发表在 ICML 2017
动机
AE 和 RNN 很难捕捉到 隐空间的语义表示,因此不适用于从任意hidden层表示形式生成通用文本,而相较于视觉领域,使用深度生成模型(VAEs、GANs、auto-regressive)在文本生成上还有许多的限制,很大情况下是任意的以及不可控的。本篇文章尝试通过学习具有指定语义的解缠的潜在表示来控制句子属性,从而生成高质量合理的句子。
方法
提出了一个新的生成模型,结合了变分自编码器(VAEs)和属性鉴别器(discriminators),可以有效地施加语义结构。它可以看作是使用 wake-sleep 算法来增强 VAEs,该算法利用 fake samples 作为额外的训练数据,通过对离散文本样本进行可区分的近似,对独立属性控件的显式约束以及对生成器和判别器的有效协作学习,模型甚至能仅从单词级别的注释中学习可解释的表示形式,并生成具有所需属性(情感和时态)的句子 。
wake-sleep 算法:
原文:https://www.zhihu.com/question/29648549
https://blog.csdn.net/zouxy09/article/details/8775518


挑战
-
文本是离散的:由此产生的不可微阻碍了使用全局判别器来评估生成的样本和反向传播梯度,从而难以用整体方式指导生成器的优化,而这在连续图像生成和表示建模中被证明是非常有效的
solution:
采用 policy learning,但训练或连续逼近过程中会出现高方差
采用 半监督的 VAEs ,作为基于判别器学习的替代方法,最大程度地减少了观察实例上的元素重构误差,并适用于离散文本,但这会丢失完整句子的整体视图,尤其对于建模全局抽象属性而言(如: sentiment)
-
如何学习解缠的潜在表示(disentangled latent representation)
关于结构化表示学习的先前方法:缺乏对完整潜在表示的独立性的显式实施,并且单独编码的变化可能会导致除期望值之外的其他未指定属性的意外变化
solution:允许高度分散的具有指定语义结构的表示形式,并生成具有动态指定属性的句子
模型结构

非结构化变量 z:将样本 x 送入编码器中,得到 z,我们通过强制将那些无关的属性完全捕获在非结构化代码 z 中,从而将它们与我们将要操纵的 c 分开来得到独立性。
结构化变量 c:具有可解释的表示形式,意味着 c 中的每个结构化代码都可以独立控制其目标特征,而不会与其他属性(尤其是未明确建模的属性)纠缠在一起。
在上下文中应用鉴别器的困难在于文本样本是离散且不可微的,并且会破坏从鉴别器到生成器的梯度传播。使用基于 softmax 的连续逼近方法,并减小 temperature ,随着训练的进行,该方法会逐渐逼近离散情况。 这种简单而有效的方法可以得到低方差和快速收敛。
为此,作者将 VAEs 编码器重新用作识别 z 建模属性的附加标识符,并对生成器进行训练,以便可以从生成的样本中恢复这些非结构化属性。 结果,只要 z 不变,即使改变不同的属性代码,非结构化属性也会保持不变。
即,生成器和鉴别器形成一对协作学习者,并相互提供反馈信号。 协同优化类似于 wake-sleep 算法。 VAE /wake-sleep 学习的组合可实现高效的半监督框架,该框架仅需进行少量监督即可获得可解释的表示形式和生成方式
形式化表示
x 为观测到的序列:
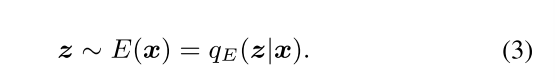
非结构化变量 z 被建模为具有标准高斯先验 p(z)的连续变量,而结构化代码 c 包含连续变量和离散变量,以使用适当的先验编码不同的属性(如 sentiment、categories、formality) p(c)(先验知识)
生成器:
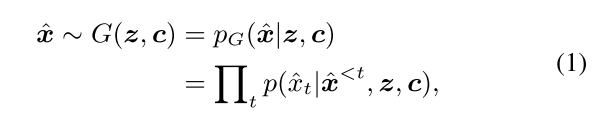

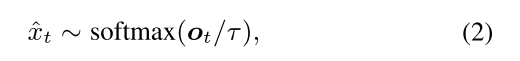
qD(c | x)是鉴别器 D 为 c 中每个结构变量定义的条件分布
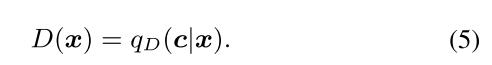
损失函数
令 θG 和 θE 分别表示生成器 G 和编码器 E 的参数。 然后对 VAE 进行优化,以最大程度减少观察到的真实句子的重构误差,并同时将编码器规则化为接近先前的p(z):
重构损失:
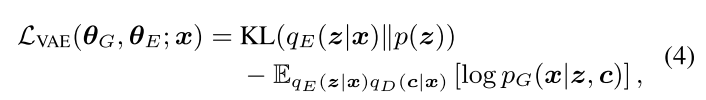
当我们学习解缠表示时,将(z,c)因子分布到 qE 和 qD 中,但此处的鉴别器 D 和代码 c 不会因 VAE 损失而学习,而是针对简短描述的目标进行了优化,除了驱动生成器产生逼真的句子的重构损失之外,鉴别器还提供了额外的学习信号,这些信号使生成器产生了与 c 中的结构化代码相匹配的连贯属性。但是,由于不可能通过鉴别器从离散样本传播梯度,因此作者采用了确定性连续逼近法。
近似值将等式(2)中的概率矢量替换了生成器的参数,从而将每一步的采样 token (表示为一个 one-hot 向量)替换。概率向量用作当前步骤的输出,以及决策过程中下一步的输入。 结果生成 “soft” 的句子,表示为Gτ(z,c),被反馈给鉴别器以测量对目标属性的适应度,从而导致以下损失,从而提高了G
生成器(结构化变量 c)损失:

