆。对产品的了解程度, 直接决定着评测质量, 在评测前, 笔者首先整理并详细阅读了有关SLS产品以及关联产品的官方相关文档:
二、Nginx HTTP服务器准备:
在真实的HTTP服务器应用场景中, 为了降低磁盘I/O、单一宽带下的访问瓶颈限制, 通常会将图片、静态文件与用户访问的主服务器进行服务器分离, 从而提高网站响应速度与负载能力。 在本次的评测中, 使用了两台基础 ECS 服务器, 将其中一台作为图片服务器, 另一台作为用户访问的主服务器进行测试。 这两台服务器的环境配置如下:
- 主服务器: CentOS + Nginx + MySQL + PHP
- 图片服务器: CentOS + Nginx
SLS使用起步
一、创建Access Key
在 SLS 服务中, 由于 SLS 客户端 Logtail 与 SLS 的SDK 均需要Access Key的支持, 所以需要保证云服务器所在账号下至少存在一个启用状态的AccessKey, 创建Access Key的过程:
登录阿里云官网(http://www.aliyun.com/), 进入"用户中心" -> "我的服务" 页面, 在左侧栏 "安全认证"(https://i.aliyun.com/access_key/) 页面即可创建本账号下的Access Key, 如图:

其中, Access Key ID 与 Access Key Secret 即组成一对Access Key。
二、创建SLS项目
在SLS控制面板, 选择 "创建Project" 并输入项目名称, 如图所示创建一个名为 "sls-test-project" 的SLS项目。

创建完成后如图:

三、创建SLS项目日志分类
SLS日志类型(Category), 即对所要监测的日志进行分类, 分类规则应至少遵循同一分类下的日志具有相同的日志格式这一规则。
以 Nginx 的 Access Log 日志为例, 创建名为 "nginx-access-log" 的SLS日志类型。进入上一步创建的 "sls-test-project" SLS项目管理页, 选择 "创建Category", 如图:

在日志数据消费模式选项, 为了更全面的评测SLS, 我们将离线归档到ODPS选项也勾选上。点击 "确定", 创建完成后将会提示是通过 Logtail 客户端收集日志还是通过SLS的SDK API
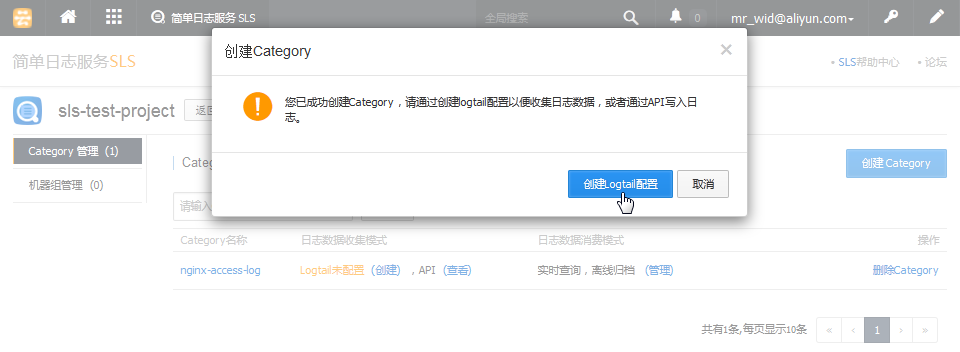
Logtail 是一个运行在 UNIX/Linux 上的日志收集程序, API可以通过SLS提供的API对日志进行写入、查询等操作。这里我们选择 创建Logtail配置。

在指定日志目录结构这一步, 根据服务器的配置填入nginx的日志路径, 由于nginx自身并不会对日志文件进行分割, 所以这里仅监控 access.log 文件。对于自动分割型日志, 可用通配符进行监控, 如日志被分割为 access.log、access-1.log、access-2.log、..., 使用通配符 access*.log
在日志样例项, 可以从已有的日志文件中随机抽取一条或多条日志, 进入下一步。

