系统环境
1、操作系统:64位CentOS6.5
2、jdk版本:1.8.0_111
3、zookeeper版本:zookeeper-3.4.9.tar.gz
4、scala版本:scala-2.11.11
5、三台服务器:192.168.204.100; 192.168.204.101; 192.168.204.102;
下载kafka
网址:http://kafka.apache.org/downloads
版本:kafka_2.11-0.9.0.0(因为scala是2.11版本,所以kafka也要下载2.11版本)
参考博文:http://blog.csdn.net/wang_zhenwei/article/details/48357131
- broker.id:Kafka broker 的唯一标识,集群中不能重复。
- port: Broker 的监听端口,用于监听 Producer 或者 Consumer 的连接。
- host.name:当前 Broker 服务器的 IP 地址或者机器名。
- zookeeper.contact:Broker 作为 zookeeper 的 client,可以连接的 zookeeper 的地址信息。
- master节点上
broker.id=0
port=9092
host.name=master
advertised.host.name=master
num.partitions=2
zookeeper.connect=master:2181,slave1:2181,slave2:2181
- slave1节点
broker.id=1
port=9092
host.name=slave1
advertised.host.name=slave1
num.partitions=2
zookeeper.connect=master:2181,slave1:2181,slave2:2181
- slave2节点
broker.id=2
port=9092
host.name=slave2
advertised.host.name=slave2
num.partitions=2
zookeeper.connect=master:2181,slave1:2181,slave2:2181
(这里master,slave1和slave2可以对应服务器地址,这是因为我之前在 vim /etc/hosts配置过了。如果没有配置,可以换。例如master是192.168.204.100)
8.启动kafka
master、slave1和slave2分别都要启动(切记都要三台节点都要启动,这点和zookeeper是一样的)
切换到kafka目录
cd /home/hadoop/kafka
sh bin/kafka-server-start.sh config/server.properties
(也可以这样,看你切换到哪一级目录
cd /home/hadoop/kafka/bin
sh kafka-server-start.sh config/server.properties
)
9.查看命令:jps(slave1和slave2节点也可以看一下kafka是否启动)
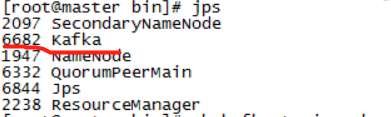
注意:启动kafka之前要先启动zookeeper。分别在master、slave1和slave2节点启动zookeeper
cd /home/hadoop/zookeeper/bin
sh zkServer.sh start
查看zookeeper状态
sh zkServer.sh status
停止命令:
sh zkServer.sh start
10.在master新建立一个TOPIC:在slave1把kafka的生产者启动起来:在slave2把消费者启动起来:
- 切换到kafka的bin目录下面
cd /home/hadoop/kafka/bin
- 在master新建立一个topic,名字是kafkatopic
sh kafka-topics.sh --create --topic kafkatopic --replication-factor 1 --partitions 1 --zookeeper master:2181
11.查看
- 查看master节点创建的topic——kafkatopic
sh kafka-topics.sh --list --zookeeper master:2181
![]()
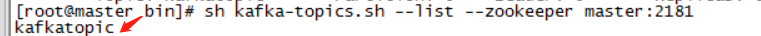
- 描述kafkatopic
sh kafka-topics.sh --describe --zookeeper master:2181 --topic kafkatopic

- 创建slave1生产者: sh kafka-console-producer.sh --broker-list slave1:9092 --topic kafkatopic
- 创建slave2消费者: sh kafka-console-consumer.sh --zookeeper slave2:2181 --topic kafkatopic --from-beginnin
12.测试
- 在生产者输slave1节点输入测试语句 ,每回车一次,消费者就可以接收到传输来的数据

- slave2节点可以接收