因此,概率向量的作用是在词嵌入矩阵,以获得每个步骤的“soft”词嵌入
随着训练的进行,temperature τ(Eq.2)设置为τ→0,从而产生越来越多的峰值分布,最终模拟了离散情况
但是,仍有可能未明确建模的其他属性也可能与 c 中的代码纠缠在一起,因此更改 c 的尺寸可能会产生我们不感兴趣的这些属性的意外变化
为了解决这个问题,引入了独立性约束,该约束通过强制非结构化变量 z 完全捕获这些属性而将它们与 c 分开,因此,除了用 c 显式编码的属性外,还训练生成器,以便可以从生成的样本中正确识别其他非显式属性,并匹配非结构化代码 z,作者没有使用新的判别器,而是重用了可变编码器E。 损失的形式与公式(6)相同,只是用编码器的条件 qE 代替了判别器的条件qD
生成器(非结构变量 z)损失:
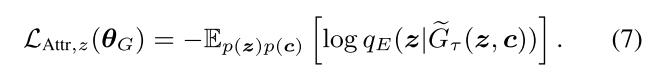
整个模型的损失:
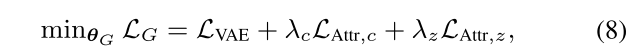
判别器的学习
判别器 D 经过训练可以准确地推断句子属性并评估潜在代码中指定的恢复所需特征的错误。例如,对于分类属性,可以将判别器表述为属性分类器; 对于连续目标,可以使用概率回归。
此外,与以无监督方式学习的非结构化代码 z 相比,结构化变量 c 使用带标签的示例来包含指定的语义
带标签的样本 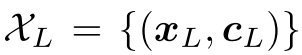
判别器损失:
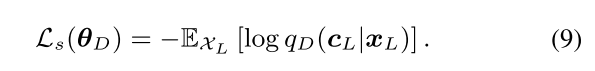
此外,生成器 G 还能够合成(噪音)句子属性对(ˆx,c),该属性对可用于增强训练数据以进行半监督学习
为了缓解噪音数据的问题并确保模型优化的稳健性,引入了最小熵正则化项

其中H(qD(c‘ | ˆx))是在生成的句子ˆx上评估的经验q分布的香农熵; β是平衡参数
整体损失:
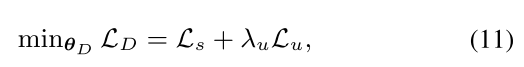
算法

实验
属性:sentiment and tense
句子长度 <= 15
数据集:
IMDB:movie reviews(350K)
处理:选择句子长度不超过15个单词,并使用 ’
Sentiment(positive or negative)
- SST-full(Stanford Sentiment Treebank-2): 6920/872/1821(train/dev/test) movie review
- SST-small: 研究在半监督学习中进行准确属性控制所需的标记数据的大小,从SST-full中抽取了一个小子集,仅包含250个标记的句子
- Lexicon:单词级标签进行句子级控制来研究模型的有效性。词典包含2700个带有情感标签的单词。 通过将单词视为句子来使用词典进行训练,并在 SST-full 测试集上进行评估
- IMDB:随机采样 5K/1K/10K
Tense(past or present or future)
句子中的时态主要是由动词或时间词所决定
- TimeBank: 带有标签的5250个词汇集
方法比较:
评价指标:Accuracy(通过分类器计算)
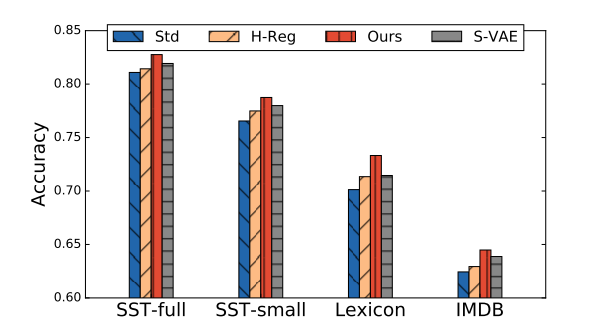
- Std: 训练好的卷积网络
- H-Reg:对生成的句子施加最小熵正则化
- Ours:结合了最小熵正则化和生成句子的情感属性代码c
- S-VAE:半监督的 VAE(可以理解成重构回原句子)
源代码
https://github.com/asyml/texar/tree/master/examples/text_style_transfer