在解析日志这一步, 需要用到正则表达式来对日志进行结构划分, 在这之前, 首先来看一下Nginx的详细日志结构, 在 nginx.conf 里可以通过自己的需求对日志样式进行自定义, 这里的配置如下:
log_format main $remote_addr - $remote_user [$time_local] "$request" $status $body_bytes_sent "$http_referer" "$http_user_agent";
对应着示例中的日志, 对这条配置文件进行下解释:
| 日志字段 | 与样例中对应部分 | 字段解释 |
|---|---|---|
| $remote_addr | 113.64.66.49 | 客户端的ip地址 |
| - | - | 仅作分隔符 |
| $remote_user | - | 客户端用户名称 |
| [$time_local] | [17/Aug/2014:15:24:13 +0800] | 访问请求时间 |
| "$request" | "GET /article/centos-64bit-nginx-php-fastcgi-opcache-mariadb HTTP/1.1" | 记录请求方式、请求的url与所用http协议 |
| $status | 200 | 请求响应状态 |
| $body_bytes_sent | 35177 | 响应主体大小 |
| "$http_referer" | "http://www.x86pro.com/" | 请求来源页面地址(从哪个页面链接访问过来的) |
| "$http_user_agent" | "Mozilla/5.0 (X11; Linux i686; rv:24.0) Gecko/20100101 Firefox/24.0" | 用户客户端相关信息 |
匹配日志各字段的正则表达式规则如下:
^(d{1,3}.d{1,3}.d{1,3}.d{1,3})s-s(.*)s[(.*)]s"(.*)"s(d{3,})s(d+)s"([^s]*)"s"(.*)"$
关于正则表达式, 这里需要一些正则的基础, 对正则不是很熟悉的同学, 建议参考相关的文章对正则表达式有个大致的理解, 推荐《正则表达式30分钟入门教程》, 这里仅解释一下与这条正则有关的部分:
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结束 |
| () | 将括号内的部分作为一个整体 |
| 转义符 | |
| d | 匹配一个数字 |
| {m,n} | 重复匹配 m 到 n 次, 例 d{1,3} : 匹配长度为 1-3 的数字 |
| s | 匹配任意空白符, 如普通空格、 、 、 |
| . | 匹配除换行符以外的任意字符 |
| + | 重复一次或更多次 |
在 时间格式转换项, 由于软件写入的日志时间格式可能不同, 所以需要按照一定的规则, 把时间格式手动转换成SLS能够认识的格式, 详细转换方式以及转换选项参见 简单日志服务 › 常见问题 › 时间格式转换文档。
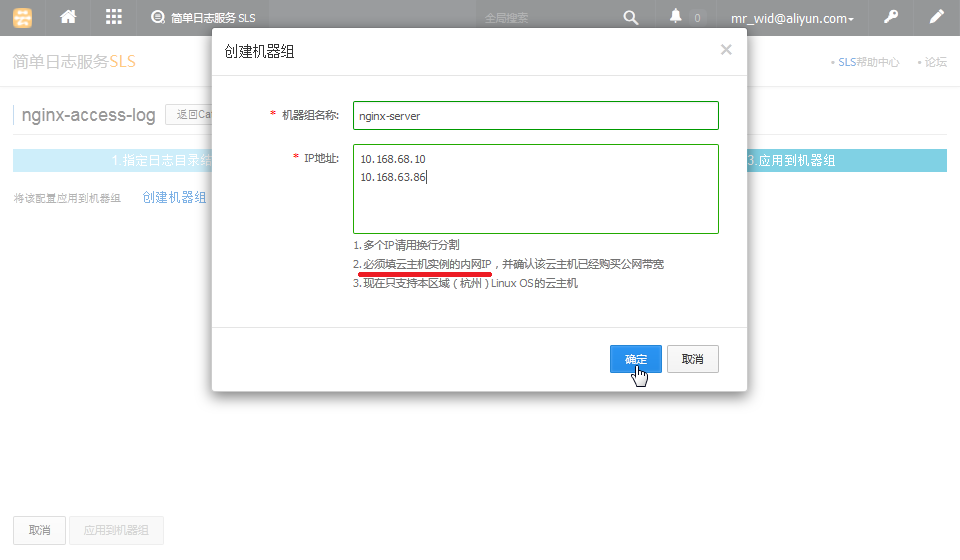
接下来的两步, 按照提示创建机器组, 然后应用到机器组就可以了, 这里不再赘述, 过程如图所示:


