构建自己的yara数据库
之前有看到过关于yara的文章,基本是关于规则怎么写的翻译文章。But…现实分析中我遇到的问题是我懒得自己写yara规则,我的yara规则库数量太少了,开始很多文件无法匹配出结果。yara规则怎么写对我来说暂时用不上,我需要的是能快速建立yara规则库,对于新的恶意软件,最好有工具能够自动帮我分析出样本的yara规则,然后添加到现有的yara规则库中。
解决方案
在网上找到下面几个方案能够帮助解决现有的问题
- Yara官方预置的规则库
- ClamAV的特征码转换为yara规则
- 从yara-generator爬取别人上传的样本的规则
- 利用yara-generator自动生成新的yara规则
解决思路如下
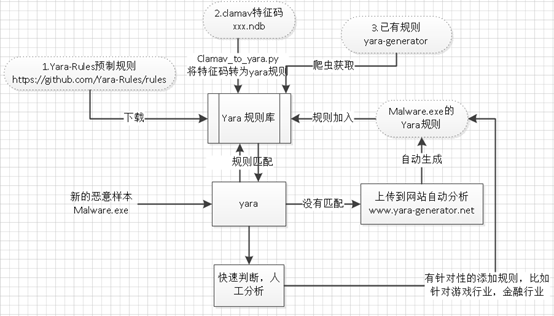
预置规则主要从三方面获取:首先可以从yara官方的预置规则,然后利用工具
clamav_to_yara.py将clamav的特征码转换为yara规则,最后yara-generator上有很多其他用户上传的样本规则,可以使用爬虫去将这些规则爬取到我们是规则库中。
当分析一个样本时,先用yara现有的库进行扫描。如果没有匹配,可以上传到yara-generator网站上自动分析yara规则,再将规则加入到规则库中。对于有针对性的分析某些行业的恶意软件,可以人工分析一些行业的关键字串特征,手动修改yara规则。
获取预置规则
- Yara官方预置规则
Yara规则的官方网站为yararules.com,规则存放在github上github.com/Yara-Rules/rules,规则以yar结尾。
- ClamAV特征码转换为yara规则
Clam AntiVirus(ClamAV)是免费而且开放源代码的防毒软件,软件与病毒码的更新皆由社群免费发布。可以利用clamav_to_yara.py脚本将ClamAV特征码直接转换为yara的规则。主要步骤如下:
- 安装clamAV
Linux下的安装命令apt-get install clamav clamav-freshclam
- 用自带工具解压特征码
默认规则库放在/var/lib/clamav/main.cvd中,使用clamav自带的工具sigtool可以将其解压
命令sigtool -u /var/lib/clamav/main.cvd可以将特征码解压,结果如下
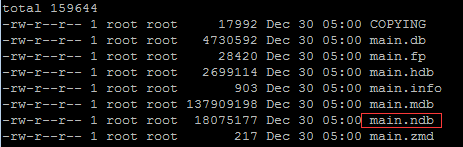
Main.ndb 是下一步的输入文件
- 特征码转换为规则
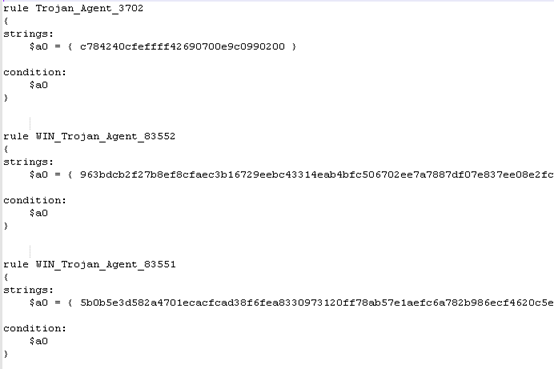
转换命令clamav_to_yara.py -f main.ndb -o clamav.yara -s Agent
转换出来的结果clamav.yara如下所示:
脚本地址:
https://code.google.com/p/malwarecookbook/source/browse/trunk/3/3/clamav_to_yara.py
- 从yara-generator爬取规则
yara-generator(Joe Sandbox公司的)网上可以查看其他用户上传的样本文件生成的规则。其网址为www.yara-generator.net。
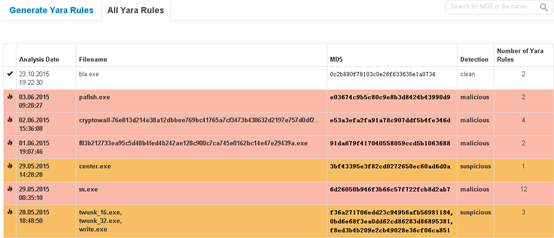
这里可以下载每个样本的yara rule,没有提供所有的打包下载,写个爬虫可以轻易获取所有的rule。
自动解析规则
在不担心样本泄露的情况下,可以将样本上传到www.yara-generator.net进行分析, 完成之后即可下载对应的yara规则,这样就省去了自己编写yara规则的繁重工作了。
当然工具也有遗漏,我们可以在手动分析过程中,将发现的特征编写成规则,加入到文件中。
简单的扫描脚本
使用path可以快速定制一个多对多扫描脚本,代码如下
import yara
import os
import sys
def getRules(path):
filepath = {}
for index,file in enumerate(os.listdir(path)):
rupath = os.path.join(path, file)
key = "rule"+str(index)
filepath[key] = rupath
yararule = yara.compile(filepaths=filepath)
return yararule
def scan(rule, path):
for file in os.listdir(path):
mapath = os.path.join(path, file)
fp = open(mapath, 'rb')
matches = rule.match(data=fp.read())
if len(matches)>0:
print file,matches
if __name__ == '__main__':
rulepath = sys.argv[1]
malpath = sys.argv[2]
yararule = getRules(rulepath)
scan(yararule, malpath)
运行结果如下图所示

newrule文件夹下面存放了yara规则文件, mal1209下面存放了一堆恶意样本。可以自己改写扫描硬盘上的所有文件夹,规则丰富以后,一个简单的全盘查毒软件就完成了。
安装yara之后python可以引入yara模块, import yara
使用yara.compile()可以将对各yara文件编译成一个规则对象,然后用match函数匹配,具体可以查看yara的参考文档。
下面是一个简单的示例
rules = yara.compile(filepaths={
'namespace1':'/my/path/rules1',
'namespace2':'/my/path/rules2' })
f = fopen('/foo/bar/my_file', 'rb')
matches = rules.match(data=f.read())
更多可以挖掘的
Yara是很好的恶意软件分类软件, yara的规则中有很多有用的字符串信息,如一些网址,API等。同时手工分析之后可以将挖掘出的恶意软件特征加入到yara规则中。
累积了较多的规则之后,可以用统计学方法进行挖掘,统计。 如分析有多少恶意软件是针对金融行业的,有多少恶意软件是针对游戏行业的。