这篇论文发在 2018 年的 ACL 上
Motivation
在社交媒体上,常会出现一些攻击性的语言,这给我们的社交环境带来了很不良的影响,作者基于此提出一种将攻击性的语言转换成非攻击性语言的模型
Method
由于不存在平行语料,采用的是无监督学习,作者提出了一种结合 collaborative classifier 、注意力机制和 cycle consistency loss 的编码器-解码器的新方法。
整个模型结构设计的还是蛮简单的,如下图(为了能够更清楚的表达,作者用来多个编码器-解码器、分类器来说明,在实际实验时,都只有一个):
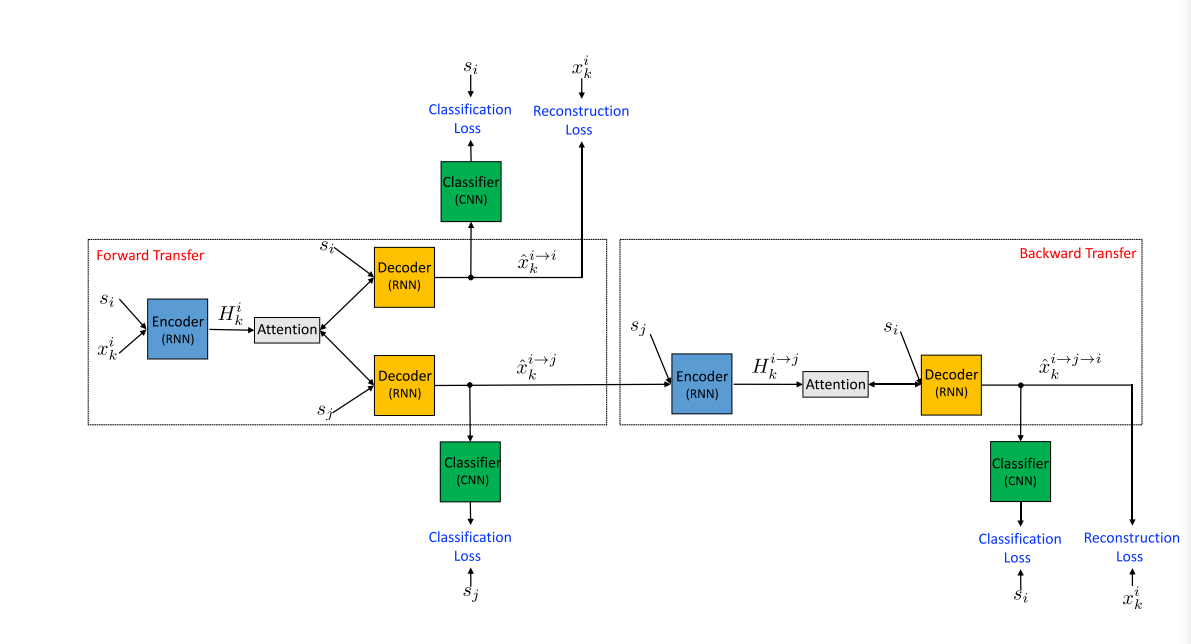
s_i 表示 label ,i ∈ {0,1}, k 表示第几个句子
模型框架主要是 编码器-解码器(RNN),然后中间加入了 注意力机制,分类器使用的是 CNN
损失函数(交叉熵)
-
Forward Transfer
-
重构损失(i --> i)
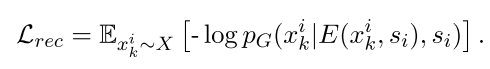
-
分类损失(i -- > i): 有监督学习(可作为对比)
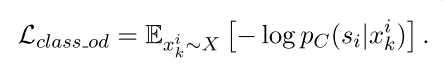
-
分类损失(i -- > j)
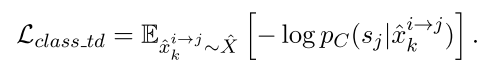
-
-
Backward Transfer(相当于回翻:i -- > j -- > i)
也就是希望能将转换后的句子再转换回啦
-
重构损失(i --> j -- > i)
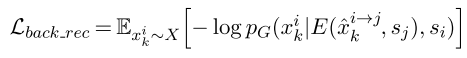
-
分类损失(回翻后)
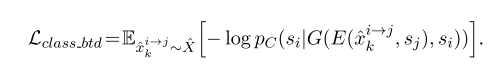
-
实验
数据集:Twitter 和 Reddit
对比实验(baseline):Shen et al. Style transfer from non-parallel text by cross-alignment.