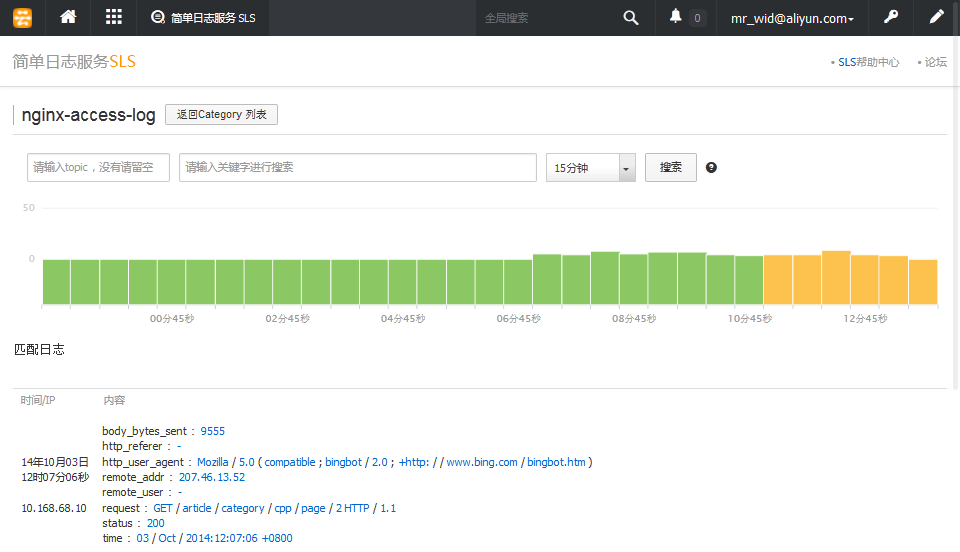
约1分钟后,日志数据开始显示。
SLS日志查询
在如图所示的搜索栏中, 即可执行SLS查询语句, 示例语句: 查询15分钟内所有响应状态为 404 的请求:

从示例的查询结果中 request 字段可以看到, 内网IP为10.168.68.10的网站根目录下缺少 robots.txt文件, 10.168.63.86图片服务器缺失 /images/productimages/frontcol.jpg 文件, 从而产生了404, 针对这些有问题的404的页面, 我们就可以及时对其进行改进。如果再结合SLS提供的逻辑查询语法, 对日志的常规分析可谓是变得十分轻松便捷。
对查询语句的说明: 在 "status 404" 查询语句中, 表示要被查询的日志项中, 既有 'status' 关键字, 也有 '404' 关键字, 这是按关键字匹配, 并且被搜索的关键字不区分大小写, 并不是指 'status' 的值为 '404' 的日志, 这一点十分重要, 不要误解。
那么在 "status 404", 的搜索结果中, 是否全部都是 status 为 404 的结果呢? 答案是否定的, 例如在某日志中 body_bytes_sent 为 404, 那么该日志同样会被检索显示出来。 如图:
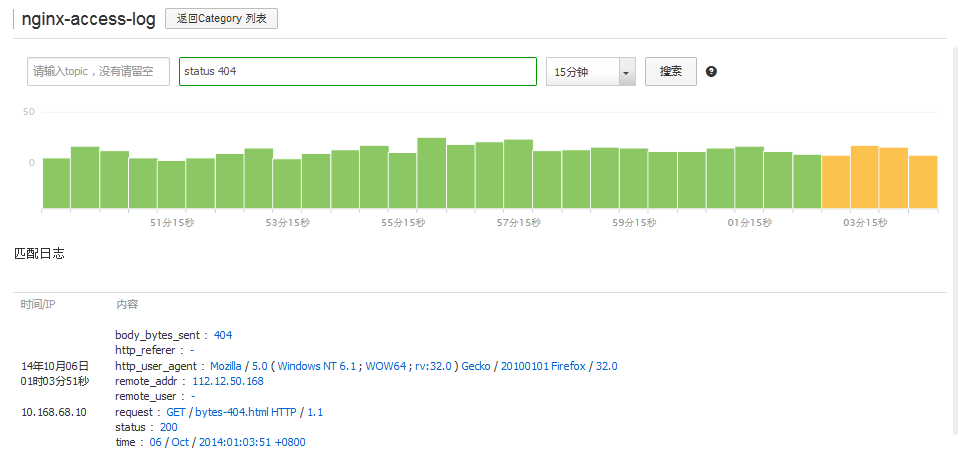
这并不是bug, 而是笔者最初时的理解有误, 认为 status 404 就会在所以日志的 status 字段中查找(实际上在这里加或不加 status 关键字对结果并无影响, 笔者仅为了说明这个问题), 针对这点, 笔者也会在评测的最后提出相关的建议, 建议增加相关的查询规则, 这里暂且按下不表。
SLS日志查询语句语法目前保留的关键字有and、or、not(不区分大小写) 以及 小括号()、双引号 " 与反斜杠 , 并且这些关键词具有优先级之分, 优先级的顺序为 " > ( ) > and not> or, (and 与 not 为同级), 优先级的高低决定着关键字之间查询的结合方向。这类似于加减乘除四则运算中, 当加减同时出现在一个式子中时先算乘除法, 再算加减法, 若有括号, 先算括号里面的,对于这些查询关键词的用法, 可以用一些示例来说明:
查询状态为404的页面, 并且被请求资源为 robots.txt 的日志: 404 and robots.txt
查询用户浏览器类型为火狐或Chrome的日志: Firefox or Chrome
查询请求响应状态码除 200 和 304 外的日志: not 200 not 304
双引号 " 的用法: 用一对双引号括起来的内容表示一个字符串, 任何在字符串内的内容, 都将被当做一个整体, 可用来转义关键字, 如:
查询日志中含有 and 字符的日志: "and"
转义符 的用法: 用来转义关键字中的双引号 ", 单单一个 " 则为SLS查询语法中的关键字, 但加上 " 进行转义后, 便表示双引号自身, 示例用法:
查询所有请求中带 双引号 的日志: "
日志的关键字在哪
在上面多次提到SLS是按关键字进行查询的, 并且这个关键字由SLS自动划分, 目前无法手动干预, 那么如何才能知道自己搜索的是不是关键字就成了搜索时所遇到的问题, 根据笔者的测试, 在日志结果中, 将鼠标移动到搜索结果上, 能显示为手型的部分, 即为一个独立的关键字, 如图:

只有了解了这点, 才能更好的使用查询, 举例来说, 当我们想搜索来源于 Google 的请求, 假设Google的蜘蛛都来自 http://www.google.com/, 那么我们搜索 google 或 google.com 是不能正确的显示出预期的结果的, 因为 google 和 google.com 并没有被SLS划分为关键字, www.google.com 才是正确的关键字。
关于 Topic
日志离线归档到ODPS
在配置 SLS日志数据消费模式时, 当勾选了离线归档到ODPS, 日志数据就会自动归档到ODPS的 sls_log_archive 项目中, 然后我们可方便的对日志数据进行下载、备份、数据分析等操作。
由于该项目是系统项目, 并不会显示在ODPS的控制面板项目列表中, 需要通过 ODPS 客户端、 ODPS 上传下载客户端 进行操作, ODPS客户端目前提供的是JAVA版本, 需要JAVA的JRE环境支持, 所以如果没有安装JRE环境的, 需要先安装JRE运行环境才能使用,官方文档中推荐 JRE 1.6(http://www.oracle.com/technetwork/java/javase/downloads/java-archive-downloads-javase6-419409.html#jre-6u45-oth-JPR)。除客户端外, ODPS同样也支持通过JAVA SDK API进行编程化操作。ODPS Java SDK开发包
完整的 ODPS 参考文档见 ODPS用户手册
配置ODPS客户端
将下载的OSPD客户端 odps-cli-java.zip 解压后, 进入 conf 目录, 编辑配置文件 odps.conf, 填入一组创建Access Key中生成的 Access Key ID 与 Access Key Secret, 并指定默认ODPS项目
access.id=你的 Access Key ID access.key=你的 Access Key Secret endpoint=http://service.odps.aliyun.com/api default.project=sls_log_archive
配置完成后, 进入ODPS的bin目录, Windows系统执行 odps.bat, Linux执行odps, 以Windows环境为例, 直接双击 odps.bat 即可 进入ODPS命令行操作界面:

配置ODPS上传下载客户端
将下载的 odps-dship.zip 解压, 笔者的解压路径为 D:SlsEnvodps-dship, 进入odps-dship目录, 编辑 odps.conf
#Odps dship config #Wed Oct 08 13:39:54 CST 2014 tunnel-endpoint=http://dt.odps.aliyun.com (杭州节点内网对内网可用 http://dt-ext.odps.aliyun-inc.com) key=你的 Access Key Secret project=sls_log_archive (默认项目) id=你的 Access Key ID
tunnel-endpoint配置说明参见: ODPS数据上传下载相关问题 > 使用ODPS tunnel或者dship下载数据时,如何设置endpoint更合理?
打开命令提示符, 切换到 odps-dship 目录下, 执行 Windows 执行dship.bat, Linux执行dship, 如图:
查看 sls_log_archive 项目中指定表的信息
以创建的示例日志分组 nginx-access-log 为例, 该分组在ODPS中的表名称为 sls_test_project_nginx_access_log (Project名+Category名), 在ODPS命令行中, 命令:
desc sls_test_project_nginx_access_log

表中各列的介绍(摘自文档)
| 序号 | 列名 | 类型 | 备注 |
| 1 | __source__ | string | 日志来源IP,SLS保留字段 |
| 2 | __time__ | bigint | 日志产生的UNIX时间戳,SLS保留字段 |
| 3 | __topic__ | string | 日志topic,SLS保留字段 |
| 4 | _extract_others_ | string | Json字符串,半结构化的用户日志以key:value形式保存到该列 |
| 5 | __partition_time__ | string(pt) | 可读的日期格式,分区列,由__time__计算得到,例如2014_06_24_12_00 |
这里有一点需要注意的是, 表中的 __partition_time__ 字段, 这是一个"分区"字段, 可以类似理解为一个独立的文件夹, 并且命名方式是以 2014_10_08_12_00 的形式, 以小时为单位递增, 稍后在使用上传下载工具下载日志数据时, 将会用到该字段。
按 __partition_time__ 分区下载日志数据
odps的上传下载工具, 目前只支持下载到单个文件, 并且每一次下载只支持下载一个表或一个分区到一个文件, 有分区的表必须要指定下载的分区才能正常下载。示例, 下载2014年10月7日20时的SLS nginx_access_log 分类中的日志数据并命名为 access_log_1410072000.txt:
dship download sls_log_archive.sls_test_project_nginx_access_log/__partition_time__="2014_10_07_20_00" access_log_1410072000.txt 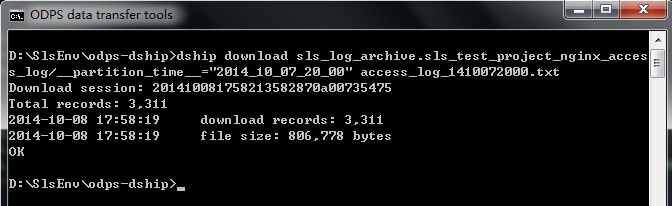
为了提高下载效率以及完成批量下载等操作, 建议使用ODPS的SDK进行编出化下载, 或者编写可执行脚本, 如bat、Python等, 用脚本调用ODPS的命令来实现。
查看原文:http://bbs.aliyun.com/read/178909.html
微博互动:http://weibo.com/1644971875/Br41E1xSE#_rnd1413011556756
参加活动:http://promotion.aliyun.com/act/aliyun/freebeta/
